ICF, Rockville, Maryland.
Georgetown University, Washington, District of Columbia.
Cancer Res Commun. 2024 Sep 1;4(9):2480-2488. doi: 10.1158/2767-9764.CRC-24-0243.
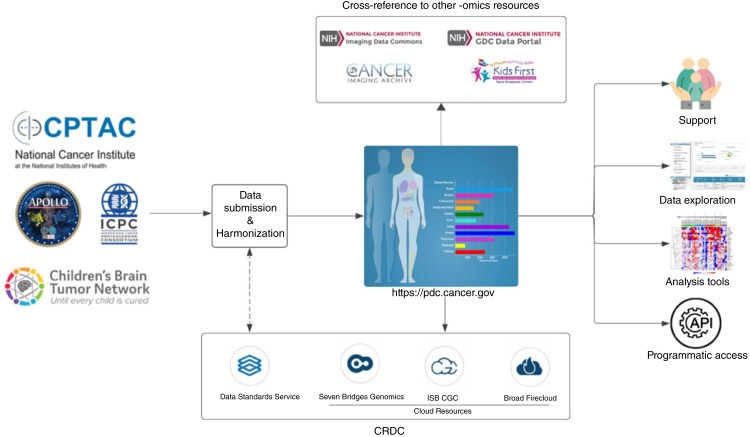
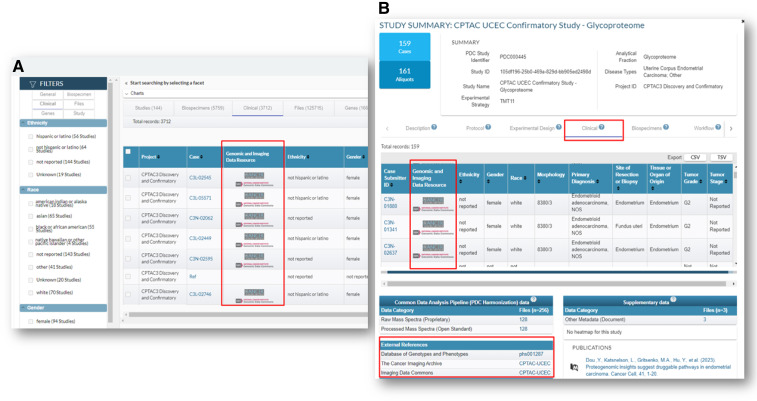
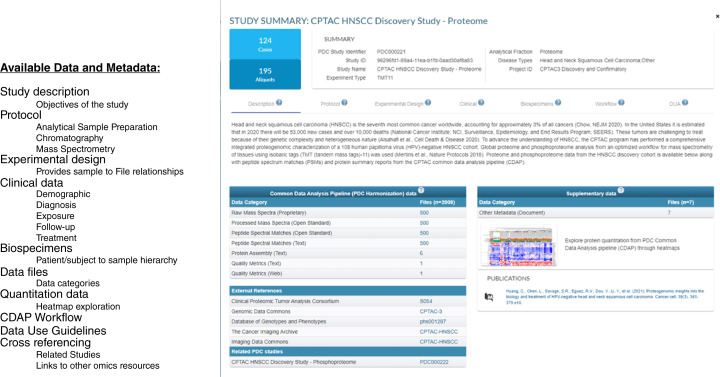
Proteomics has emerged as a powerful tool for studying cancer biology, developing diagnostics, and therapies. With the continuous improvement and widespread availability of high-throughput proteomic technologies, the generation of large-scale proteomic data has become more common in cancer research, and there is a growing need for resources that support the sharing and integration of multi-omics datasets. Such datasets require extensive metadata including clinical, biospecimen, and experimental and workflow annotations that are crucial for data interpretation and reanalysis. The need to integrate, analyze, and share these data has led to the development of NCI's Proteomic Data Commons (PDC), accessible at https://pdc.cancer.gov. As a specialized repository within the NCI Cancer Research Data Commons (CRDC), PDC enables researchers to locate and analyze proteomic data from various cancer types and connect with genomic and imaging data available for the same samples in other CRDC nodes. Presently, PDC houses annotated data from more than 160 datasets across 19 cancer types, generated by several large-scale cancer research programs with cohort sizes exceeding 100 samples (tumor and associated normal when available). In this article, we review the current state of PDC in cancer research, discuss the opportunities and challenges associated with data sharing in proteomics, and propose future directions for the resource.
The Proteomic Data Commons (PDC) plays a crucial role in advancing cancer research by providing a centralized repository of high-quality cancer proteomic data, enriched with extensive clinical annotations. By integrating and cross-referencing with complementary genomic and imaging data, the PDC facilitates multi-omics analyses, driving comprehensive insights, and accelerating discoveries across various cancer types.
蛋白质组学已成为研究癌症生物学、开发诊断和治疗方法的强大工具。随着高通量蛋白质组学技术的不断改进和广泛应用,在癌症研究中生成大规模蛋白质组学数据变得越来越普遍,并且越来越需要支持多组学数据集共享和整合的资源。这些数据集需要广泛的元数据,包括临床、生物样本和实验及工作流程注释,这些注释对于数据解释和再分析至关重要。需要整合、分析和共享这些数据,这导致了 NCI 的蛋白质组学数据公共库(PDC)的发展,可在 https://pdc.cancer.gov 访问。作为 NCI 癌症研究数据公共库(CRDC)中的一个专门存储库,PDC 使研究人员能够定位和分析来自各种癌症类型的蛋白质组学数据,并与同一样本中其他 CRDC 节点中可用的基因组和成像数据连接。目前,PDC 存储了来自 19 种癌症类型的超过 160 个数据集的注释数据,这些数据集由几个大型癌症研究计划生成,样本量超过 100 个(有肿瘤和相关正常组织时)。在本文中,我们回顾了 PDC 在癌症研究中的现状,讨论了蛋白质组学数据共享相关的机会和挑战,并提出了该资源的未来发展方向。
蛋白质组学数据公共库(PDC)通过提供高质量癌症蛋白质组学数据的集中存储库,并辅以广泛的临床注释,在推进癌症研究方面发挥着关键作用。通过与互补的基因组和成像数据进行整合和交叉引用,PDC 促进了多组学分析,推动了各种癌症类型的全面深入理解和发现。