MindRank AI, Hangzhou, Zhejiang, China.
National Heart and Lung Institute, Imperial College London, London, SW7 2AZ, UK.
Sci Data. 2024 Sep 10;11(1):985. doi: 10.1038/s41597-024-03793-0.
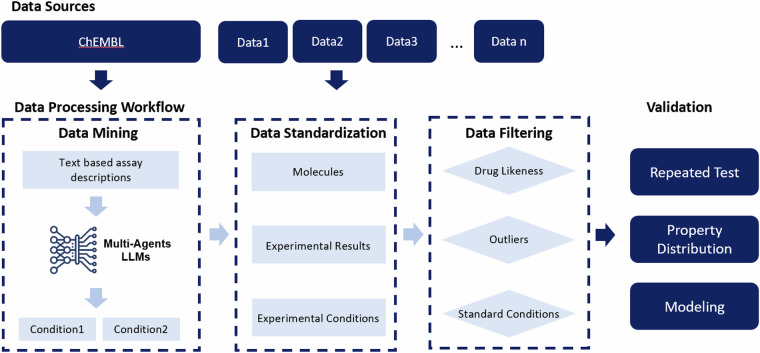
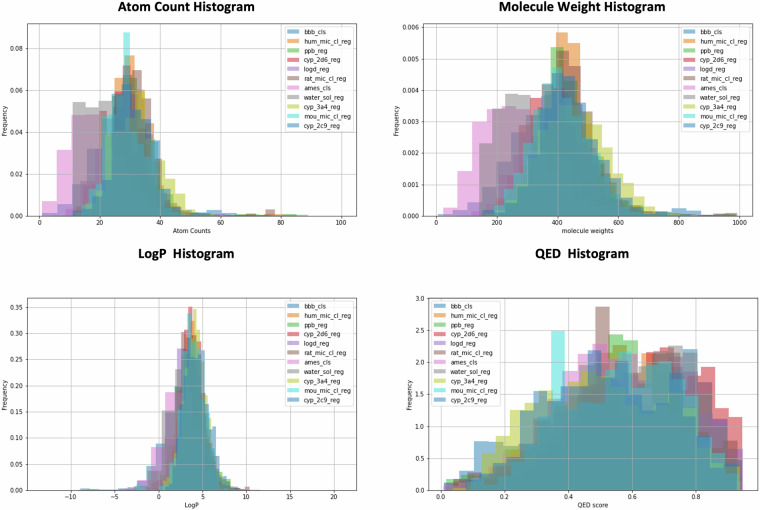
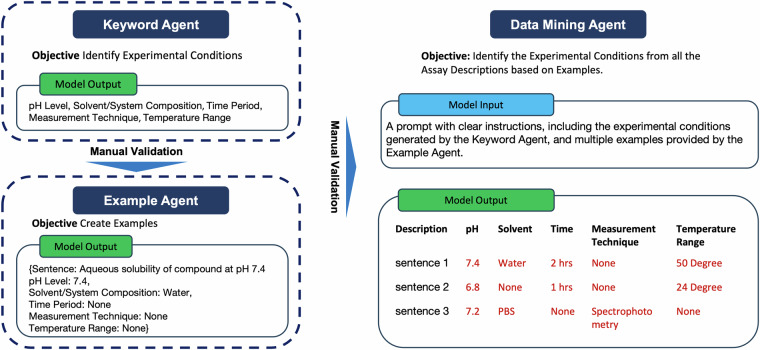
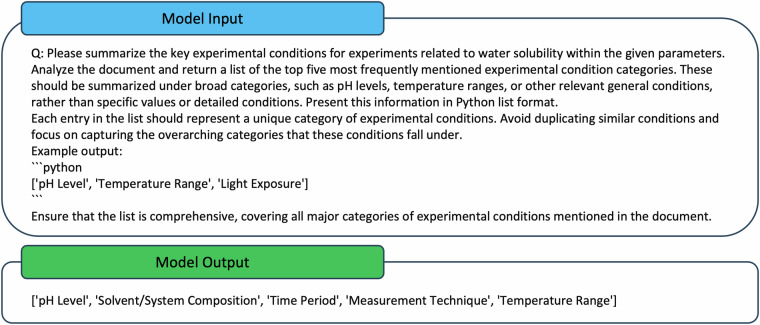
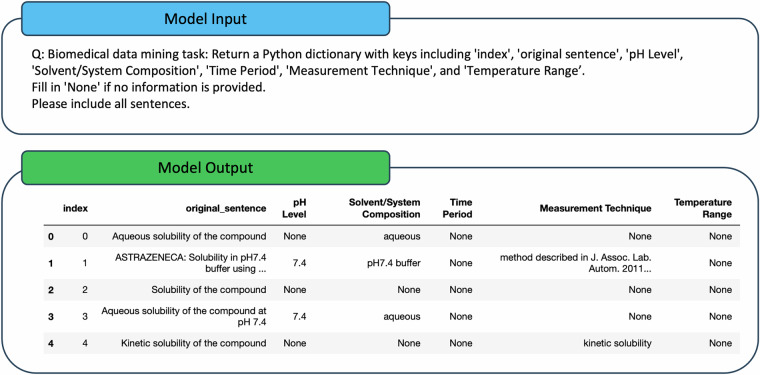
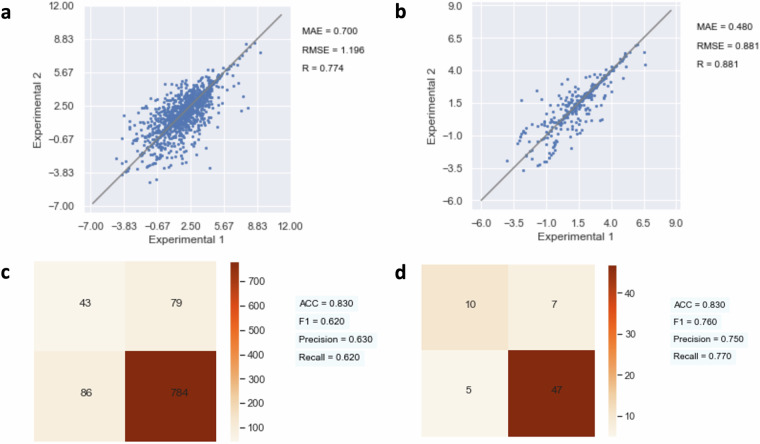
Accurately predicting ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) properties early in drug development is essential for selecting compounds with optimal pharmacokinetics and minimal toxicity. Existing ADMET-related benchmark sets are limited in utility due to their small dataset sizes and the lack of representation of compounds used in drug discovery projects. These shortcomings hinder their application in model building for drug discovery. To address this issue, we propose a multi-agent data mining system based on Large Language Models that effectively identifies experimental conditions within 14,401 bioassays. This approach facilitates merging entries from different sources, culminating in the creation of PharmaBench. Additionally, we have developed a data processing workflow to integrate data from various sources, resulting in 156,618 raw entries. Through this workflow, we constructed PharmaBench, a comprehensive benchmark set for ADMET properties, which comprises eleven ADMET datasets and 52,482 entries. This benchmark set is designed to serve as an open-source dataset for the development of AI models relevant to drug discovery projects.
准确预测 ADMET(吸收、分布、代谢、排泄和毒性)性质在药物开发的早期至关重要,因为这有助于选择具有最佳药代动力学和最小毒性的化合物。现有的 ADMET 相关基准集由于其数据集规模较小且缺乏药物发现项目中使用的化合物的代表性,因此其用途有限。这些缺点阻碍了它们在药物发现模型构建中的应用。为了解决这个问题,我们提出了一个基于大型语言模型的多代理数据挖掘系统,该系统可以有效地识别 14401 项生物测定实验中的实验条件。这种方法有助于合并来自不同来源的数据项,最终创建了 PharmaBench。此外,我们还开发了一个数据处理工作流程,用于整合来自不同来源的数据,从而产生了 156618 个原始数据项。通过这个工作流程,我们构建了 PharmaBench,这是一个用于 ADMET 性质的综合性基准集,包含 11 个 ADMET 数据集和 52482 个数据项。这个基准集旨在作为一个开源数据集,用于开发与药物发现项目相关的 AI 模型。