Sun Di, Hadjiiski Lubomir, Gormley John, Chan Heang-Ping, Caoili Elaine, Cohan Richard, Alva Ajjai, Bruno Grace, Mihalcea Rada, Zhou Chuan, Gulani Vikas
Department of Radiology, University of Michigan, Ann Arbor, MI 48109, USA.
Department of Internal Medicine-Hematology/Oncology, University of Michigan, Ann Arbor, MI 48109, USA.
Cancers (Basel). 2024 Jun 29;16(13):2402. doi: 10.3390/cancers16132402.
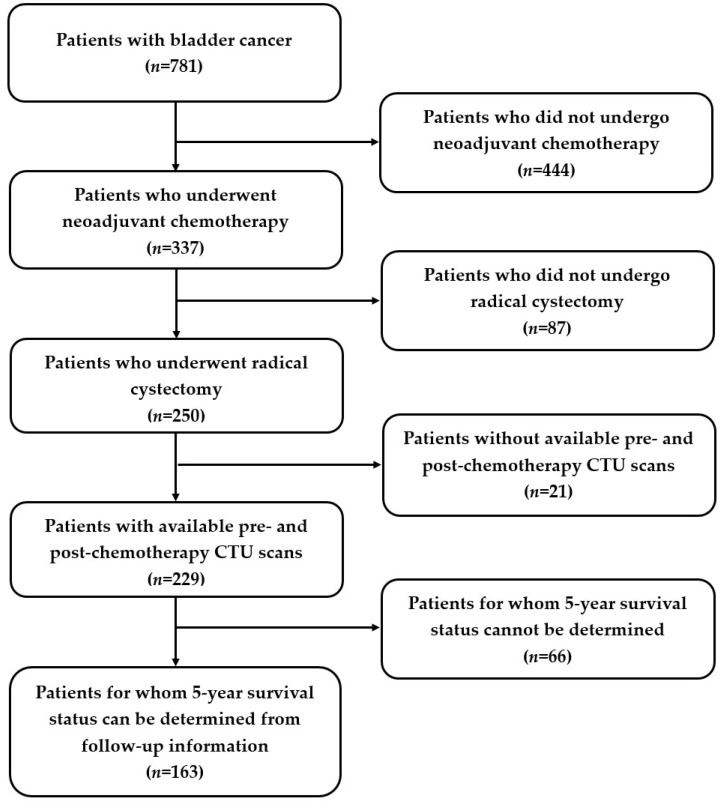
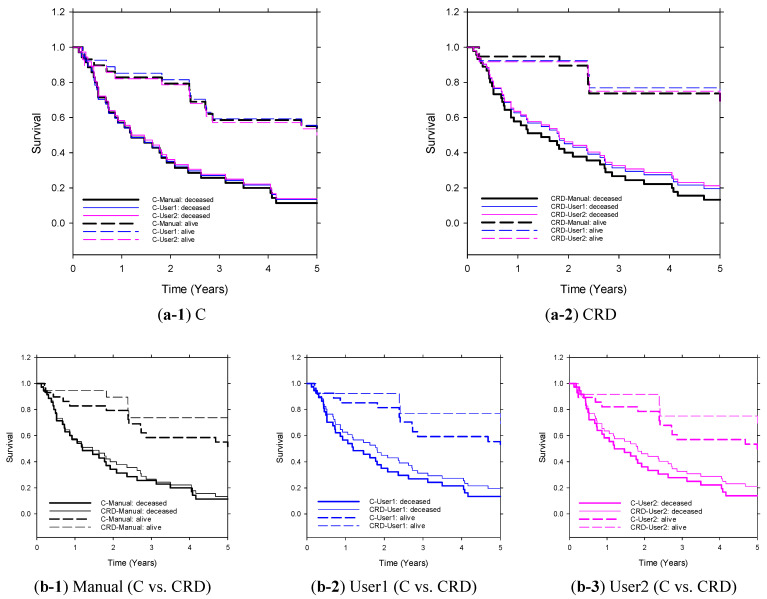
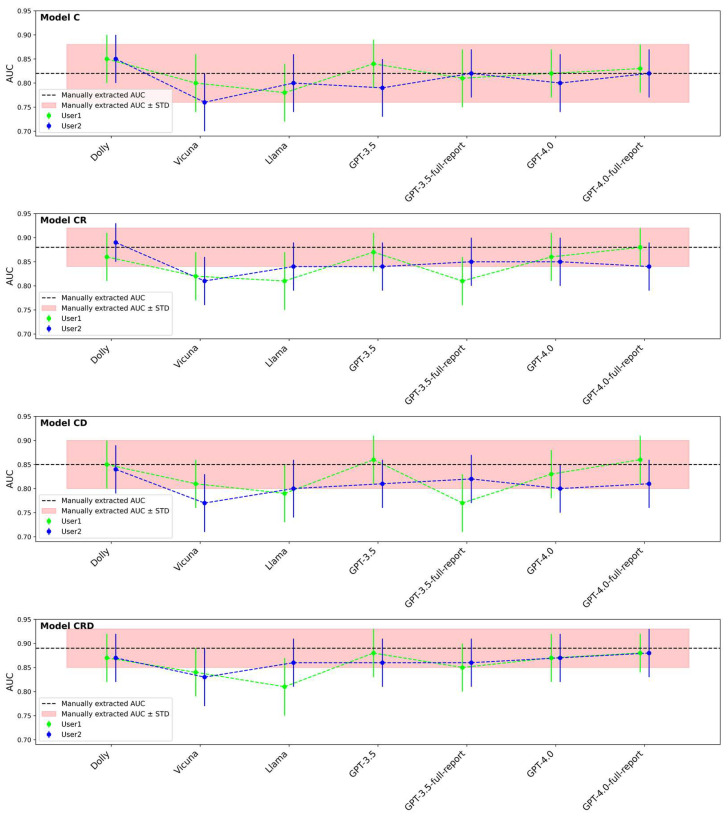
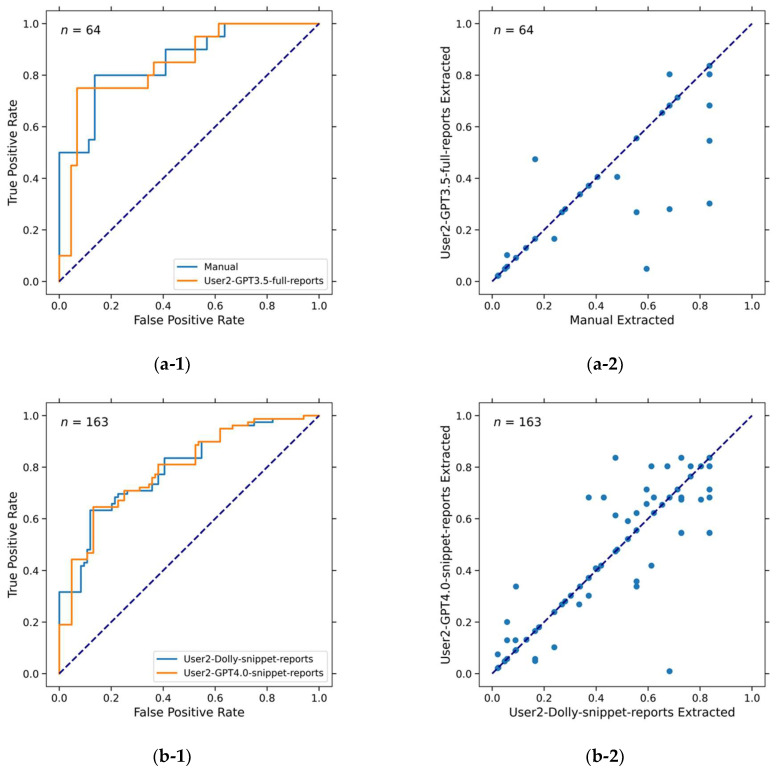
Survival prediction post-cystectomy is essential for the follow-up care of bladder cancer patients. This study aimed to evaluate artificial intelligence (AI)-large language models (LLMs) for extracting clinical information and improving image analysis, with an initial application involving predicting five-year survival rates of patients after radical cystectomy for bladder cancer. Data were retrospectively collected from medical records and CT urograms (CTUs) of bladder cancer patients between 2001 and 2020. Of 781 patients, 163 underwent chemotherapy, had pre- and post-chemotherapy CTUs, underwent radical cystectomy, and had an available post-surgery five-year survival follow-up. Five AI-LLMs (Dolly-v2, Vicuna-13b, Llama-2.0-13b, GPT-3.5, and GPT-4.0) were used to extract clinical descriptors from each patient's medical records. As a reference standard, clinical descriptors were also extracted manually. Radiomics and deep learning descriptors were extracted from CTU images. The developed multi-modal predictive model, CRD, was based on the clinical (C), radiomics (R), and deep learning (D) descriptors. The LLM retrieval accuracy was assessed. The performances of the survival predictive models were evaluated using AUC and Kaplan-Meier analysis. For the 163 patients (mean age 64 ± 9 years; M:F 131:32), the LLMs achieved extraction accuracies of 74%87% (Dolly), 76%83% (Vicuna), 82%93% (Llama), 85%91% (GPT-3.5), and 94%97% (GPT-4.0). For a test dataset of 64 patients, the CRD model achieved AUCs of 0.89 ± 0.04 (manually extracted information), 0.87 ± 0.05 (Dolly), 0.83 ± 0.060.84 ± 0.05 (Vicuna), 0.81 ± 0.060.86 ± 0.05 (Llama), 0.85 ± 0.050.88 ± 0.05 (GPT-3.5), and 0.87 ± 0.05~0.88 ± 0.05 (GPT-4.0). This study demonstrates the use of LLM model-extracted clinical information, in conjunction with imaging analysis, to improve the prediction of clinical outcomes, with bladder cancer as an initial example.
膀胱切除术后的生存预测对于膀胱癌患者的后续护理至关重要。本研究旨在评估人工智能(AI)大语言模型(LLMs)提取临床信息和改善图像分析的能力,首次应用是预测膀胱癌根治性膀胱切除术后患者的五年生存率。数据从2001年至2020年膀胱癌患者的病历和CT尿路造影(CTU)中回顾性收集。在781例患者中,163例接受了化疗,有化疗前后的CTU,接受了根治性膀胱切除术,且有术后五年生存随访数据。使用五个AI-LLMs(Dolly-v2、Vicuna-13b、Llama-2.0-13b、GPT-3.5和GPT-4.0)从每位患者的病历中提取临床描述符。作为参考标准,临床描述符也通过手动提取。从CTU图像中提取影像组学和深度学习描述符。所开发的多模态预测模型CRD基于临床(C)、影像组学(R)和深度学习(D)描述符。评估了LLM检索准确性。使用AUC和Kaplan-Meier分析评估生存预测模型的性能。对于163例患者(平均年龄64±9岁;男:女为131:32),LLMs的提取准确率为74%87%(Dolly)、76%83%(Vicuna)、82%93%(Llama)、85%91%(GPT-3.5)和94%97%(GPT-4.0)。对于64例患者的测试数据集,CRD模型的AUC分别为0.89±0.04(手动提取信息)、0.87±0.05(Dolly)、0.83±0.060.84±0.05(Vicuna)、0.81±0.060.86±0.05(Llama)、0.85±0.050.88±0.05(GPT-3.5)和0.87±0.05~0.88±0.05(GPT-4.0)。本研究展示了使用LLM模型提取的临床信息,结合影像分析,以改善临床结局的预测,以膀胱癌作为首个实例。