Patel Dhavalkumar, Timsina Prem, Gorenstein Larisa, Glicksberg Benjamin S, Raut Ganesh, Cheetirala Satya Narayan, Santana Fabio, Tamegue Jules, Kia Arash, Zimlichman Eyal, Levin Matthew A, Freeman Robert, Klang Eyal
Institute for Healthcare Delivery Science, Icahn School of Medicine at Mount Sinai, New York, NY, United States.
Division of Diagnostic Imaging, Sheba Medical Center, Tel-Aviv University, Tel Aviv, Israel.
JMIR AI. 2024 Aug 27;3:e52190. doi: 10.2196/52190.
Predicting hospitalization from nurse triage notes has the potential to augment care. However, there needs to be careful considerations for which models to choose for this goal. Specifically, health systems will have varying degrees of computational infrastructure available and budget constraints.
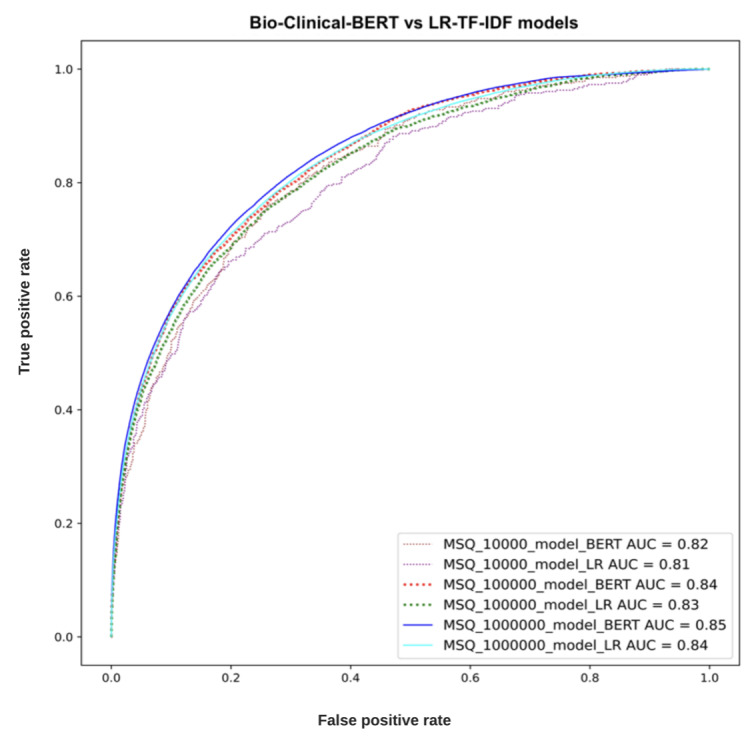
To this end, we compared the performance of the deep learning, Bidirectional Encoder Representations from Transformers (BERT)-based model, Bio-Clinical-BERT, with a bag-of-words (BOW) logistic regression (LR) model incorporating term frequency-inverse document frequency (TF-IDF). These choices represent different levels of computational requirements.
A retrospective analysis was conducted using data from 1,391,988 patients who visited emergency departments in the Mount Sinai Health System spanning from 2017 to 2022. The models were trained on 4 hospitals' data and externally validated on a fifth hospital's data.
The Bio-Clinical-BERT model achieved higher areas under the receiver operating characteristic curve (0.82, 0.84, and 0.85) compared to the BOW-LR-TF-IDF model (0.81, 0.83, and 0.84) across training sets of 10,000; 100,000; and ~1,000,000 patients, respectively. Notably, both models proved effective at using triage notes for prediction, despite the modest performance gap.
Our findings suggest that simpler machine learning models such as BOW-LR-TF-IDF could serve adequately in resource-limited settings. Given the potential implications for patient care and hospital resource management, further exploration of alternative models and techniques is warranted to enhance predictive performance in this critical domain.
INTERNATIONAL REGISTERED REPORT IDENTIFIER (IRRID): RR2-10.1101/2023.08.07.23293699.
根据护士分诊记录预测住院情况有可能改善医疗服务。然而,对于为此目的选择哪种模型需要谨慎考虑。具体而言,医疗系统可用的计算基础设施程度不同且存在预算限制。
为此,我们将基于深度学习的双向编码器表征来自变换器(BERT)的模型Bio-Clinical-BERT与结合词频逆文档频率(TF-IDF)的词袋(BOW)逻辑回归(LR)模型的性能进行了比较。这些选择代表了不同程度的计算要求。
使用2017年至2022年期间在西奈山医疗系统急诊科就诊的1,391,988名患者的数据进行回顾性分析。这些模型在4家医院的数据上进行训练,并在第五家医院的数据上进行外部验证。
在分别为10,000、100,000和约1,000,000名患者的训练集上,Bio-Clinical-BERT模型在接受者操作特征曲线下的面积更高(分别为0.82、0.84和0.85),而BOW-LR-TF-IDF模型(分别为0.81、0.83和0.84)。值得注意的是,尽管性能差距不大,但两种模型在使用分诊记录进行预测方面都证明是有效的。
我们的研究结果表明,诸如BOW-LR-TF-IDF等更简单的机器学习模型在资源有限的环境中可能足够适用。鉴于对患者护理和医院资源管理的潜在影响,有必要进一步探索替代模型和技术,以提高这一关键领域的预测性能。
国际注册报告识别码(IRRID):RR2-10.1101/2023.08.07.23293699。