Luddy School of Informatics, Computing and Engineering, Indiana University, Bloomington, Indiana 47408, USA.
Luddy School of Informatics, Computing and Engineering, Indiana University, Bloomington, Indiana 47408, USA
Genome Res. 2024 Oct 11;34(9):1434-1444. doi: 10.1101/gr.279127.124.
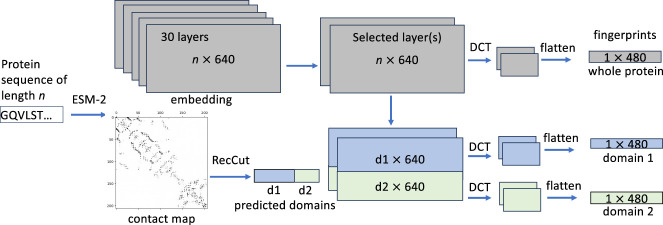
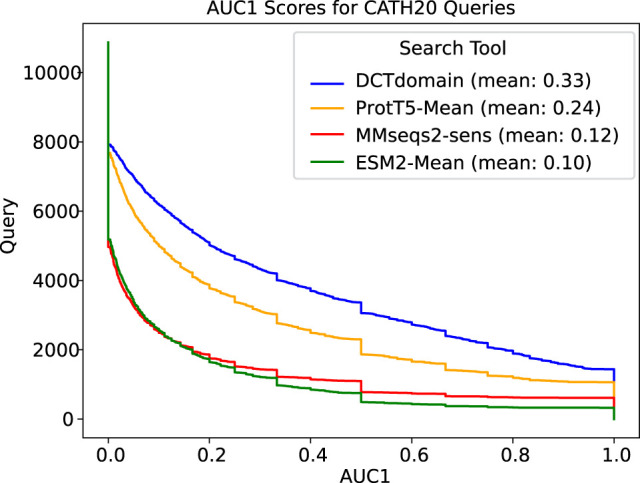
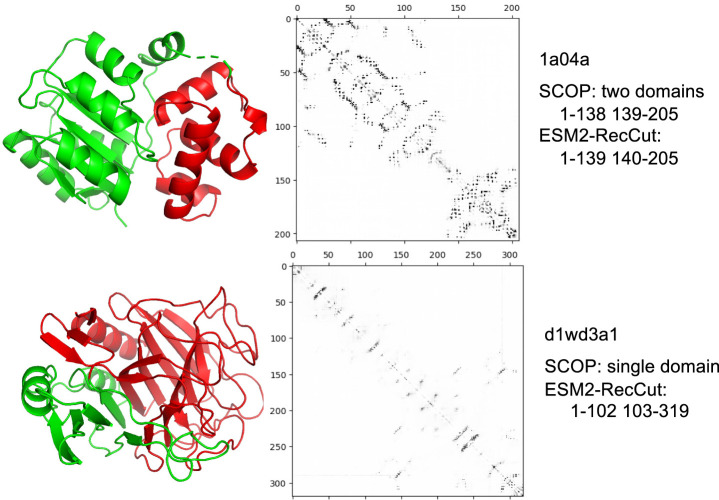
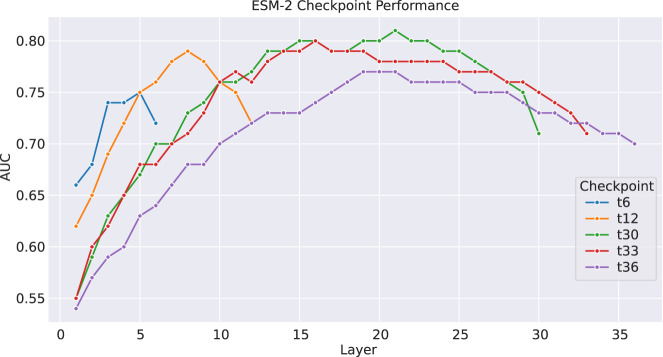
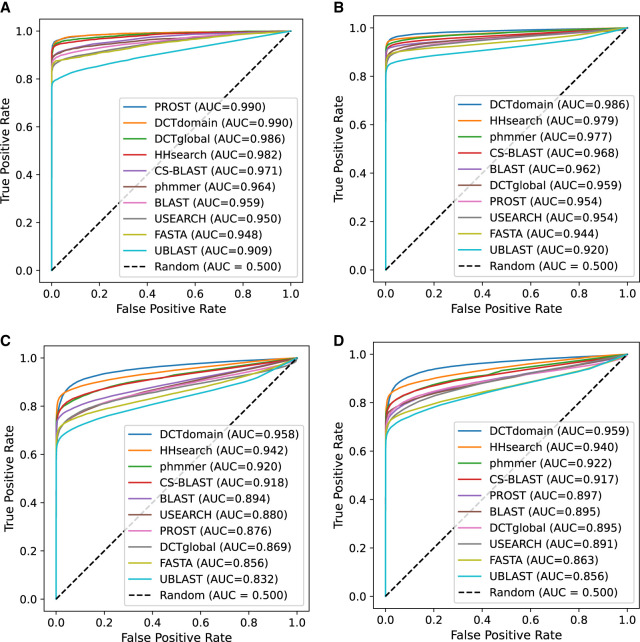
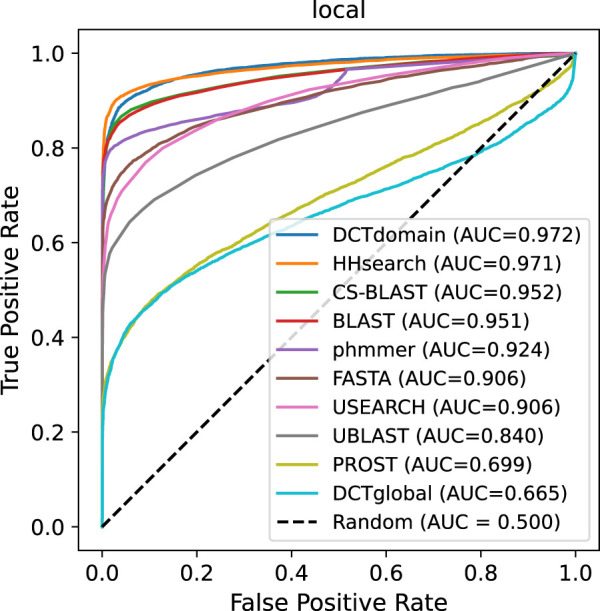
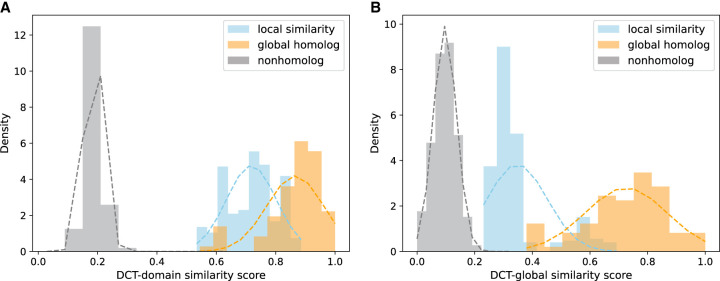
Recently developed protein language models have enabled a variety of applications with the protein contextual embeddings they produce. Per-protein representations (each protein is represented as a vector of fixed dimension) can be derived via averaging the embeddings of individual residues, or applying matrix transformation techniques such as the discrete cosine transformation (DCT) to matrices of residue embeddings. Such protein-level embeddings have been applied to enable fast searches of similar proteins; however, limitations have been found; for example, PROST is good at detecting global homologs but not local homologs, and knnProtT5 excels for proteins with single domains but not multidomain proteins. Here, we propose a novel approach that first segments proteins into domains (or subdomains) and then applies the DCT to the vectorized embeddings of residues in each domain to infer domain-level contextual vectors. Our approach, called DCTdomain, uses predicted contact maps from ESM-2 for domain segmentation, which is formulated as a problem and can be solved using a algorithm (RecCut in short) in quadratic time to the protein length; for comparison, an existing approach for domain segmentation uses a cubic-time algorithm. We show such domain-level contextual vectors (termed as ) enable fast and accurate detection of similarity between proteins that share global similarities but with undefined extended regions between shared domains, and those that only share local similarities. In addition, tests on a database search benchmark show that the DCTdomain is able to detect distant homologs by leveraging the structural information in the contextual embeddings.
最近开发的蛋白质语言模型通过产生的蛋白质上下文嵌入,实现了各种应用。可以通过对单个残基的嵌入进行平均,或者对残基嵌入的矩阵应用矩阵变换技术(如离散余弦变换(DCT))来获得每个蛋白质的表示形式(每个蛋白质都表示为固定维数的向量)。这些蛋白质级别的嵌入已被应用于实现类似蛋白质的快速搜索;然而,已经发现了一些局限性;例如,PROST 擅长检测全局同源物,但不擅长检测局部同源物,而 knnProtT5 擅长处理单域蛋白质,但不擅长处理多域蛋白质。在这里,我们提出了一种新方法,该方法首先将蛋白质分割成域(或子域),然后将 DCT 应用于每个域中残基的矢量化嵌入,以推断域级上下文向量。我们的方法称为 DCTdomain,它使用 ESM-2 预测的接触图进行域分割,这被表述为一个 问题,可以使用 算法(简称 RecCut)在二次时间内解决,对于蛋白质的长度;相比之下,现有的域分割方法使用三次时间算法。我们表明,这些域级上下文向量(称为 )能够快速准确地检测具有全局相似性但共享域之间定义不明确的扩展区域的蛋白质之间的相似性,以及仅共享局部相似性的蛋白质之间的相似性。此外,在数据库搜索基准测试上的测试表明,DCTdomain 能够通过利用上下文嵌入中的结构信息来检测遥远的同源物。