Prado Melina, Famoso Adam, Guidry Kurt, Fritsche-Neto Roberto
Department of Genetics, "Luiz de Queiroz" College of Agriculture/University of São Paulo, Piracicaba, Brazil.
H. Rouse Caffey Rice Research Station, Louisiana State University Agricultural Center, Rayne, LA, United States.
Front Plant Sci. 2024 Oct 23;15:1458701. doi: 10.3389/fpls.2024.1458701. eCollection 2024.
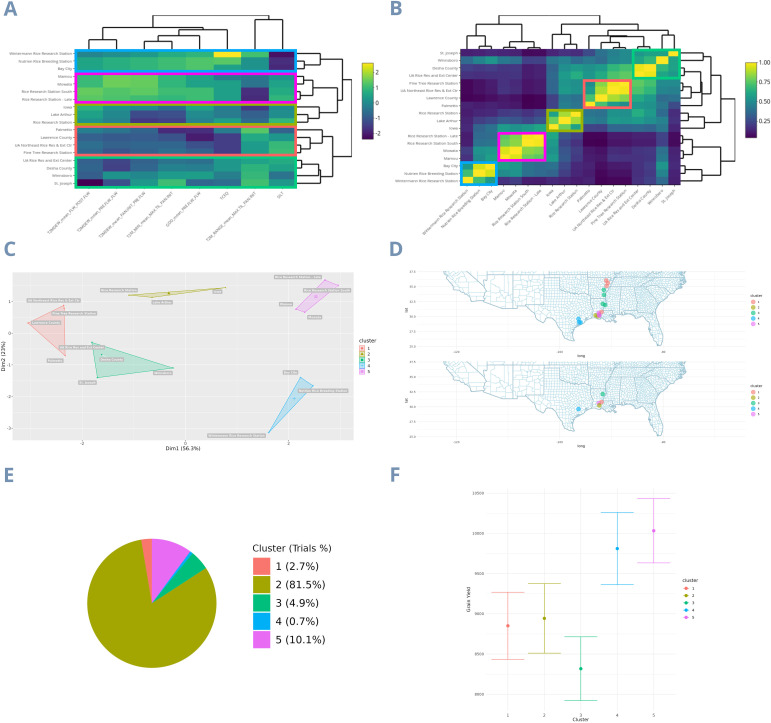
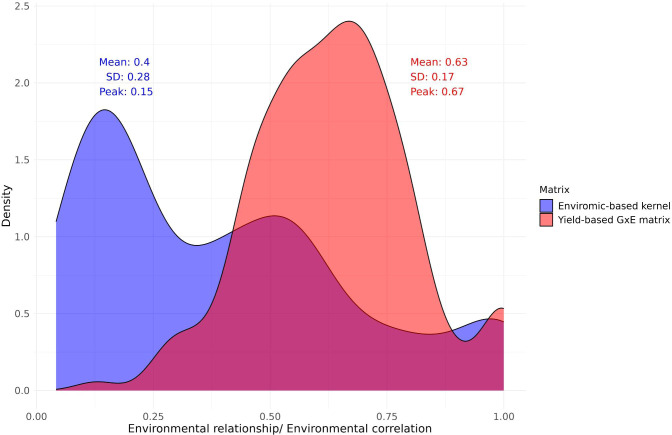
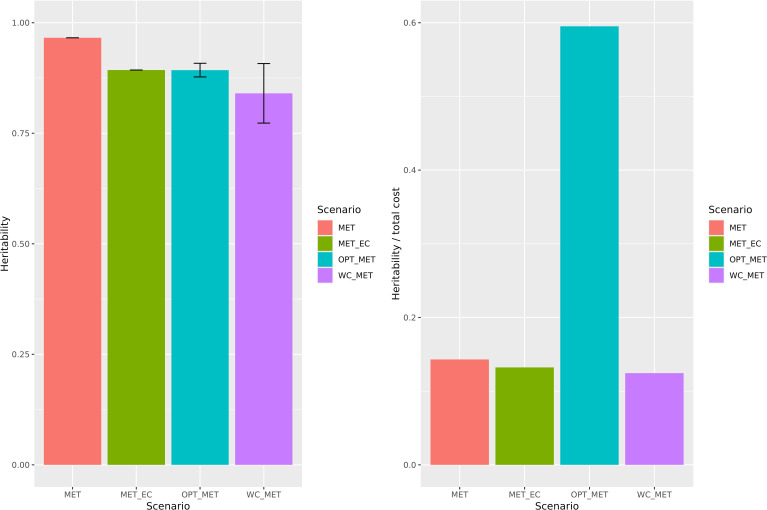
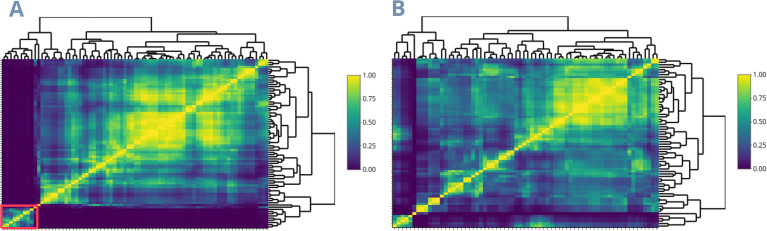
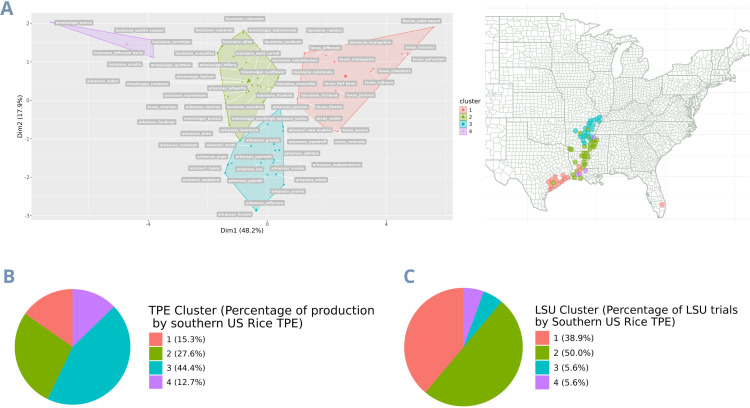
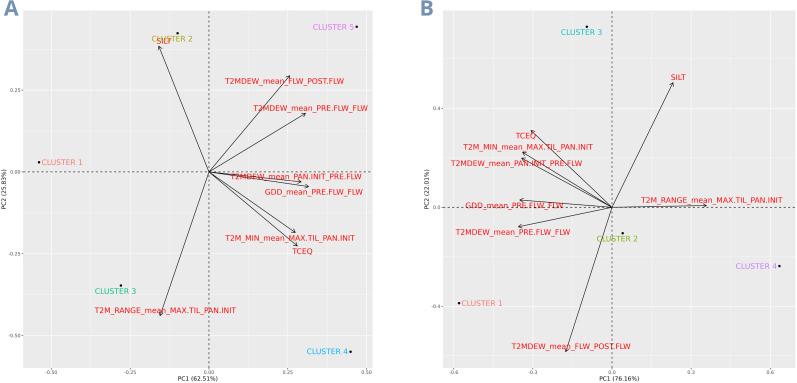
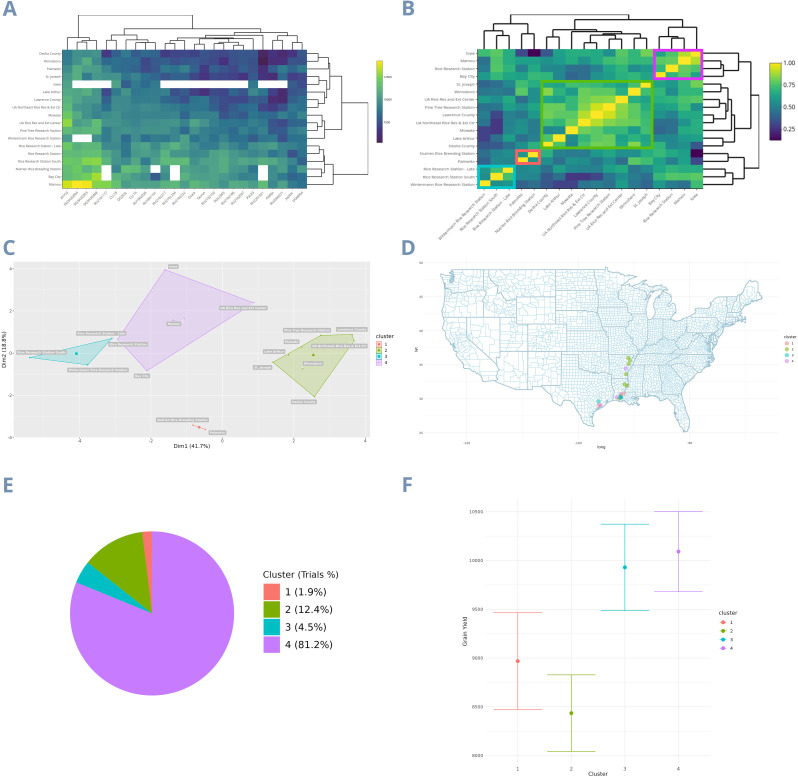
Rice breeding programs globally have worked to release increasingly productive and climate-smart cultivars, but the genetic gains have been limited for some reasons. One is the capacity for field phenotyping, which presents elevated costs and an unclear approach to defining the number and allocation of multi-environmental trials (MET). To address this challenge, we used soil information and ten years of historical weather data from the USA rice belt, which was translated into rice response based on the rice cardinal temperatures and crop stages. Next, we eliminated those highly correlated Environmental Covariates (ECs) (>0.95) and applied a supervised algorithm for feature selection using two years of data (2021-22) and 25 genotypes evaluated for grain yield in 18 representative locations in the Southern USA. To test the trials' optimization, we performed the joint analysis using prediction-based models in four different scenarios: i) considering trials as non-related, ii) including the environmental relationship matrix calculated from ECs, iii) within clusters; iv) sampling one location per cluster. Finally, we weigh the trial's allocation considering the counties' economic importance and the environmental group to which they belong. Our findings show that eight ECs explained 58% of grain yield variation across sites and 53% of the observed genotype-by-environment interaction. Moreover, it is possible to reduce 28% the number of locations without significant loss in accuracy. Furthermore, the US Rice belt comprises four clusters, with economic importance varying from 13 to 45%. These results will help us better allocate trials in advance and reduce costs without penalizing accuracy.
全球的水稻育种计划一直致力于培育出产量更高且适应气候的品种,但由于某些原因,遗传增益有限。其中一个原因是田间表型分析能力,这存在成本高昂以及确定多环境试验(MET)数量和分配方式不明确的问题。为应对这一挑战,我们利用了美国水稻种植带的土壤信息和十年历史气象数据,并根据水稻的基础温度和作物生长阶段将其转化为水稻响应数据。接下来,我们剔除了那些高度相关(>0.95)的环境协变量(EC),并使用两年的数据(2021 - 2022年)和在美国南部18个代表性地点对25个基因型进行的谷物产量评估数据,应用一种监督算法进行特征选择。为了测试试验的优化效果,我们在四种不同场景下使用基于预测的模型进行联合分析:i)将试验视为不相关;ii)纳入根据环境协变量计算出的环境关系矩阵;iii)在聚类内;iv)每个聚类抽取一个地点。最后,我们根据各县的经济重要性及其所属的环境组来权衡试验的分配。我们的研究结果表明,8个环境协变量解释了不同地点间58%的谷物产量变异以及观察到的53%的基因型与环境的互作。此外,有可能减少28%的试验地点数量而不会显著降低准确性。此外,美国水稻种植带包括四个聚类,经济重要性从13%到45%不等。这些结果将有助于我们提前更好地分配试验并降低成本,同时不会牺牲准确性。