D'Arrigo Graziella, El Hafeez Samar Abd, Mezzatesta Sabrina, Abelardo Domenico, Provenzano Fabio Pasquale, Vilasi Antonio, Torino Claudia, Tripepi Giovanni
CNR-IFC, Institute of Clinical Physiology of Reggio Calabria, Italy.
Epidemiology Department, High Institute of Public Health, Alexandria University, Alexandria, Egypt.
Clin Kidney J. 2024 Jun 26;17(7):sfae197. doi: 10.1093/ckj/sfae197. eCollection 2024 Jul.
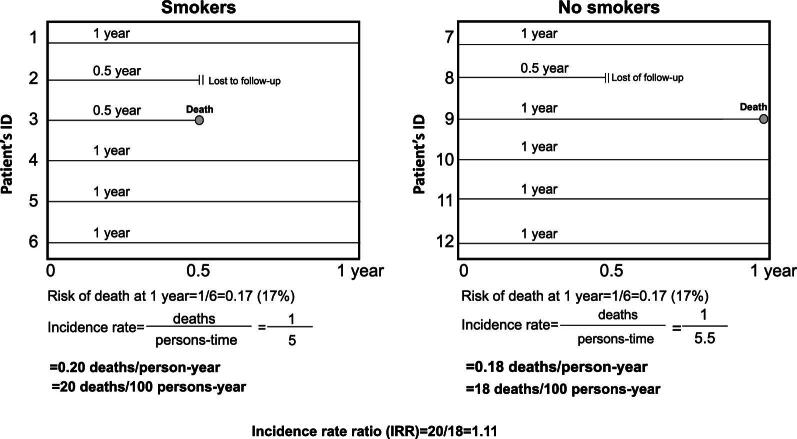
Biostatistics plays a pivotal role in developing, interpreting and drawing conclusions from clinical, biological and epidemiological data. However, the improper application of statistical methods can lead to erroneous conclusions and misinterpretations. This paper provides a comprehensive examination of the most frequent mistakes encountered in the biostatistical analysis process. We identified and elucidated 10 common errors in biostatistical analysis. These include using the wrong metric to describe data, misinterpreting -values, misinterpreting the 95% confidence interval, misinterpreting the hazard ratio as an index of prognostic accuracy, ignoring the sample size calculation, misinterpreting analysis by strata in randomized clinical trials, confusing correlation and causation, misunderstanding confounders and mediators, inadequately codifying variables during the data collection, and bias arising when group membership is attributed on the basis of future exposure in retrospective studies. We discuss the implications of these errors and propose some practical strategies to mitigate their impact. By raising awareness of these pitfalls, this paper aims to enhance the rigor and reproducibility of biostatistical analyses, thereby fostering more robust and reliable biomedical research findings.
生物统计学在临床、生物学和流行病学数据的开发、解释以及得出结论方面发挥着关键作用。然而,统计方法的不当应用可能导致错误的结论和误解。本文全面审视了生物统计学分析过程中最常出现的错误。我们识别并阐明了生物统计学分析中的10个常见错误。这些错误包括使用错误的指标来描述数据、错误解读P值、错误解读95%置信区间、将风险比错误解读为预后准确性指标、忽略样本量计算、错误解读随机临床试验中的分层分析、混淆相关性和因果关系、误解混杂因素和中介变量、在数据收集过程中对变量编码不充分,以及在回顾性研究中根据未来暴露情况确定分组时产生的偏差。我们讨论了这些错误的影响,并提出了一些切实可行的策略来减轻其影响。通过提高对这些陷阱的认识,本文旨在增强生物统计学分析的严谨性和可重复性,从而促进更稳健、可靠的生物医学研究结果。