Department of Medicine, UNC Chapel Hill School of Medicine, Chapel Hill, NC, USA.
Palantir Technologies, Denver, CO, USA.
Lancet Digit Health. 2022 Jul;4(7):e532-e541. doi: 10.1016/S2589-7500(22)00048-6. Epub 2022 May 16.
Post-acute sequelae of SARS-CoV-2 infection, known as long COVID, have severely affected recovery from the COVID-19 pandemic for patients and society alike. Long COVID is characterised by evolving, heterogeneous symptoms, making it challenging to derive an unambiguous definition. Studies of electronic health records are a crucial element of the US National Institutes of Health's RECOVER Initiative, which is addressing the urgent need to understand long COVID, identify treatments, and accurately identify who has it-the latter is the aim of this study.
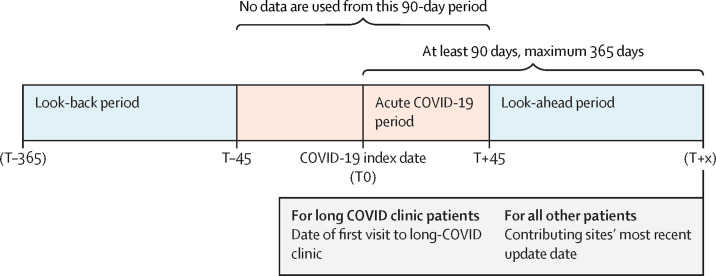
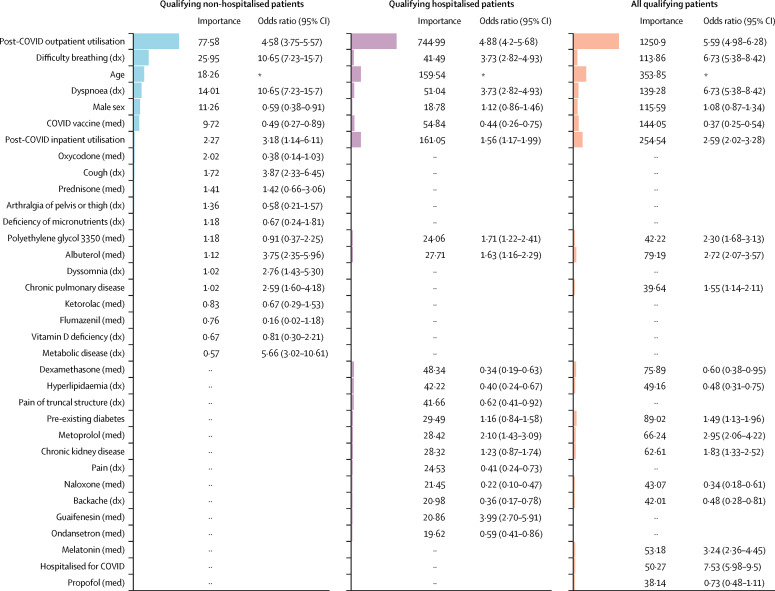
Using the National COVID Cohort Collaborative's (N3C) electronic health record repository, we developed XGBoost machine learning models to identify potential patients with long COVID. We defined our base population (n=1 793 604) as any non-deceased adult patient (age ≥18 years) with either an International Classification of Diseases-10-Clinical Modification COVID-19 diagnosis code (U07.1) from an inpatient or emergency visit, or a positive SARS-CoV-2 PCR or antigen test, and for whom at least 90 days have passed since COVID-19 index date. We examined demographics, health-care utilisation, diagnoses, and medications for 97 995 adults with COVID-19. We used data on these features and 597 patients from a long COVID clinic to train three machine learning models to identify potential long COVID among all patients with COVID-19, patients hospitalised with COVID-19, and patients who had COVID-19 but were not hospitalised. Feature importance was determined via Shapley values. We further validated the models on data from a fourth site.
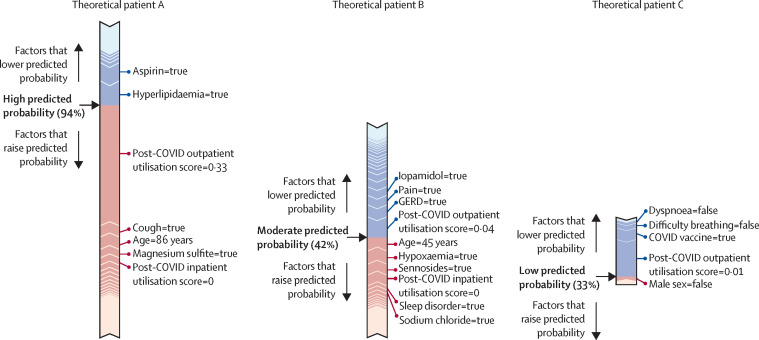
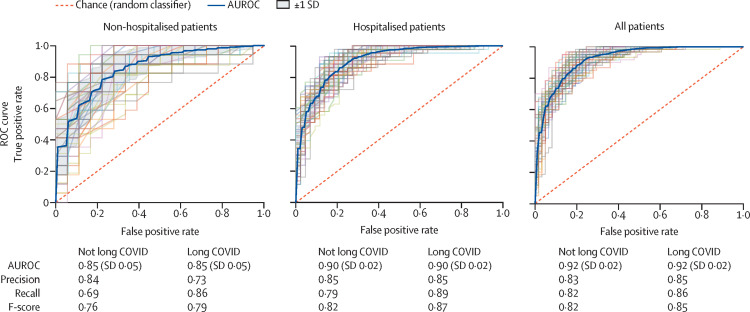
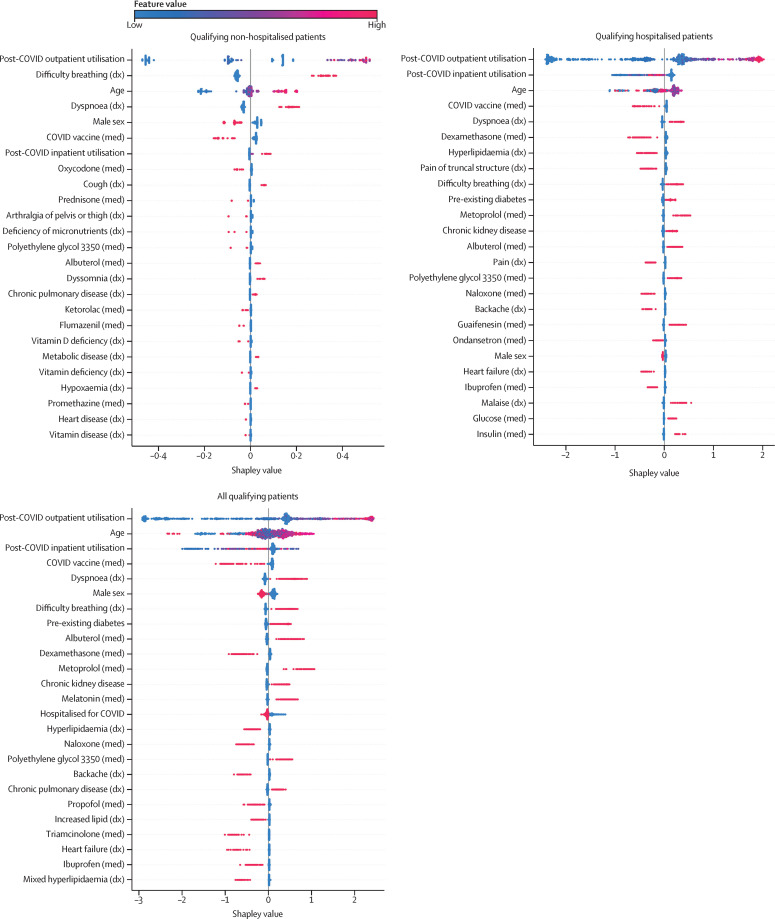
Our models identified, with high accuracy, patients who potentially have long COVID, achieving areas under the receiver operator characteristic curve of 0·92 (all patients), 0·90 (hospitalised), and 0·85 (non-hospitalised). Important features, as defined by Shapley values, include rate of health-care utilisation, patient age, dyspnoea, and other diagnosis and medication information available within the electronic health record.
Patients identified by our models as potentially having long COVID can be interpreted as patients warranting care at a specialty clinic for long COVID, which is an essential proxy for long COVID diagnosis as its definition continues to evolve. We also achieve the urgent goal of identifying potential long COVID in patients for clinical trials. As more data sources are identified, our models can be retrained and tuned based on the needs of individual studies.
US National Institutes of Health and National Center for Advancing Translational Sciences through the RECOVER Initiative.
新冠病毒感染的急性后期后遗症,即长新冠,严重影响了患者和社会从新冠疫情中恢复。长新冠的特点是症状不断演变且具有异质性,因此很难给出明确的定义。电子健康记录研究是美国国立卫生研究院(NIH)RECOVER 倡议的一个关键要素,该倡议旨在满足人们对长新冠的理解、治疗方法的探索,以及准确识别谁患有长新冠的迫切需求,而后者正是本研究的目的。
我们使用国家新冠队列协作(N3C)电子健康记录存储库,开发了 XGBoost 机器学习模型来识别可能患有长新冠的患者。我们将基本人群定义为任何非死亡的成年患者(年龄≥18 岁),这些患者要么在住院或急诊就诊时出现国际疾病分类第 10 次临床修订版(ICD-10-CM)新冠病毒诊断代码(U07.1),要么接受过新冠病毒 PCR 或抗原检测且距离新冠病毒发病日期已经过去至少 90 天。我们检查了 97995 名患有新冠病毒的成年人的人口统计学特征、医疗保健利用情况、诊断和用药情况。我们使用这些特征的数据以及长新冠诊所的 597 名患者,训练了三个机器学习模型,以识别所有患有新冠病毒的患者、因新冠病毒住院的患者以及未住院但患有新冠病毒的患者中可能患有长新冠病毒的患者。通过 Shapley 值确定特征的重要性。我们还在第四个地点的数据上验证了这些模型。
我们的模型以高准确率识别出可能患有长新冠病毒的患者,在所有患者、住院患者和非住院患者中,接收器工作特征曲线下的面积分别为 0.92、0.90 和 0.85。通过 Shapley 值定义的重要特征包括医疗保健利用速度、患者年龄、呼吸困难以及电子健康记录中其他诊断和用药信息。
我们的模型识别出的可能患有长新冠病毒的患者可以被解释为需要在长新冠病毒专科诊所接受治疗的患者,这是长新冠病毒诊断的重要替代指标,因为其定义仍在不断演变。我们还实现了在临床试验中识别潜在长新冠病毒患者的紧迫目标。随着更多数据源的确定,我们可以根据个别研究的需求对模型进行重新训练和调整。
美国国立卫生研究院和国家转化科学推进中心通过 RECOVER 倡议提供资金。