Klang Eyal, Apakama Donald, Abbott Ethan E, Vaid Akhil, Lampert Joshua, Sakhuja Ankit, Freeman Robert, Charney Alexander W, Reich David, Kraft Monica, Nadkarni Girish N, Glicksberg Benjamin S
Division of Data-Driven and Digital Medicine, Department of Medicine, Icahn School of Medicine at Mount Sinai, New York, NY, USA.
The Charles Bronfman Institute of Personalized Medicine, Icahn School of Medicine at Mount Sinai, New York, NY, USA.
NPJ Digit Med. 2024 Nov 18;7(1):320. doi: 10.1038/s41746-024-01315-1.
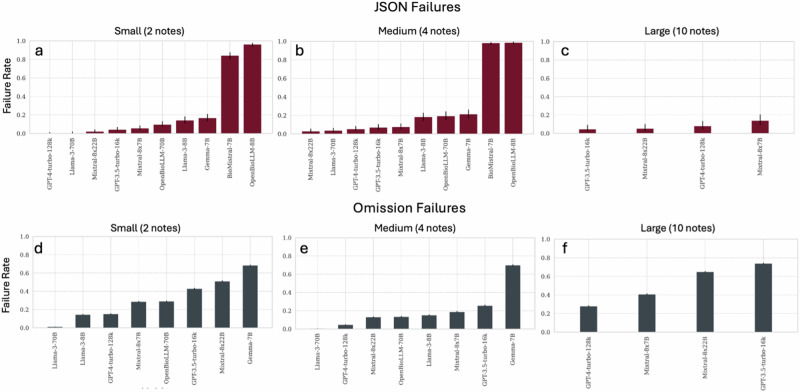
Large language models (LLMs) can optimize clinical workflows; however, the economic and computational challenges of their utilization at the health system scale are underexplored. We evaluated how concatenating queries with multiple clinical notes and tasks simultaneously affects model performance under increasing computational loads. We assessed ten LLMs of different capacities and sizes utilizing real-world patient data. We conducted >300,000 experiments of various task sizes and configurations, measuring accuracy in question-answering and the ability to properly format outputs. Performance deteriorated as the number of questions and notes increased. High-capacity models, like Llama-3-70b, had low failure rates and high accuracies. GPT-4-turbo-128k was similarly resilient across task burdens, but performance deteriorated after 50 tasks at large prompt sizes. After addressing mitigable failures, these two models can concatenate up to 50 simultaneous tasks effectively, with validation on a public medical question-answering dataset. An economic analysis demonstrated up to a 17-fold cost reduction at 50 tasks using concatenation. These results identify the limits of LLMs for effective utilization and highlight avenues for cost-efficiency at the enterprise scale.
大语言模型(LLMs)可以优化临床工作流程;然而,在卫生系统规模上使用它们所面临的经济和计算挑战尚未得到充分探索。我们评估了在计算负载增加的情况下,将查询与多个临床记录和任务同时串联起来如何影响模型性能。我们使用真实世界的患者数据评估了十种不同能力和规模的大语言模型。我们进行了超过30万次不同任务规模和配置的实验,测量问答的准确性以及正确格式化输出的能力。随着问题和记录数量的增加,性能会下降。像Llama-3-70b这样的高容量模型故障率低且准确率高。GPT-4-turbo-128k在不同任务负担下同样具有弹性,但在大提示规模下处理50个任务后性能会下降。在解决了可缓解的故障后,这两个模型可以有效地串联多达50个同时进行的任务,并在一个公共医学问答数据集上进行了验证。一项经济分析表明,使用串联方式在处理50个任务时成本可降低多达17倍。这些结果确定了大语言模型有效利用的局限性,并突出了企业规模下实现成本效益的途径。