Fan Xiaojuan, Chang Tiangen, Chen Chuyun, Hafner Markus, Wang Zefeng
Bio-med Big Data Center, CAS Key Laboratory of Computational Biology, CAS Center for Excellence in Molecular Cell Science, Shanghai Institute of Nutrition and Health.
RNA Molecular Biology Laboratory, National Institute of Arthritis and Musculoskeletal and Skin Disease, Bethesda, MD, USA.
bioRxiv. 2024 Jul 2:2023.07.08.548206. doi: 10.1101/2023.07.08.548206.
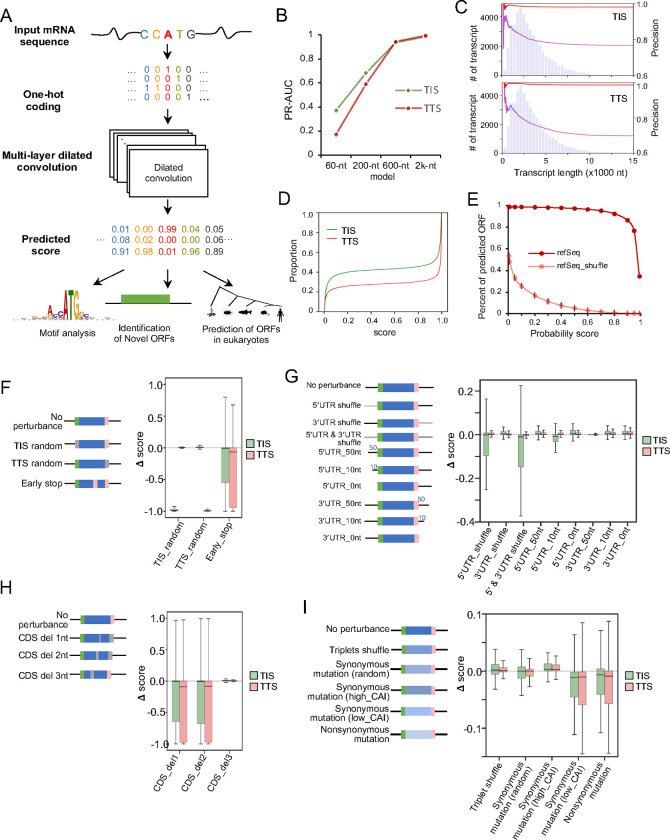
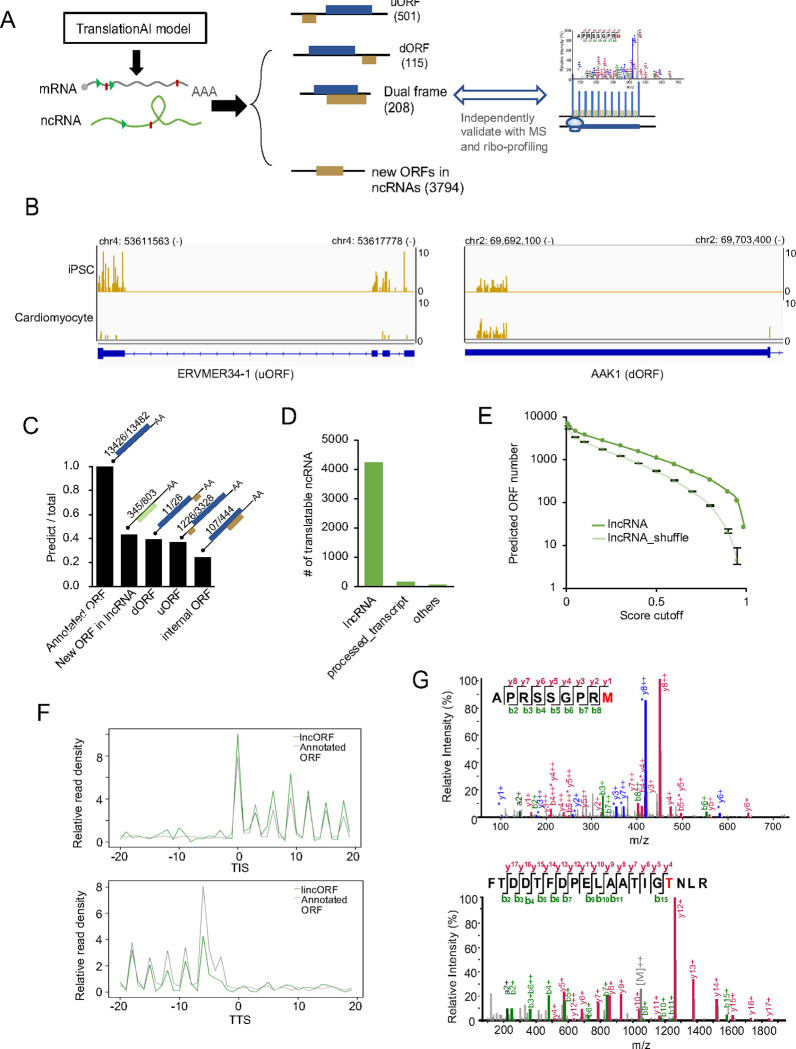
Accurate annotation of coding regions in RNAs is essential for understanding gene translation. We developed a deep neural network to directly predict and analyze translation initiation and termination sites from RNA sequences. Trained with human transcripts, our model learned hidden rules of translation control and achieved a near perfect prediction of canonical translation sites across entire human transcriptome. Surprisingly, this model revealed a new role of codon usage in regulating translation termination, which was experimentally validated. We also identified thousands of new open reading frames in mRNAs or lncRNAs, some of which were confirmed experimentally. The model trained with human mRNAs achieved high prediction accuracy of canonical translation sites in all eukaryotes and good prediction in polycistronic transcripts from prokaryotes or RNA viruses, suggesting a high degree of conservation in translation control. Collectively, we present a general and efficient deep learning model for RNA translation, generating new insights into the complexity of translation regulation.
准确注释RNA中的编码区域对于理解基因翻译至关重要。我们开发了一种深度神经网络,用于直接从RNA序列预测和分析翻译起始和终止位点。通过人类转录本进行训练,我们的模型学习到了翻译控制的隐藏规则,并在整个人类转录组中对规范翻译位点实现了近乎完美的预测。令人惊讶的是,该模型揭示了密码子使用在调节翻译终止中的新作用,这一点已通过实验得到验证。我们还在mRNA或lncRNA中鉴定出数千个新的开放阅读框,其中一些已通过实验得到证实。用人类mRNA训练的模型在所有真核生物中对规范翻译位点都具有很高的预测准确性,并且对来自原核生物或RNA病毒的多顺反子转录本也有良好的预测,这表明翻译控制具有高度的保守性。总体而言,我们提出了一种通用且高效的用于RNA翻译的深度学习模型,为翻译调控的复杂性提供了新的见解。