Liu Zhoubin, Yang Bozhi, Zhang Tianyuan, Sun Hao, Mao Lianzhen, Yang Sha, Dai Xiongze, Suo Huan, Zhang Zhuqing, Chen Wenchao, Chen Hu, Xu Wangjie, Dossa Komivi, Zou Xuexiao, Ou Lijun
Engineering Research Center of Education, Ministry for Germplasm Innovation and Breeding New Varieties of Horticultural Crops, Key Laboratory for Vegetable Biology of Hunan Province, College of Horticulture, Hunan Agricultural University, Changsha 410125, China.
Vegetable Institution of Hunan Academy of Agricultural Science, Changsha 410125, China.
Hortic Res. 2024 Jul 24;11(9):uhae198. doi: 10.1093/hr/uhae198. eCollection 2024 Sep.
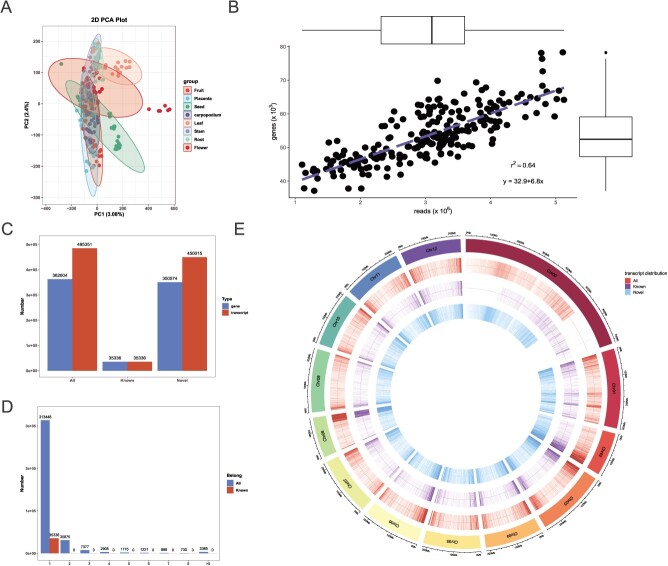
Chili pepper is an important spice and a model plant for fruit development studies. Large-scale omics information on chili pepper plant development continues to be gathered for understanding development as well as capsaicin biosynthesis. In this study, a full-spectrum transcriptome data of eight chili pepper tissues at five growth stages using the Oxford Nanopore long-read sequencing approach was generated. Of the 485 351 transcripts, 35 336 were recorded as reference transcripts (genes), while 450 015 were novel including coding, lnc, and other non-coding RNAs. These novel transcripts belonged to unknown/intergenic (347703), those retained introns (26336), and had multi-exons with at least one junction match (20333). In terms of alternative splicing, retained intron had the highest proportion (14795). The number of tissue-specific expressed transcripts ranged from 22 925 (stem) to 40 289 (flower). The expression changes during fruit and placenta development are discussed in detail. Integration of gene expression and capsaicin content quantification throughout the placental development clarifies that capsaicin biosynthesis in pepper is mainly derived from valine, leucin, and isoleucine degradation as well as citrate cycle and/or pyrimidine metabolism pathways. Most importantly, a user-friendly Pepper Full-Length Transcriptome Variation Database (PFTVD 1.0) (http://pepper-database.cn/) has been developed. PFTVD 1.0 provides transcriptomics and genomics information and allows users to analyse the data using various tools implemented. This work highlights the potential of long-read sequencing to discover novel genes and transcripts and their diversity in plant developmental biology.
辣椒是一种重要的香料,也是果实发育研究的模式植物。为了了解其发育过程以及辣椒素的生物合成,关于辣椒植株发育的大规模组学信息仍在不断收集。在本研究中,利用牛津纳米孔长读长测序方法生成了五个生长阶段的八个辣椒组织的全谱转录组数据。在485351个转录本中,35336个被记录为参考转录本(基因),而450015个是新的转录本,包括编码RNA、长链非编码RNA和其他非编码RNA。这些新转录本属于未知/基因间区域(347703个)、保留内含子的转录本(26336个)以及具有多个外显子且至少有一个接头匹配的转录本(20333个)。在可变剪接方面,保留内含子的比例最高(14795个)。组织特异性表达转录本的数量从22925个(茎)到40289个(花)不等。详细讨论了果实和胎座发育过程中的表达变化。通过整合整个胎座发育过程中的基因表达和辣椒素含量定量分析,明确了辣椒中辣椒素的生物合成主要来源于缬氨酸、亮氨酸和异亮氨酸的降解以及柠檬酸循环和/或嘧啶代谢途径。最重要的是,已经开发了一个用户友好的辣椒全长转录组变异数据库(PFTVD 1.0)(http://pepper-database.cn/)。PFTVD 1.0提供转录组学和基因组学信息,并允许用户使用所实现的各种工具分析数据。这项工作突出了长读长测序在植物发育生物学中发现新基因和转录本及其多样性的潜力。