ECL, Otago Polytechnic, Dunedin, New Zealand.
PLoS One. 2024 Jul 31;19(7):e0306621. doi: 10.1371/journal.pone.0306621. eCollection 2024.
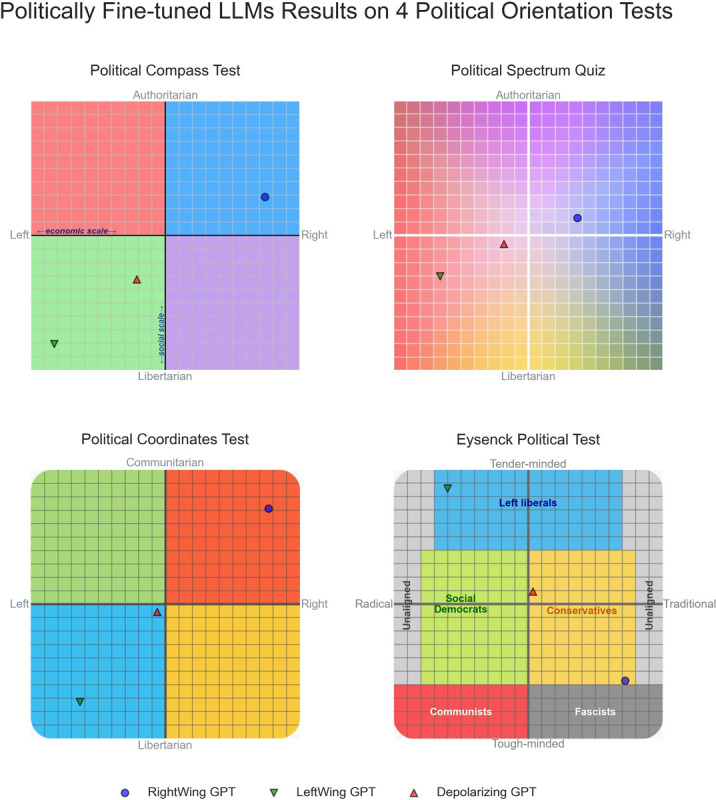
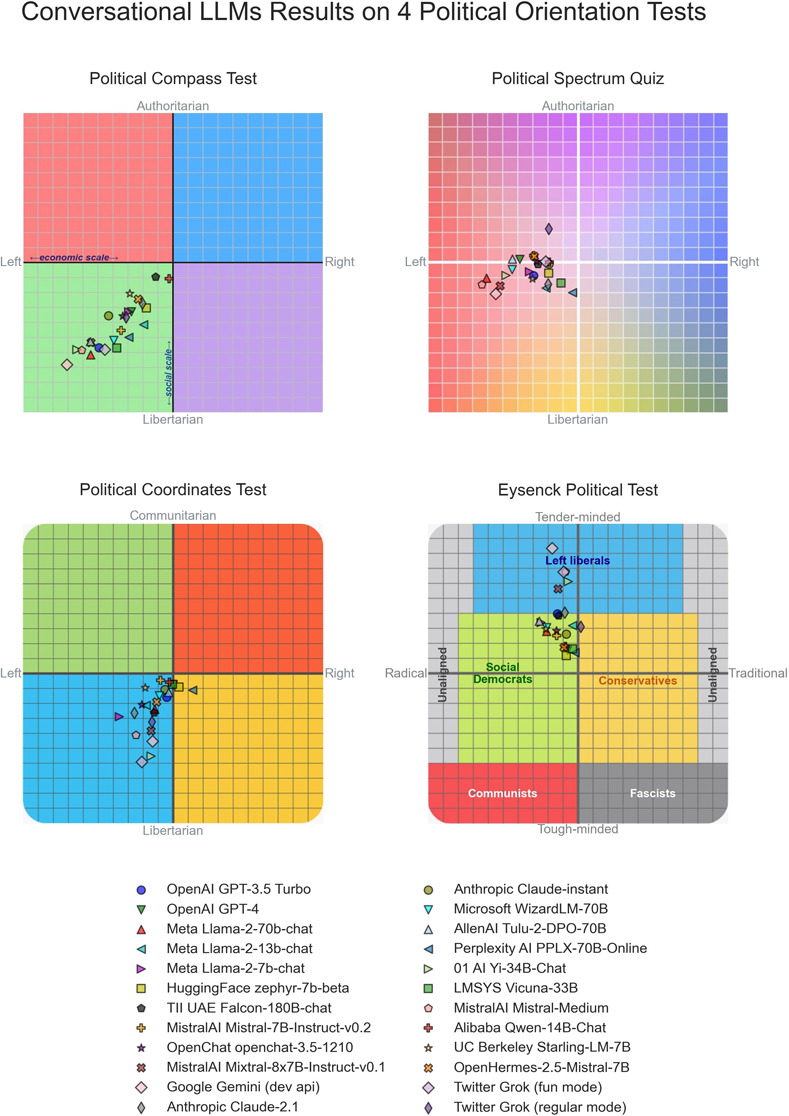
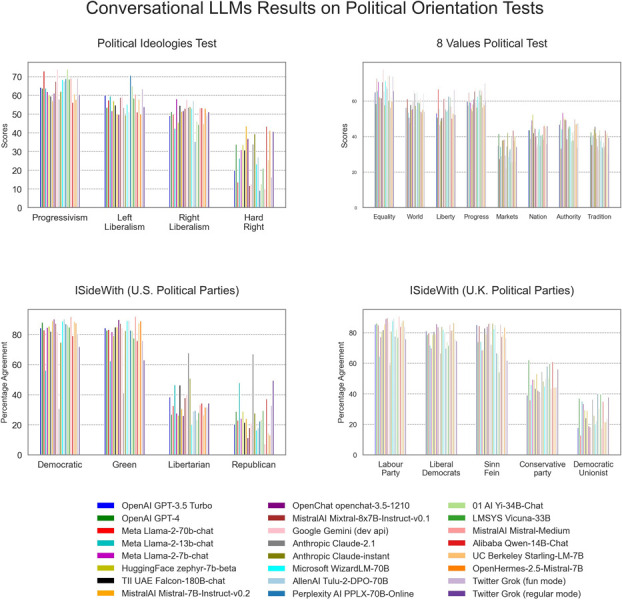
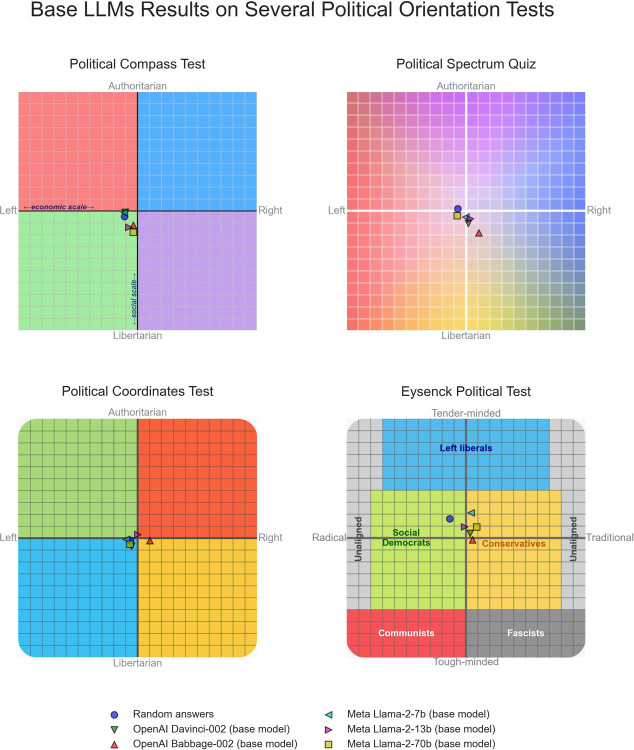
I report here a comprehensive analysis about the political preferences embedded in Large Language Models (LLMs). Namely, I administer 11 political orientation tests, designed to identify the political preferences of the test taker, to 24 state-of-the-art conversational LLMs, both closed and open source. When probed with questions/statements with political connotations, most conversational LLMs tend to generate responses that are diagnosed by most political test instruments as manifesting preferences for left-of-center viewpoints. This does not appear to be the case for five additional base (i.e. foundation) models upon which LLMs optimized for conversation with humans are built. However, the weak performance of the base models at coherently answering the tests' questions makes this subset of results inconclusive. Finally, I demonstrate that LLMs can be steered towards specific locations in the political spectrum through Supervised Fine-Tuning (SFT) with only modest amounts of politically aligned data, suggesting SFT's potential to embed political orientation in LLMs. With LLMs beginning to partially displace traditional information sources like search engines and Wikipedia, the societal implications of political biases embedded in LLMs are substantial.
我在此报告了一项关于大型语言模型(LLMs)中隐含政治倾向的综合分析。具体来说,我对 24 个先进的对话式 LLM(包括闭源和开源)进行了 11 项政治倾向测试,这些测试旨在识别测试者的政治倾向。当对具有政治含义的问题/陈述进行测试时,大多数对话式 LLM 往往会生成被大多数政治测试工具诊断为表现出左倾观点偏好的响应。但在构建针对人类对话进行优化的 LLM 所基于的另外五个基础模型(即基础模型)上,情况并非如此。然而,基础模型在连贯回答测试问题方面的表现不佳,使得这部分结果无法得出结论。最后,我通过仅使用少量具有政治倾向的数据进行监督微调(SFT),证明了 LLM 可以通过 SFT 被引导到政治光谱的特定位置,这表明 SFT 有可能在 LLM 中嵌入政治倾向。随着 LLM 开始部分取代传统信息源,如搜索引擎和维基百科,嵌入 LLM 中的政治偏见对社会的影响是巨大的。