Department of Computer Science, University College London, London, UK.
Institute of Health Informatics, University College London, London, UK.
Sci Rep. 2024 Oct 8;14(1):23485. doi: 10.1038/s41598-024-73338-3.
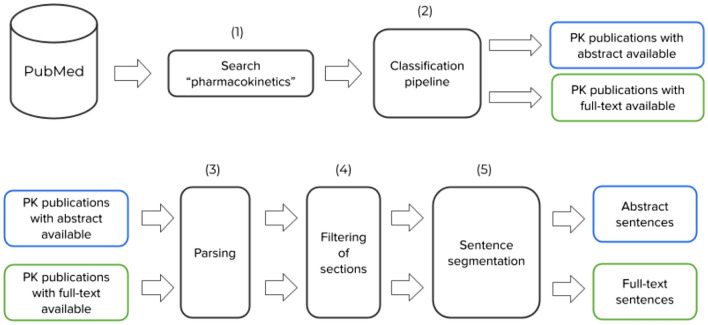
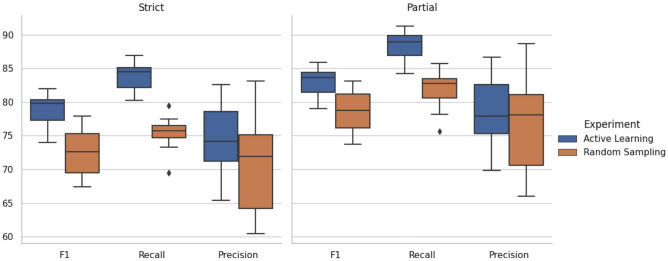
The development of accurate predictions for a new drug's absorption, distribution, metabolism, and excretion profiles in the early stages of drug development is crucial due to high candidate failure rates. The absence of comprehensive, standardised, and updated pharmacokinetic (PK) repositories limits pre-clinical predictions and often requires searching through the scientific literature for PK parameter estimates from similar compounds. While text mining offers promising advancements in automatic PK parameter extraction, accurate Named Entity Recognition (NER) of PK terms remains a bottleneck due to limited resources. This work addresses this gap by introducing novel corpora and language models specifically designed for effective NER of PK parameters. Leveraging active learning approaches, we developed an annotated corpus containing over 4000 entity mentions found across the PK literature on PubMed. To identify the most effective model for PK NER, we fine-tuned and evaluated different NER architectures on our corpus. Fine-tuning BioBERT exhibited the best results, achieving a strict score of 90.37% in recognising PK parameter mentions, significantly outperforming heuristic approaches and models trained on existing corpora. To accelerate the development of end-to-end PK information extraction pipelines and improve pre-clinical PK predictions, the PK NER models and the labelled corpus were released open source at https://github.com/PKPDAI/PKNER .
由于候选药物的失败率较高,因此在药物开发的早期阶段准确预测新药的吸收、分布、代谢和排泄特征至关重要。缺乏全面、标准化和更新的药代动力学 (PK) 存储库限制了临床前预测,并且经常需要在科学文献中搜索类似化合物的 PK 参数估计值。虽然文本挖掘为自动 PK 参数提取提供了有希望的进展,但由于资源有限,PK 术语的准确命名实体识别 (NER) 仍然是一个瓶颈。这项工作通过引入专门为有效识别 PK 参数的新型语料库和语言模型来解决这一差距。利用主动学习方法,我们在 PubMed 上的 PK 文献中开发了一个包含超过 4000 个实体提及的带注释语料库。为了确定最适合 PK NER 的模型,我们在我们的语料库上微调并评估了不同的 NER 架构。微调后的 BioBERT 表现出最佳结果,在识别 PK 参数提及方面的严格 F1 得分为 90.37%,明显优于启发式方法和基于现有语料库训练的模型。为了加速端到端 PK 信息提取管道的开发并提高临床前 PK 预测,PK NER 模型和标记语料库在 https://github.com/PKPDAI/PKNER 上开源发布。