Oh Namkee, Cha Won Chul, Seo Jun Hyuk, Choi Seong-Gyu, Kim Jong Man, Chung Chi Ryang, Suh Gee Young, Lee Su Yeon, Oh Dong Kyu, Park Mi Hyeon, Lim Chae-Man, Ko Ryoung-Eun
Department of Surgery, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea.
Department of Emergency Medicine, Samsung Medical Center, Sungkyunkwan University School of Medicine, Seoul, Korea.
Healthc Inform Res. 2024 Jul;30(3):266-276. doi: 10.4258/hir.2024.30.3.266. Epub 2024 Jul 31.
Sepsis is a leading global cause of mortality, and predicting its outcomes is vital for improving patient care. This study explored the capabilities of ChatGPT, a state-of-the-art natural language processing model, in predicting in-hospital mortality for sepsis patients.
This study utilized data from the Korean Sepsis Alliance (KSA) database, collected between 2019 and 2021, focusing on adult intensive care unit (ICU) patients and aiming to determine whether ChatGPT could predict all-cause mortality after ICU admission at 7 and 30 days. Structured prompts enabled ChatGPT to engage in in-context learning, with the number of patient examples varying from zero to six. The predictive capabilities of ChatGPT-3.5-turbo and ChatGPT-4 were then compared against a gradient boosting model (GBM) using various performance metrics.
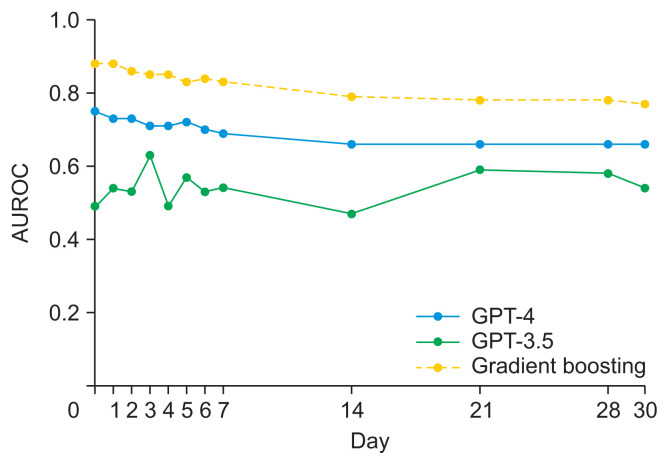
From the KSA database, 4,786 patients formed the 7-day mortality prediction dataset, of whom 718 died, and 4,025 patients formed the 30-day dataset, with 1,368 deaths. Age and clinical markers (e.g., Sequential Organ Failure Assessment score and lactic acid levels) showed significant differences between survivors and non-survivors in both datasets. For 7-day mortality predictions, the area under the receiver operating characteristic curve (AUROC) was 0.70-0.83 for GPT-4, 0.51-0.70 for GPT-3.5, and 0.79 for GBM. The AUROC for 30-day mortality was 0.51-0.59 for GPT-4, 0.47-0.57 for GPT-3.5, and 0.76 for GBM. Zero-shot predictions using GPT-4 for mortality from ICU admission to day 30 showed AUROCs from the mid-0.60s to 0.75 for GPT-4 and mainly from 0.47 to 0.63 for GPT-3.5.
GPT-4 demonstrated potential in predicting short-term in-hospital mortality, although its performance varied across different evaluation metrics.
脓毒症是全球主要的死亡原因,预测其预后对于改善患者护理至关重要。本研究探讨了先进的自然语言处理模型ChatGPT预测脓毒症患者院内死亡率的能力。
本研究利用了韩国脓毒症联盟(KSA)数据库在2019年至2021年期间收集的数据,重点关注成人重症监护病房(ICU)患者,旨在确定ChatGPT能否预测ICU入院后7天和30天的全因死亡率。结构化提示使ChatGPT能够进行上下文学习,患者示例数量从零到六个不等。然后使用各种性能指标将ChatGPT-3.5-turbo和ChatGPT-4的预测能力与梯度提升模型(GBM)进行比较。
从KSA数据库中,4786名患者构成了7天死亡率预测数据集,其中718人死亡;4025名患者构成了30天数据集,有1368人死亡。在两个数据集中,年龄和临床指标(如序贯器官衰竭评估评分和乳酸水平)在幸存者和非幸存者之间存在显著差异。对于7天死亡率预测,受试者工作特征曲线下面积(AUROC)在GPT-4为0.70-0.83,GPT-3.5为0.51-0.70,GBM为0.79。对于30天死亡率,GPT-4的AUROC为0.51-0.59,GPT-3.5为0.47-0.57,GBM为0.76。使用GPT-4对从ICU入院到第30天的死亡率进行零样本预测,GPT-4的AUROC从中0.60多到0.75,GPT-3.5主要从0.47到0.63。
GPT-4在预测短期院内死亡率方面显示出潜力,尽管其在不同评估指标下的表现有所不同。