Hermosillo-Reynoso Fernando, Torres-Roman Deni
Center for Research and Advanced Studies of the National Polytechnic Institute, Department of Electrical Engineering and Computer Sciences, Telecommunications Section, Av. del Bosque 1145, El Bajio, Zapopan 45019, Jalisco, Mexico.
Sensors (Basel). 2024 Nov 22;24(23):7463. doi: 10.3390/s24237463.
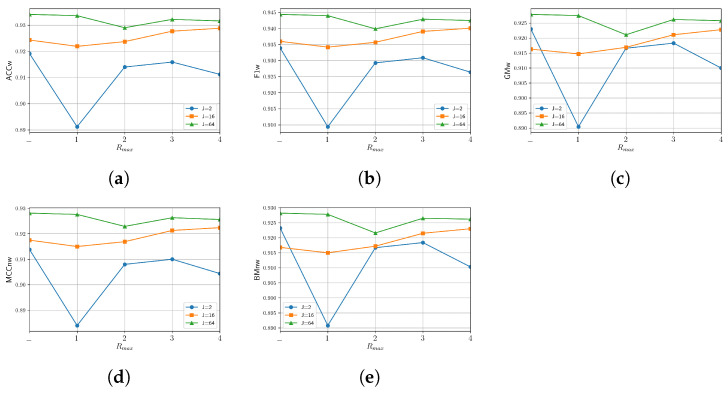
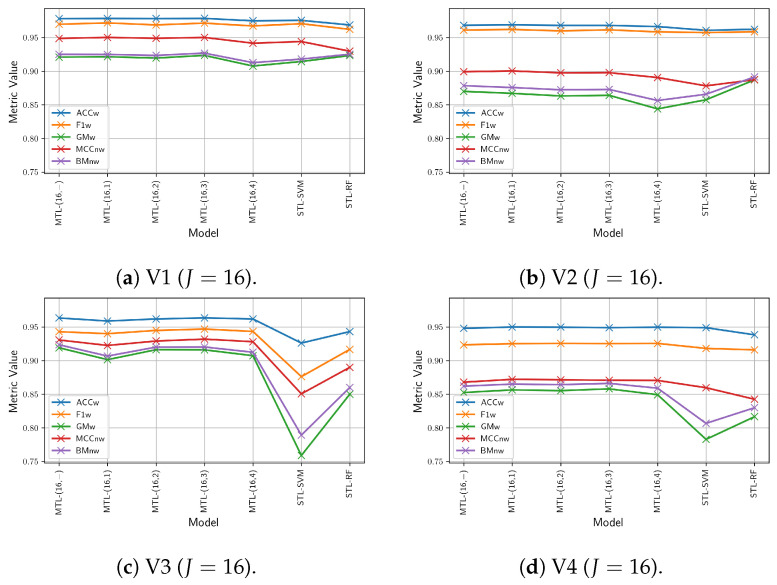
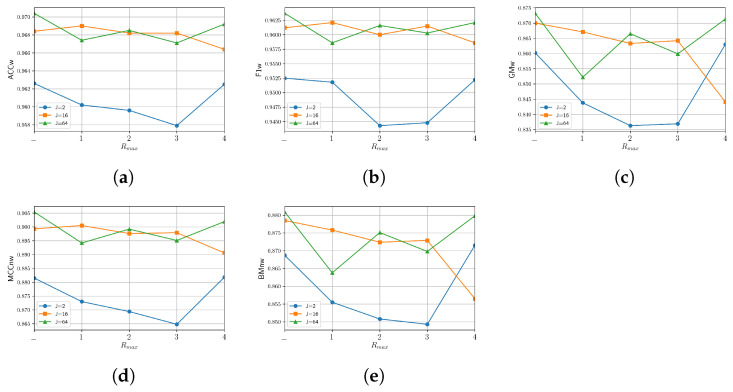
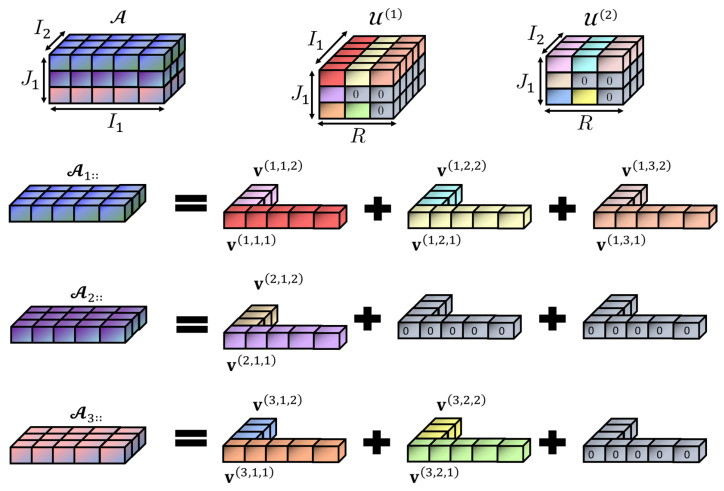
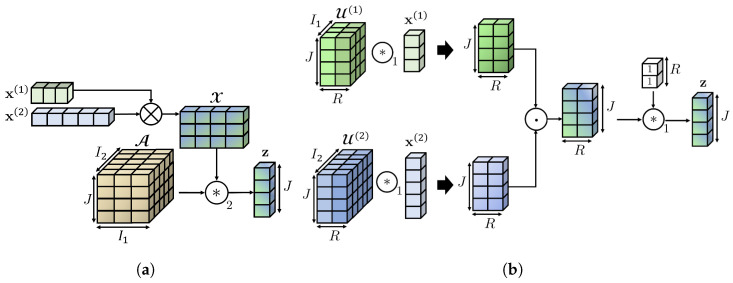
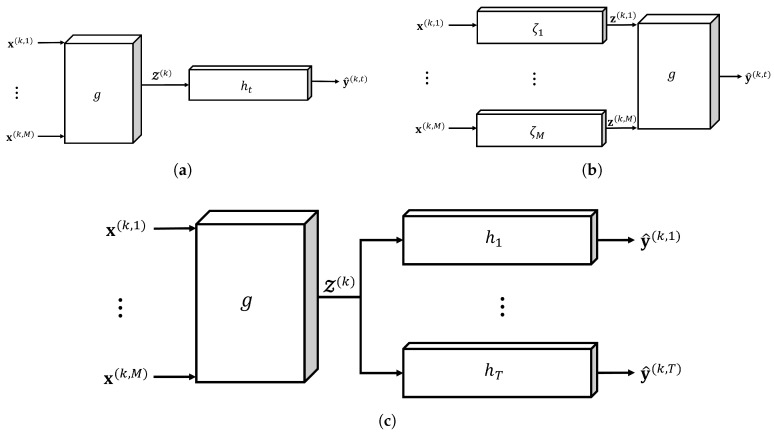
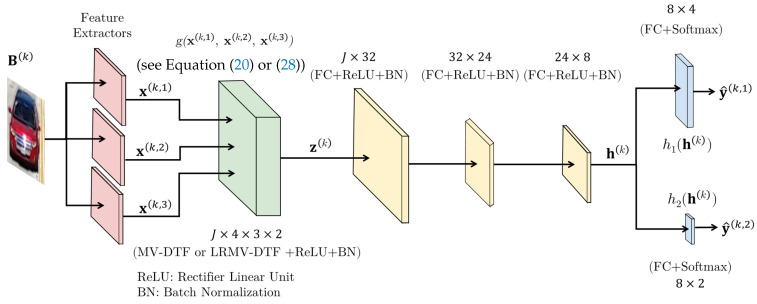
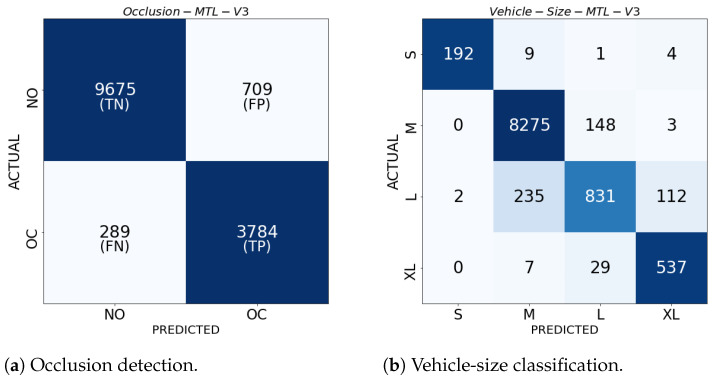
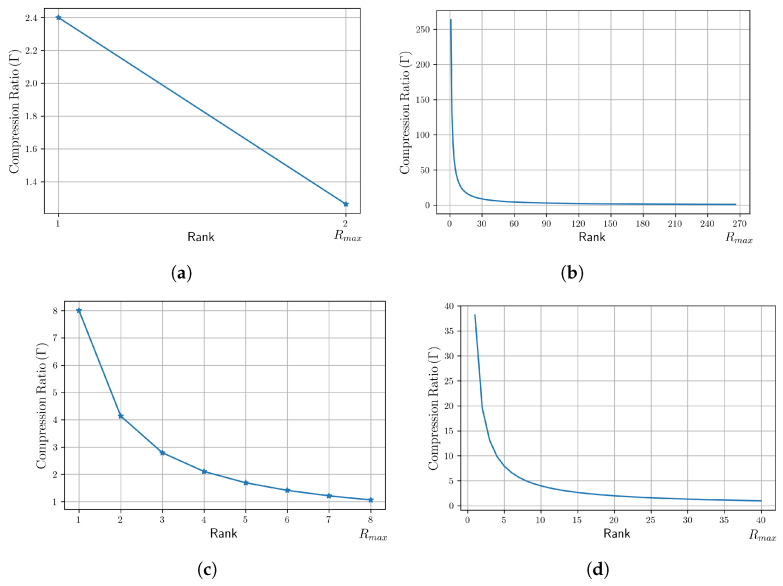
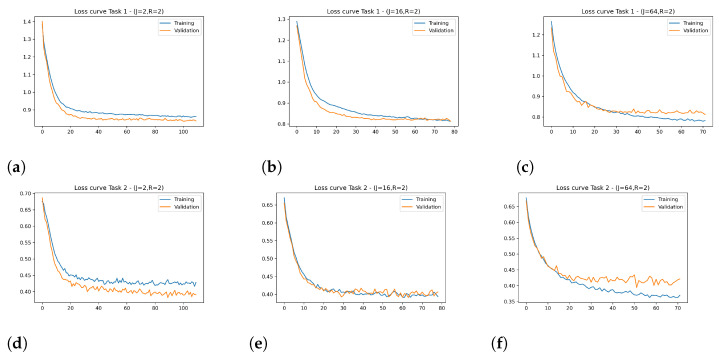
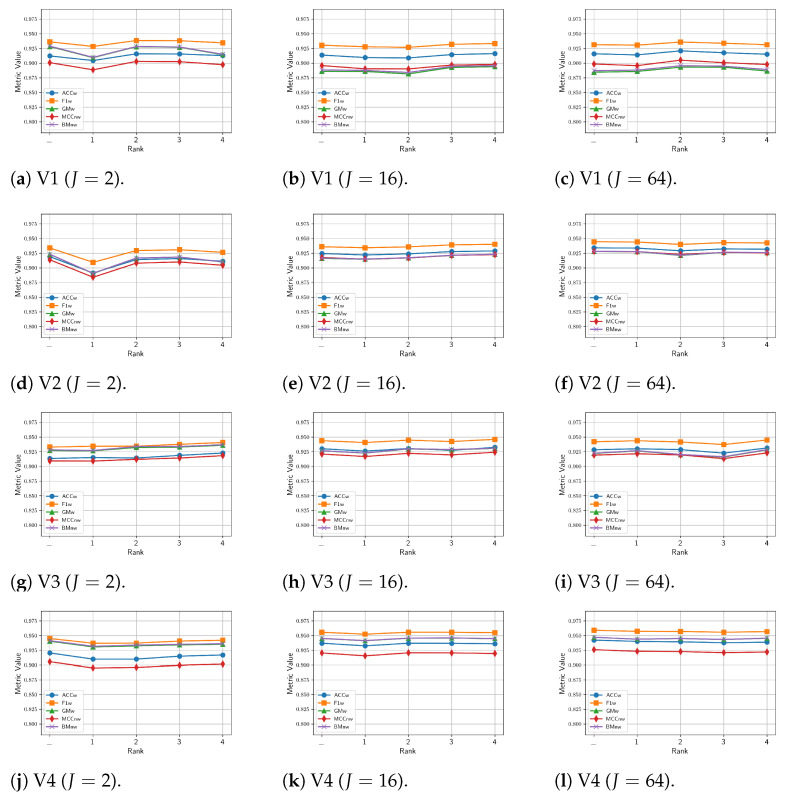
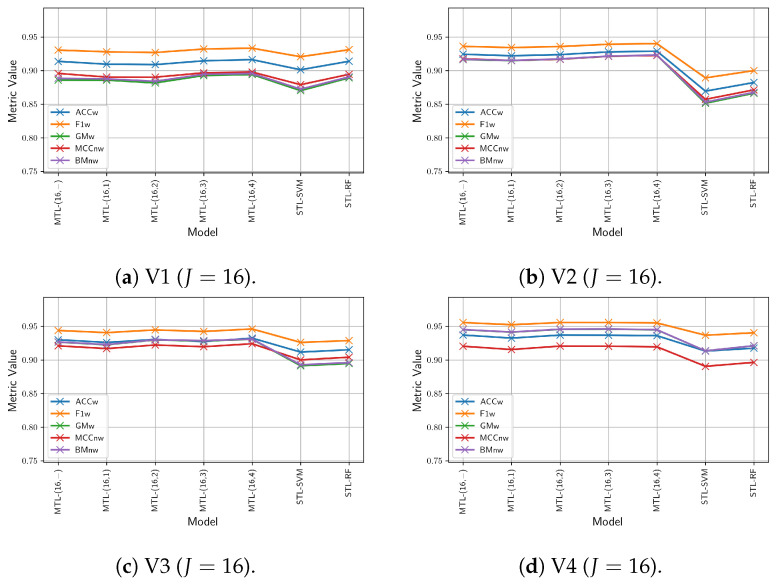
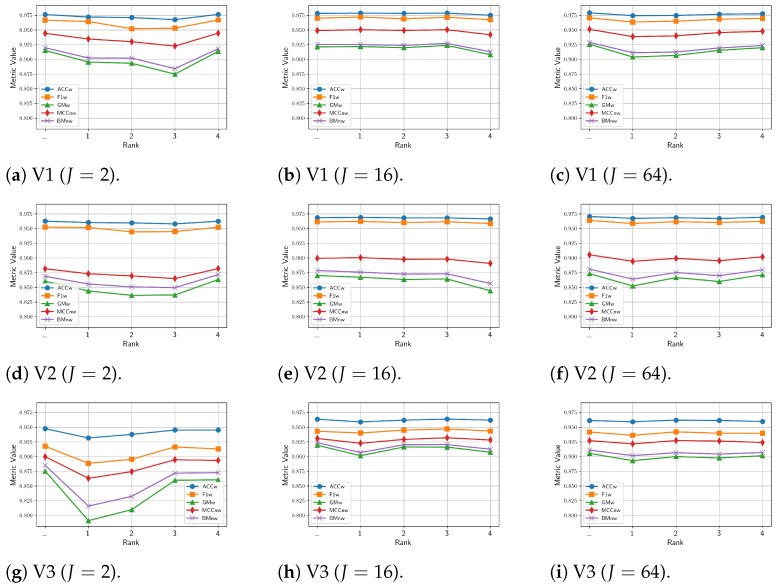
Since multi-view learning leverages complementary information from multiple feature sets to improve model performance, a tensor-based data fusion layer for neural networks, called Multi-View Data Tensor Fusion (MV-DTF), is used. It fuses M feature spaces X1,⋯,XM, referred to as views, in a new latent tensor space, S, of order and dimension J1×⋯×JP, defined in the space of affine mappings composed of a multilinear map T:X1×⋯×XM→S-represented as the Einstein product between a (P+M)-order tensor A anda rank-one tensor, X=x(1)⊗⋯⊗x(M), where x(m)∈Xm is the -th view-and a translation. Unfortunately, as the number of views increases, the number of parameters that determine the MV-DTF layer grows exponentially, and consequently, so does its computational complexity. To address this issue, we enforce low-rank constraints on certain subtensors of tensor A using canonical polyadic decomposition, from which other tensors U(1),⋯,U(M), called here Hadamard factor tensors, are obtained. We found that the Einstein product A⊛MX can be approximated using a sum of Hadamard products of Einstein products encoded as U(m)⊛1x(m), where is related to the decomposition rank of subtensors of A. For this relationship, the lower the rank values, the more computationally efficient the approximation. To the best of our knowledge, this relationship has not previously been reported in the literature. As a case study, we present a multitask model of vehicle traffic surveillance for occlusion detection and vehicle-size classification tasks, with a low-rank MV-DTF layer, achieving up to 92.81% and 95.10% in the normalized weighted Matthews correlation coefficient metric in individual tasks, representing a significant 6% and 7% improvement compared to the single-task single-view models.
由于多视图学习利用多个特征集的互补信息来提高模型性能,因此使用了一种用于神经网络的基于张量的数据融合层,称为多视图数据张量融合(MV-DTF)。它在一个新的潜在张量空间(S)中融合(M)个特征空间(X_1,\cdots,X_M)(称为视图),该空间的阶数为(P),维度为(J_1\times\cdots\times J_P),定义在由多线性映射(T:X_1\times\cdots\times X_M\rightarrow S)组成的仿射映射空间中,该映射表示为一个((P + M))阶张量(A)与一个秩一张量(X = x^{(1)}\otimes\cdots\otimes x^{(M)})之间的爱因斯坦积,其中(x^{(m)}\in X_m)是第(m)个视图,并且还有一个平移。不幸的是,随着视图数量的增加,确定MV-DTF层的参数数量呈指数增长,因此其计算复杂度也随之增加。为了解决这个问题,我们使用典范多adic分解对张量(A)的某些子张量施加低秩约束,从中获得其他张量(U^{(1)},\cdots,U^{(M)}),这里称为哈达玛因子张量。我们发现爱因斯坦积(A\circledast_M X)可以使用编码为(U^{(m)}\circledast_1 x^{(m)})的爱因斯坦积的哈达玛积之和来近似,其中(r)与(A)的子张量的分解秩有关。对于这种关系,秩值越低,近似的计算效率越高。据我们所知,这种关系以前在文献中尚未报道。作为一个案例研究,我们提出了一个用于遮挡检测和车辆尺寸分类任务的车辆交通监控多任务模型,该模型具有低秩MV-DTF层,在各个任务的归一化加权马修斯相关系数度量中分别达到了(92.81%)和(95.10%),与单任务单视图模型相比,分别有显著的(6%)和(7%)的提升。