Department of Radiation Oncology, Cantonal Hospital of St. Gallen, St. Gallen, Switzerland.
Department of Radiation Oncology, Inselspital, Bern University Hospital and University of Bern, Bern, Switzerland.
Syst Rev. 2024 Jun 15;13(1):158. doi: 10.1186/s13643-024-02575-4.
Systematically screening published literature to determine the relevant publications to synthesize in a review is a time-consuming and difficult task. Large language models (LLMs) are an emerging technology with promising capabilities for the automation of language-related tasks that may be useful for such a purpose.
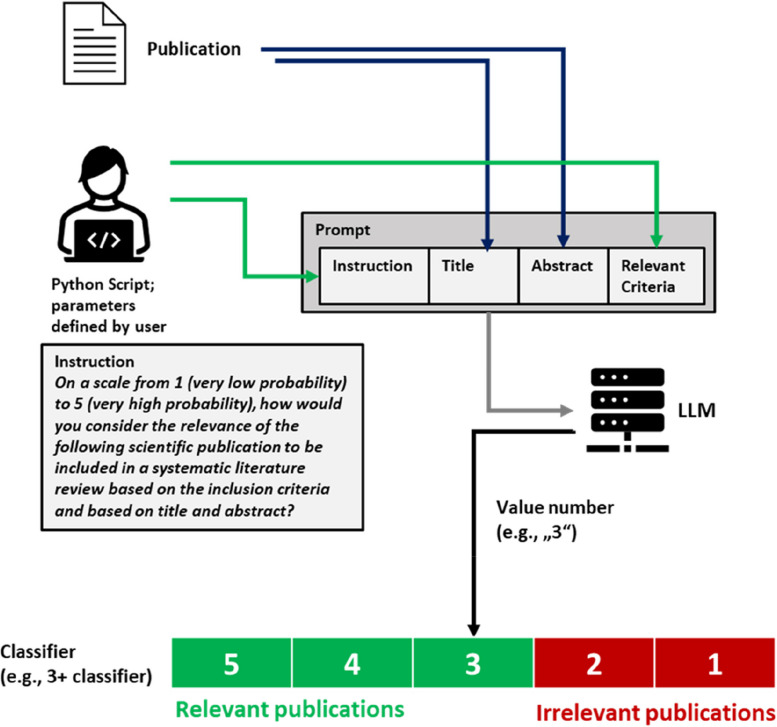
LLMs were used as part of an automated system to evaluate the relevance of publications to a certain topic based on defined criteria and based on the title and abstract of each publication. A Python script was created to generate structured prompts consisting of text strings for instruction, title, abstract, and relevant criteria to be provided to an LLM. The relevance of a publication was evaluated by the LLM on a Likert scale (low relevance to high relevance). By specifying a threshold, different classifiers for inclusion/exclusion of publications could then be defined. The approach was used with four different openly available LLMs on ten published data sets of biomedical literature reviews and on a newly human-created data set for a hypothetical new systematic literature review.
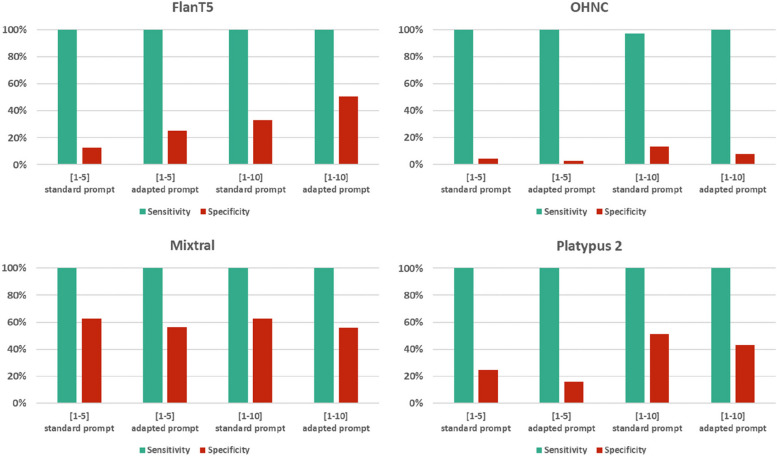
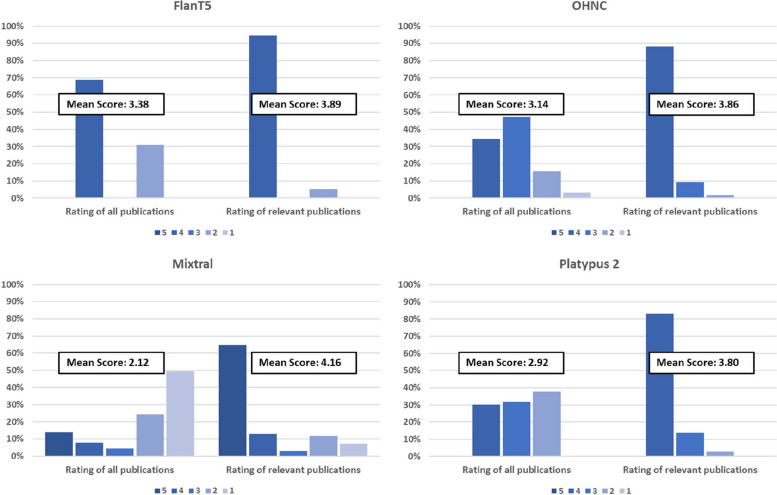
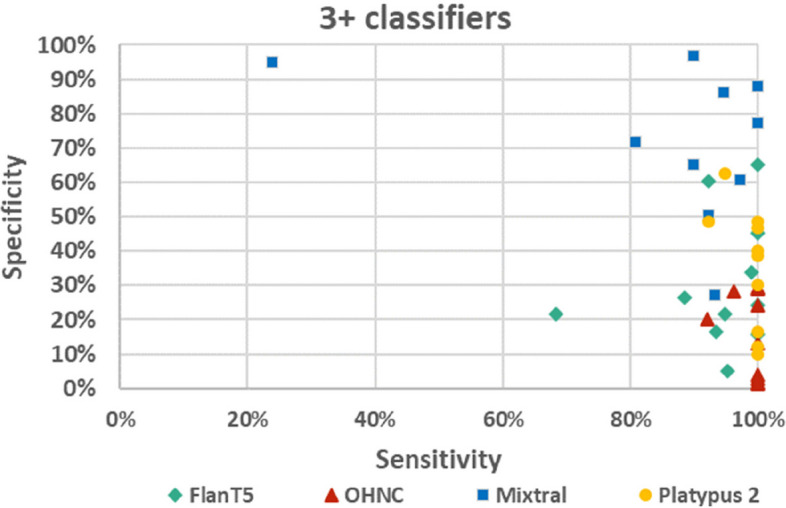
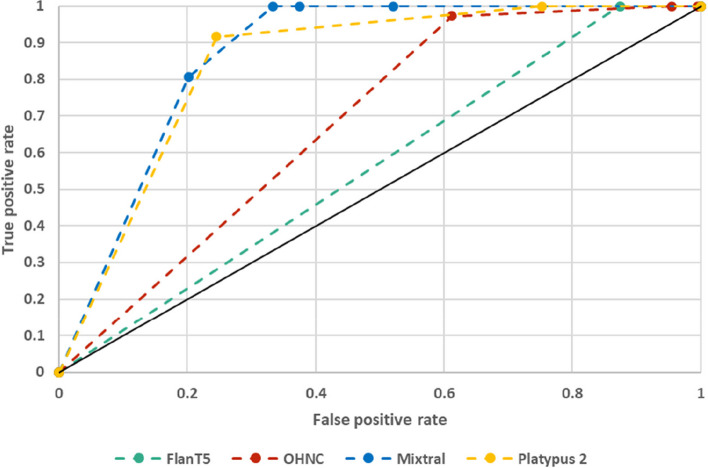
The performance of the classifiers varied depending on the LLM being used and on the data set analyzed. Regarding sensitivity/specificity, the classifiers yielded 94.48%/31.78% for the FlanT5 model, 97.58%/19.12% for the OpenHermes-NeuralChat model, 81.93%/75.19% for the Mixtral model and 97.58%/38.34% for the Platypus 2 model on the ten published data sets. The same classifiers yielded 100% sensitivity at a specificity of 12.58%, 4.54%, 62.47%, and 24.74% on the newly created data set. Changing the standard settings of the approach (minor adaption of instruction prompt and/or changing the range of the Likert scale from 1-5 to 1-10) had a considerable impact on the performance.
LLMs can be used to evaluate the relevance of scientific publications to a certain review topic and classifiers based on such an approach show some promising results. To date, little is known about how well such systems would perform if used prospectively when conducting systematic literature reviews and what further implications this might have. However, it is likely that in the future researchers will increasingly use LLMs for evaluating and classifying scientific publications.
系统地筛选已发表的文献以确定与综述相关的出版物是一项耗时且困难的任务。大型语言模型(LLM)是一种新兴技术,具有自动化语言相关任务的潜力,这可能对该目的有用。
LLM 被用作自动化系统的一部分,根据定义的标准,基于每个出版物的标题和摘要,评估出版物与某个主题的相关性。创建了一个 Python 脚本,用于生成由指令、标题、摘要和要提供给 LLM 的相关标准组成的结构化提示。LLM 根据李克特量表(低相关性到高相关性)评估出版物的相关性。通过指定一个阈值,可以为出版物的纳入/排除定义不同的分类器。该方法在四个不同的公开可用的 LLM 上用于十个生物医学文献综述的已发表数据集,以及一个新的人类创建的数据集,用于假设的新系统文献综述。
分类器的性能取决于所使用的 LLM 和分析的数据集。关于敏感性/特异性,在十个已发表的数据集中,FlanT5 模型的分类器产生了 94.48%/31.78%,OpenHermes-NeuralChat 模型的分类器产生了 97.58%/19.12%,Mixtral 模型的分类器产生了 81.93%/75.19%,Platypus 2 模型的分类器产生了 97.58%/38.34%。在新创建的数据集中,相同的分类器在特异性为 12.58%、4.54%、62.47%和 24.74%时产生了 100%的敏感性。改变该方法的标准设置(指令提示的轻微调整和/或将李克特量表的范围从 1-5 更改为 1-10)对性能有很大影响。
LLM 可用于评估科学出版物与特定综述主题的相关性,基于此类方法的分类器显示出一些有希望的结果。迄今为止,人们对这种系统在进行系统文献综述时如果前瞻性地使用会表现如何知之甚少,以及这可能会有什么进一步的影响。然而,未来研究人员很可能会越来越多地使用 LLM 来评估和分类科学出版物。