Borges Beatriz, Foroutan Negar, Bayazit Deniz, Sotnikova Anna, Montariol Syrielle, Nazaretsky Tanya, Banaei Mohammadreza, Sakhaeirad Alireza, Servant Philippe, Neshaei Seyed Parsa, Frej Jibril, Romanou Angelika, Weiss Gail, Mamooler Sepideh, Chen Zeming, Fan Simin, Gao Silin, Ismayilzada Mete, Paul Debjit, Schwaller Philippe, Friedli Sacha, Jermann Patrick, Käser Tanja, Bosselut Antoine
École Polytechnique Fédérale de Lausanne (EPFL), Lausanne 1015, Switzerland.
Proc Natl Acad Sci U S A. 2024 Dec 3;121(49):e2414955121. doi: 10.1073/pnas.2414955121. Epub 2024 Nov 26.
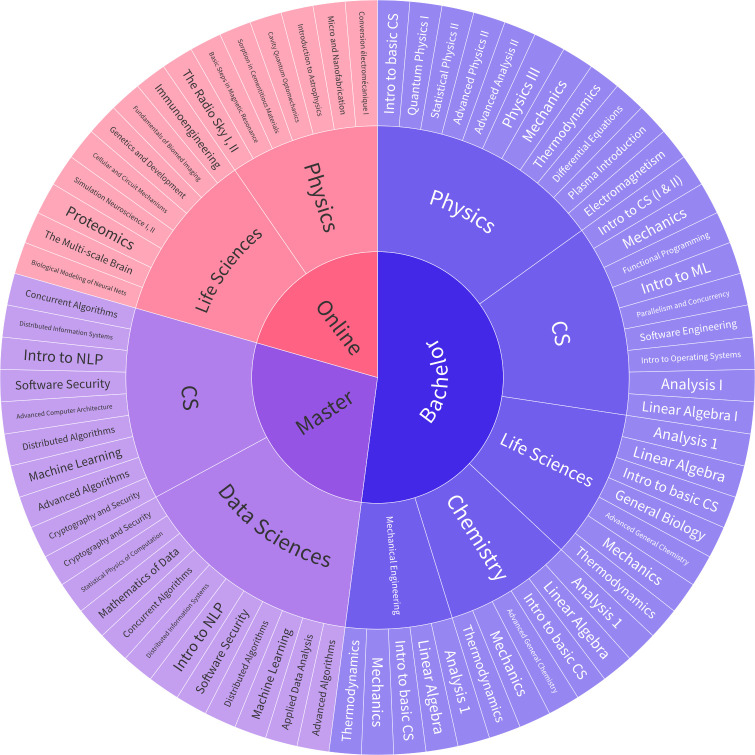
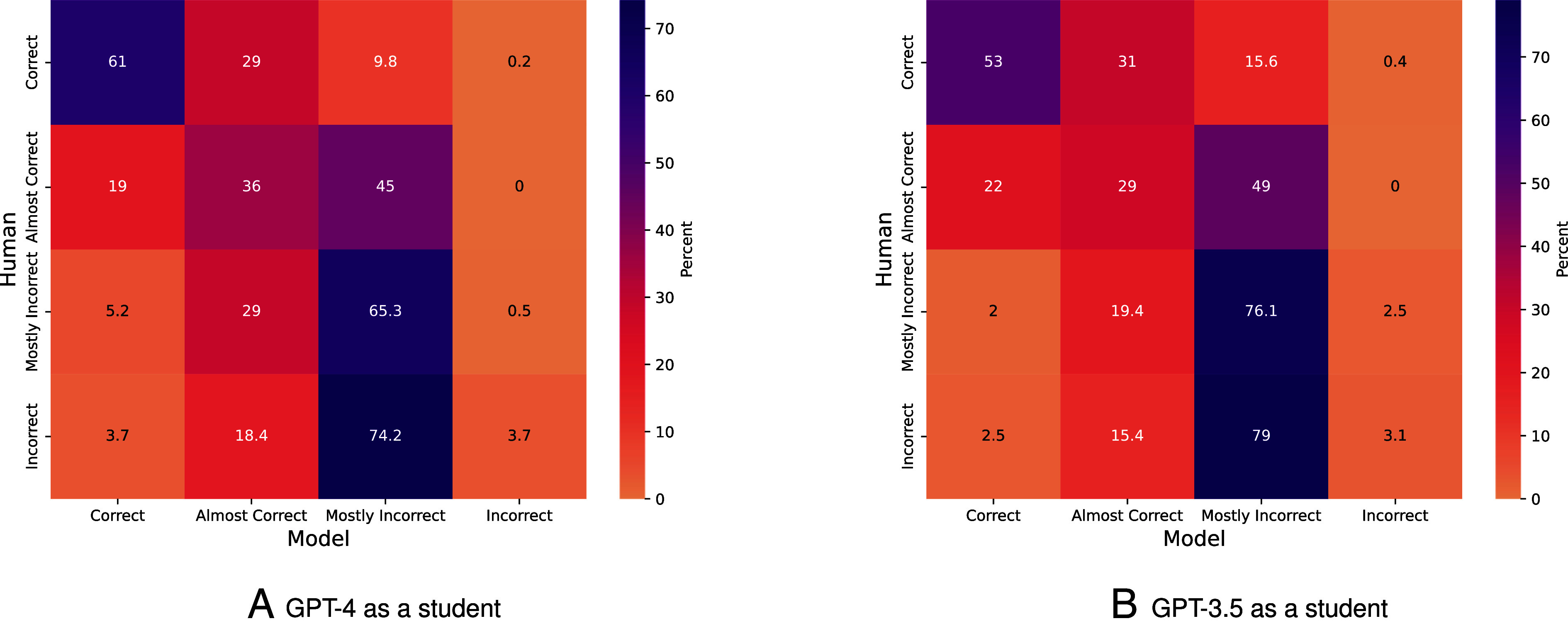
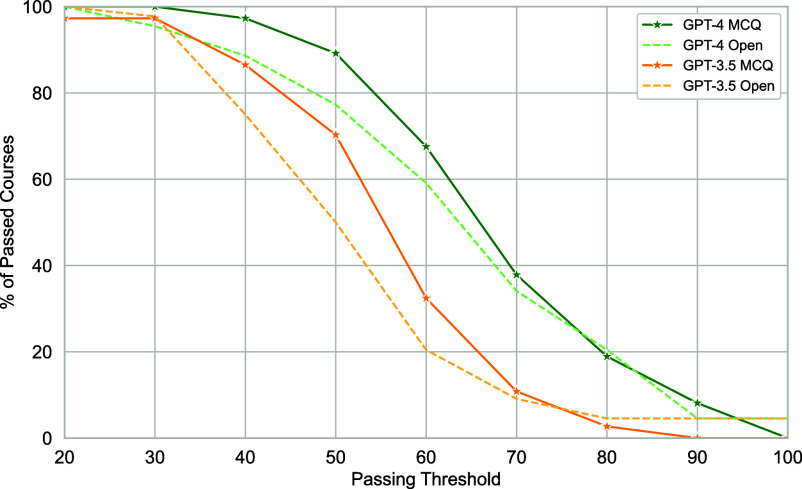
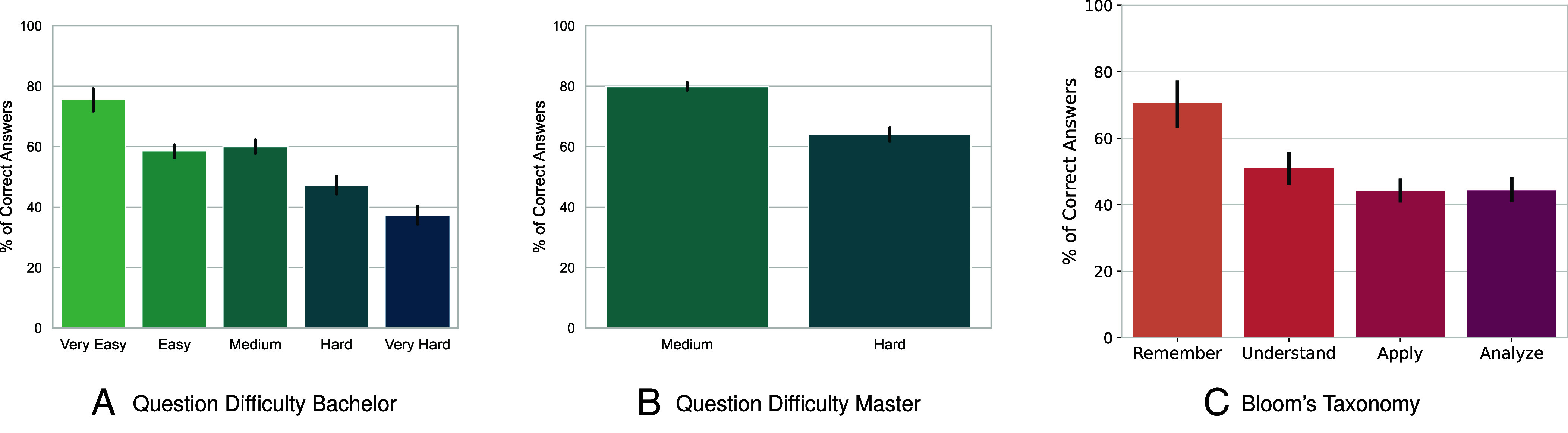
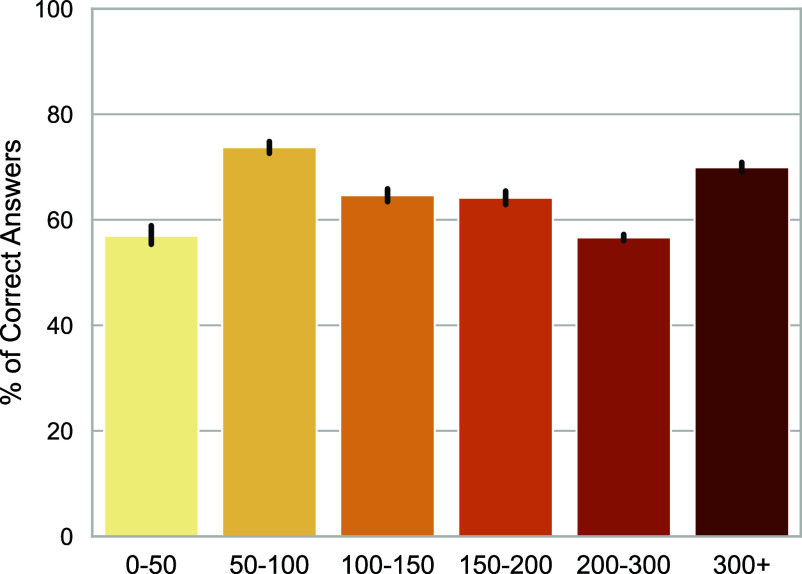
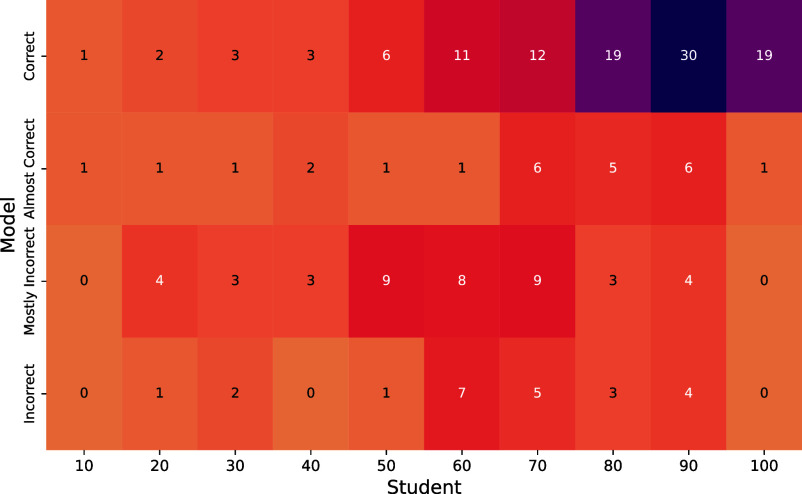
AI assistants, such as ChatGPT, are being increasingly used by students in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level Science, Technology, Engineering, and Mathematics (STEM) courses. Specifically, we compile a dataset of textual assessment questions from 50 courses at the École polytechnique fédérale de Lausanne (EPFL) and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass the nonproject assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
诸如ChatGPT这样的人工智能助手正越来越多地被高等教育机构的学生使用。虽然这些工具为改进教学和教育提供了机会,但它们也给评估和学习成果带来了重大挑战。我们从脆弱性的角度来概念化这些挑战,即大学评估和学习成果有可能受到学生使用生成式人工智能的影响。我们通过衡量人工智能助手在标准大学水平的科学、技术、工程和数学(STEM)课程中完成评估问题的程度,来调查这种脆弱性的潜在规模。具体而言,我们编制了洛桑联邦理工学院(EPFL)50门课程的文本评估问题数据集,并评估两个人工智能助手GPT-3.5和GPT-4能否充分回答这些问题。我们使用八种提示策略来生成回答,发现GPT-4平均能正确回答65.8%的问题,甚至在至少一种提示策略下,能对85.1%的问题给出正确答案。当我们数据集中的课程按学位项目分组时,这些系统已经通过了各个学位项目中大量核心课程的非项目评估,随着这些模型的改进,这对高等教育认证构成的风险将被放大。我们的研究结果呼吁根据生成式人工智能的进展,对高等教育中的项目级评估设计进行修订。