Chen Zuojun, Qin Pinle, Zeng Jianchao, Song Quanzhen, Zhao Pengcheng, Chai Rui
School of Computer Science and Technology, North University of China, Taiyuan, 030051, China.
Sci Rep. 2024 Sep 18;14(1):21760. doi: 10.1038/s41598-024-72912-z.
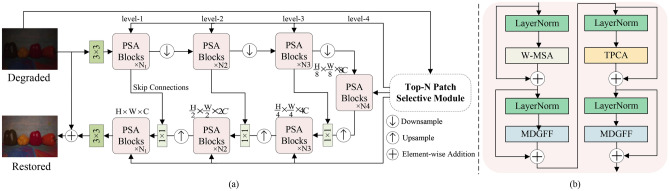
Transformer-based methods effectively capture global dependencies in images, demonstrating outstanding performance in multiple visual tasks. However, existing Transformers cannot effectively denoise large noisy images captured under low-light conditions owing to (1) the global self-attention mechanism causing high computational complexity in the spatial dimension owing to a quadratic increase in computation with the number of tokens; (2) the channel-wise self-attention computation unable to optimise the spatial correlations in images. We propose a local-global interaction Transformer (LGIT) that employs an adaptive strategy to select relevant patches for global interaction, achieving low computational complexity in global self-attention computation. A top-N patch cross-attention model (TPCA) is designed based on superpixel segmentation guidance. TPCA selects top-N patches most similar to the target image patch and applies cross attention to aggregate information from them into the target patch, effectively enhancing the utilisation of the image's nonlocal self-similarity. A mixed-scale dual-gated feedforward network (MDGFF) is introduced for the effective extraction of multiscale local correlations. TPCA and MDGFF were combined to construct a hierarchical encoder-decoder network, LGIT, to compute self-attention within and across patches at different scales. Extensive experiments using real-world image-denoising datasets demonstrated that LGIT outperformed state-of-the-art (SOTA) convolutional neural network (CNN) and Transformer-based methods in qualitative and quantitative results.
基于Transformer的方法能够有效地捕捉图像中的全局依赖性,在多个视觉任务中表现出色。然而,现有的Transformer无法有效地对在低光照条件下拍摄的大尺寸噪声图像进行去噪,原因如下:(1)全局自注意力机制由于计算量随token数量呈二次方增长,导致在空间维度上计算复杂度较高;(2)通道维度的自注意力计算无法优化图像中的空间相关性。我们提出了一种局部-全局交互Transformer(LGIT),它采用自适应策略来选择用于全局交互的相关patch,在全局自注意力计算中实现了低计算复杂度。基于超像素分割引导设计了一种top-N patch交叉注意力模型(TPCA)。TPCA选择与目标图像patch最相似的top-N个patch,并应用交叉注意力将来自它们的信息聚合到目标patch中,有效地提高了图像非局部自相似性的利用率。引入了一种混合尺度双门控前馈网络(MDGFF)来有效提取多尺度局部相关性。将TPCA和MDGFF相结合,构建了一个分层编码器-解码器网络LGIT,以计算不同尺度下patch内部和跨patch的自注意力。使用真实世界图像去噪数据集进行的大量实验表明,LGIT在定性和定量结果方面均优于当前最先进的(SOTA)卷积神经网络(CNN)和基于Transformer的方法。