Division of Biostatistics, University of California Berkeley School of Public Health, Berkeley, CA, United States.
Department of Anesthesia and Perioperative Care, University of California San Francisco, San Francisco, CA, United States.
JMIR Public Health Surveill. 2024 Aug 15;10:e53322. doi: 10.2196/53322.
Postacute sequelae of COVID-19 (PASC), also known as long COVID, is a broad grouping of a range of long-term symptoms following acute COVID-19. These symptoms can occur across a range of biological systems, leading to challenges in determining risk factors for PASC and the causal etiology of this disorder. An understanding of characteristics that are predictive of future PASC is valuable, as this can inform the identification of high-risk individuals and future preventative efforts. However, current knowledge regarding PASC risk factors is limited.
Using a sample of 55,257 patients (at a ratio of 1 patient with PASC to 4 matched controls) from the National COVID Cohort Collaborative, as part of the National Institutes of Health Long COVID Computational Challenge, we sought to predict individual risk of PASC diagnosis from a curated set of clinically informed covariates. The National COVID Cohort Collaborative includes electronic health records for more than 22 million patients from 84 sites across the United States.
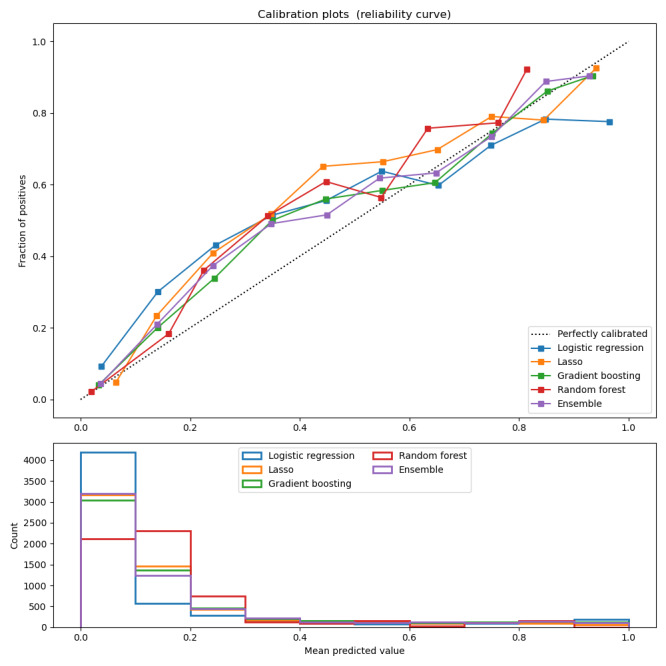
We predicted individual PASC status, given covariate information, using Super Learner (an ensemble machine learning algorithm also known as stacking) to learn the optimal combination of gradient boosting and random forest algorithms to maximize the area under the receiver operator curve. We evaluated variable importance (Shapley values) based on 3 levels: individual features, temporal windows, and clinical domains. We externally validated these findings using a holdout set of randomly selected study sites.
We were able to predict individual PASC diagnoses accurately (area under the curve 0.874). The individual features of the length of observation period, number of health care interactions during acute COVID-19, and viral lower respiratory infection were the most predictive of subsequent PASC diagnosis. Temporally, we found that baseline characteristics were the most predictive of future PASC diagnosis, compared with characteristics immediately before, during, or after acute COVID-19. We found that the clinical domains of health care use, demographics or anthropometry, and respiratory factors were the most predictive of PASC diagnosis.
The methods outlined here provide an open-source, applied example of using Super Learner to predict PASC status using electronic health record data, which can be replicated across a variety of settings. Across individual predictors and clinical domains, we consistently found that factors related to health care use were the strongest predictors of PASC diagnosis. This indicates that any observational studies using PASC diagnosis as a primary outcome must rigorously account for heterogeneous health care use. Our temporal findings support the hypothesis that clinicians may be able to accurately assess the risk of PASC in patients before acute COVID-19 diagnosis, which could improve early interventions and preventive care. Our findings also highlight the importance of respiratory characteristics in PASC risk assessment.
INTERNATIONAL REGISTERED REPORT IDENTIFIER (IRRID): RR2-10.1101/2023.07.27.23293272.
新冠病毒疾病(COVID-19)的急性后遗症(PASC),也称为长新冠,是一系列在急性 COVID-19 后出现的长期症状的统称。这些症状可能发生在一系列生物系统中,这导致确定 PASC 的危险因素以及该疾病的因果病因具有挑战性。了解预测未来 PASC 的特征是有价值的,因为这可以为确定高危人群和未来的预防措施提供信息。然而,目前关于 PASC 危险因素的知识有限。
利用来自美国 84 个地点的超过 2200 万名患者的国家 COVID 队列协作(National COVID Cohort Collaborative)中的 55257 名患者(急性 COVID-19 患者与 4 名匹配对照患者的比例为 1:4)作为 NIH 长新冠计算挑战的一部分,我们试图从一组精心挑选的临床相关协变量中预测个体发生 PASC 的风险。国家 COVID 队列协作包括来自美国 84 个地点的超过 2200 万名患者的电子健康记录。
我们使用 Super Learner(一种也称为堆叠的集成机器学习算法)来预测给定协变量信息的个体 PASC 状态,以学习最佳的梯度提升和随机森林算法组合,从而最大化接收者操作特征曲线下的面积。我们基于三个级别评估了变量的重要性(Shapley 值):单个特征、时间窗口和临床领域。我们使用随机选择的研究地点的保留集来外部验证这些发现。
我们能够准确地预测个体 PASC 诊断(曲线下面积 0.874)。观察期长度、急性 COVID-19 期间的医疗保健交互次数和病毒下呼吸道感染等个体特征是预测随后发生 PASC 的最具预测性的因素。从时间上看,我们发现与急性 COVID-19 之前、期间或之后的特征相比,基线特征对未来 PASC 诊断的预测性最强。我们发现,医疗保健使用、人口统计学或人体测量学和呼吸因素等临床领域是预测 PASC 诊断的最具预测性的因素。
此处概述的方法提供了使用电子健康记录数据使用 Super Learner 预测 PASC 状态的开源应用示例,该方法可在各种环境中复制。在个体预测因子和临床领域中,我们一致发现与医疗保健使用相关的因素是 PASC 诊断的最强预测因子。这表明,任何使用 PASC 诊断作为主要结局的观察性研究都必须严格考虑异质的医疗保健使用。我们的时间发现支持这样一种假设,即临床医生可能能够在急性 COVID-19 诊断之前准确评估 PASC 的风险,这可以改善早期干预和预防保健。我们的研究结果还强调了呼吸特征在 PASC 风险评估中的重要性。
国际注册报告标识符(IRRID):RR2-10.1101/2023.07.27.23293272。