Institute for High-Performance Computing and Networking, National Research Council, Naples, Italy.
Information Technology Services, University of Naples "L'Orientale", Naples, Italy.
PLoS Comput Biol. 2024 Sep 27;20(9):e1012076. doi: 10.1371/journal.pcbi.1012076. eCollection 2024 Sep.
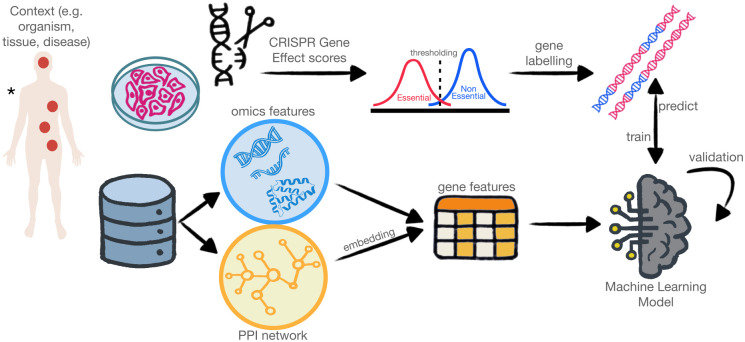
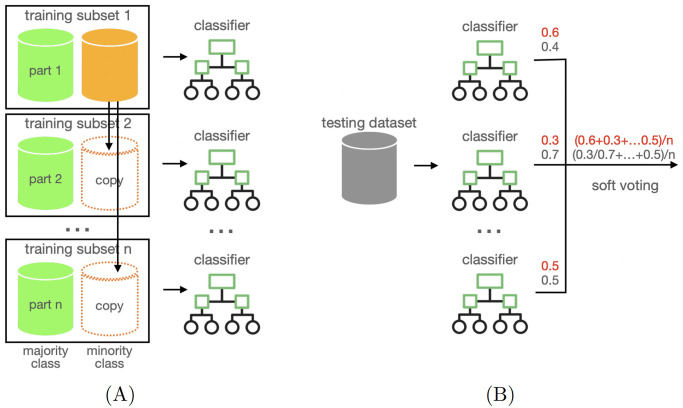
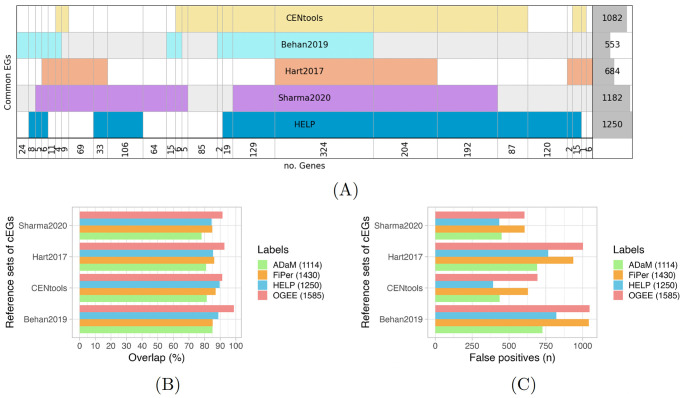
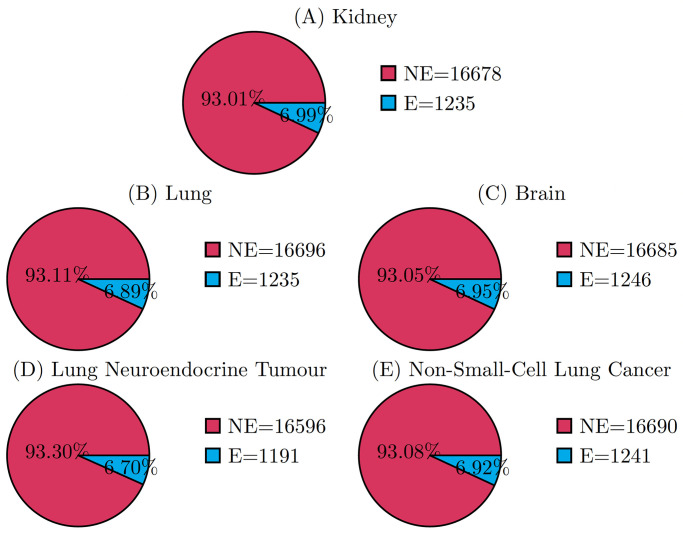
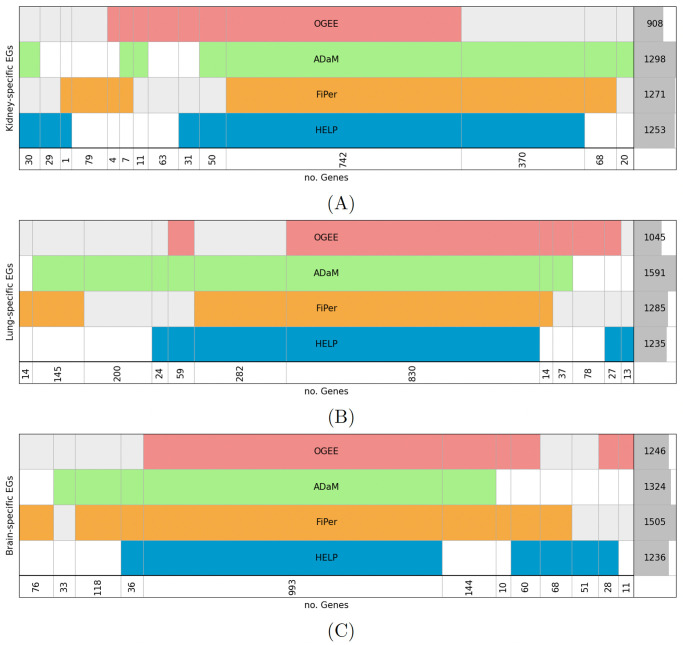
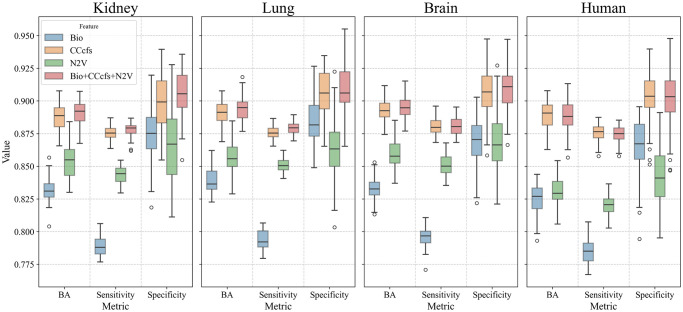
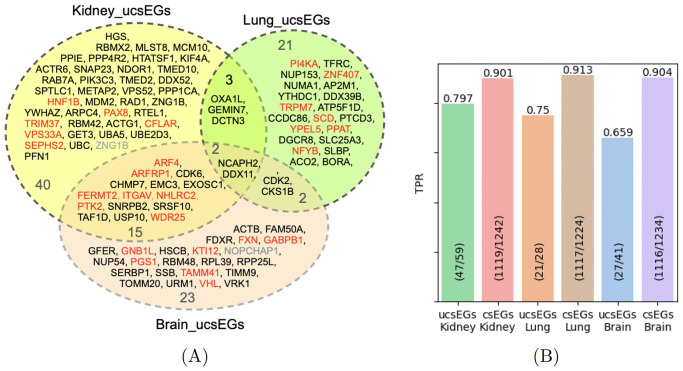
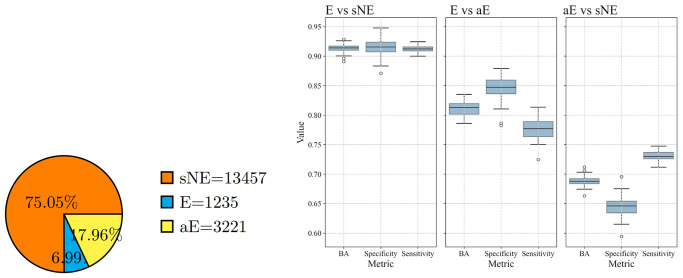
Machine learning-based approaches are particularly suitable for identifying essential genes as they allow the generation of predictive models trained on features from multi-source data. Gene essentiality is neither binary nor static but determined by the context. The databases for essential gene annotation do not permit the personalisation of the context, and their update can be slower than the publication of new experimental data. We propose HELP (Human Gene Essentiality Labelling & Prediction), a computational framework for labelling and predicting essential genes. Its double scope allows for identifying genes based on dependency or not on experimental data. The effectiveness of the labelling method was demonstrated by comparing it with other approaches in overlapping the reference sets of essential gene annotations, where HELP demonstrated the best compromise between false and true positive rates. The gene attributes, including multi-omics and network embedding features, lead to high-performance prediction of essential genes while confirming the existence of essentiality nuances.
基于机器学习的方法特别适合识别必需基因,因为它们可以生成基于多源数据特征训练的预测模型。基因的必需性既不是二进制的,也不是静态的,而是由上下文决定的。必需基因注释数据库不允许个性化上下文,并且它们的更新速度可能比新实验数据的发布速度慢。我们提出了 HELP(人类基因必需性标记和预测),这是一个用于标记和预测必需基因的计算框架。其双重范围允许根据实验数据确定基因的依赖性或非依赖性。通过将其与其他方法在必需基因注释的参考集中进行比较,证明了标记方法的有效性,其中 HELP 在假阳性率和真阳性率之间表现出最佳折衷。基因属性,包括多组学和网络嵌入特征,在确认必需性细微差别的同时,实现了对必需基因的高性能预测。