Wade Kaitlyn E, Chen Lianghong, Deng Chutong, Zhou Gen, Hu Pingzhao
Department of Computer Science, University of Western Ontario, London, ON N6A 3K7, Canada.
Department of Biochemistry, University of Western Ontario, London, ON N6A 3K7, Canada.
Bioinform Adv. 2024 Jul 29;4(1):vbae108. doi: 10.1093/bioadv/vbae108. eCollection 2024.
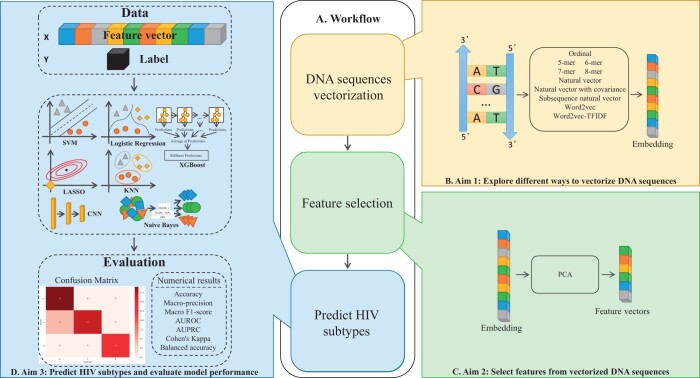
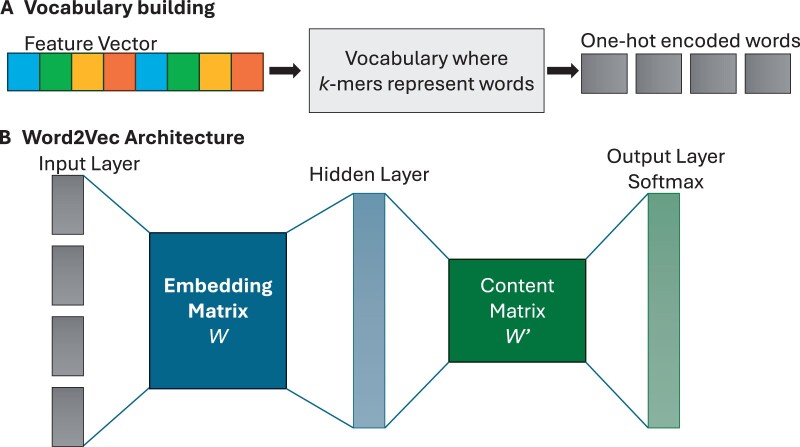
Many viruses are organized into taxonomies of subtypes based on their genetic similarities. For human immunodeficiency virus 1 (HIV-1), subtype classification plays a crucial role in infection management. Sequence alignment-based methods for subtype classification are impractical for large datasets because they are costly and time-consuming. Alignment-free methods involve creating numerical representations for genetic sequences and applying statistical or machine learning methods. Despite their high overall accuracy, existing models perform poorly on less common subtypes. Furthermore, there is limited work investigating the impact of sequence vectorization methods, in particular natural language-inspired embedding methods, on HIV-1 subtype classification.
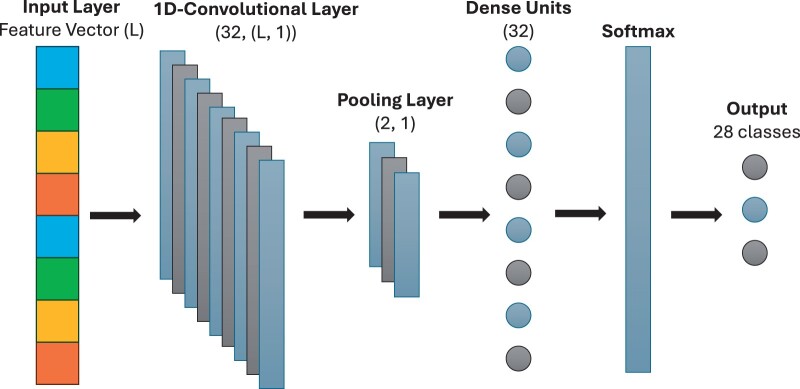
We present a comprehensive analysis of sequence vectorization methods across machine learning methods. We report a -mer-based XGBoost model with a balanced accuracy of 0.84, indicating that it has good overall performance for both common and uncommon HIV-1 subtypes. We also report a Word2Vec-based support vector machine that achieves promising results on precision and balanced accuracy. Our study sheds light on the effect of sequence vectorization methods on HIV-1 subtype classification and suggests that natural language-inspired encoding methods show promise. Our results could help to develop improved HIV-1 subtype classification methods, leading to improved individual patient outcomes, and the development of subtype-specific treatments.
Source code is available at https://www.github.com/kwade4/HIV_Subtypes.
许多病毒根据其基因相似性被组织成亚型分类法。对于人类免疫缺陷病毒1型(HIV-1),亚型分类在感染管理中起着至关重要的作用。基于序列比对的亚型分类方法对于大型数据集不实用,因为它们成本高且耗时。无比对方法涉及为基因序列创建数值表示并应用统计或机器学习方法。尽管现有模型总体准确率较高,但在不太常见的亚型上表现不佳。此外,研究序列向量化方法,特别是受自然语言启发的嵌入方法对HIV-1亚型分类的影响的工作有限。
我们对跨机器学习方法的序列向量化方法进行了全面分析。我们报告了一种基于k-mer的XGBoost模型,其平衡准确率为0.84,表明它对常见和不常见的HIV-1亚型都具有良好的总体性能。我们还报告了一种基于Word2Vec的支持向量机,它在精度和平衡准确率方面取得了有希望的结果。我们的研究揭示了序列向量化方法对HIV-1亚型分类的影响,并表明受自然语言启发的编码方法具有潜力。我们的结果有助于开发改进的HIV-1亚型分类方法,从而改善个体患者的治疗效果,并推动亚型特异性治疗的发展。