Park Sang Won, Park Ye-Lin, Lee Eun-Gyeong, Chae Heejung, Park Phillip, Choi Dong-Woo, Choi Yeon Ho, Hwang Juyeon, Ahn Seohyun, Kim Keunkyun, Kim Woo Jin, Kong Sun-Young, Jung So-Youn, Kim Hyun-Jin
Department of Medical Informatics, School of Medicine, Kangwon National University, Chuncheon 24341, Republic of Korea.
Institute of Medical Science, School of Medicine, Kangwon National University, Chuncheon 24341, Republic of Korea.
Cancers (Basel). 2024 Nov 12;16(22):3799. doi: 10.3390/cancers16223799.
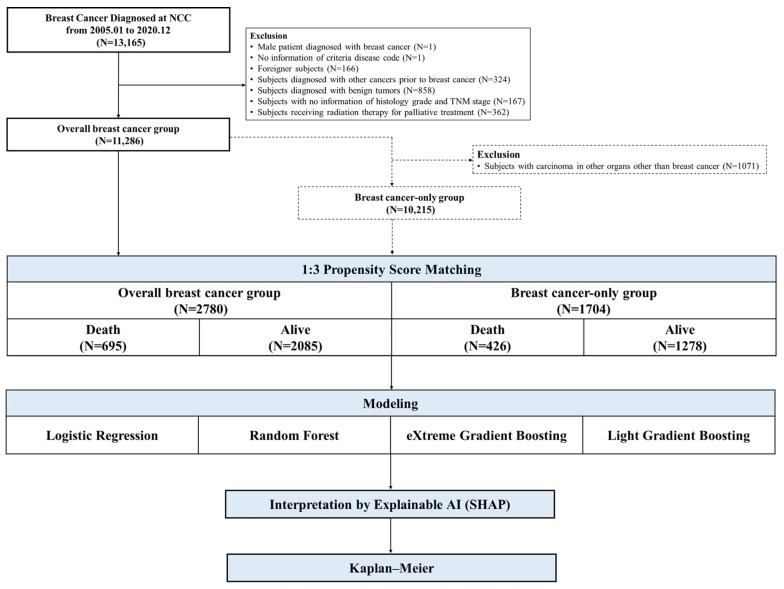
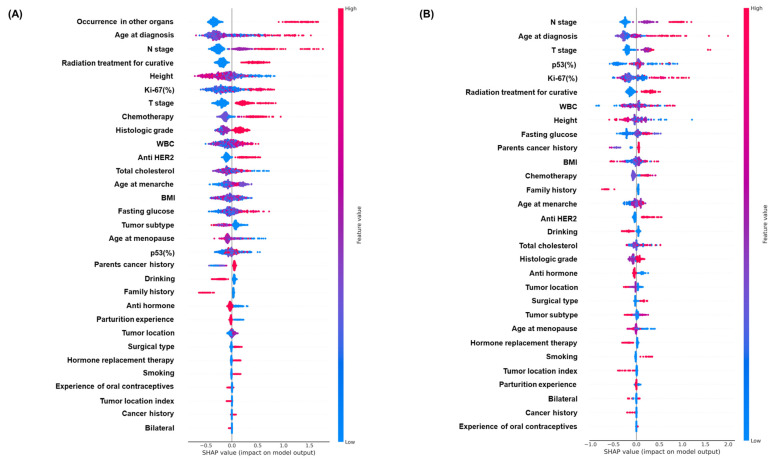
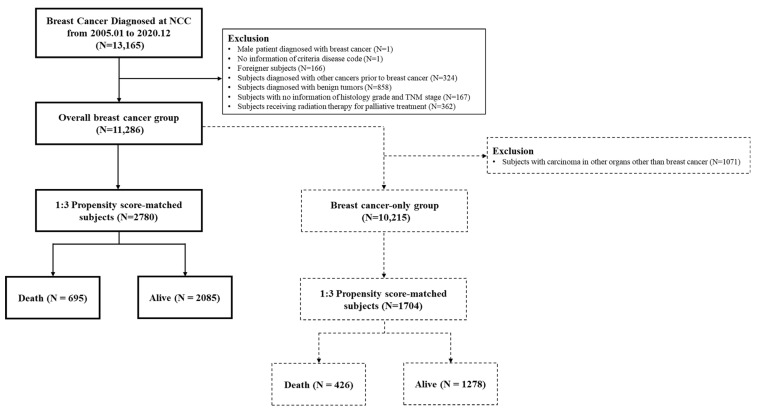
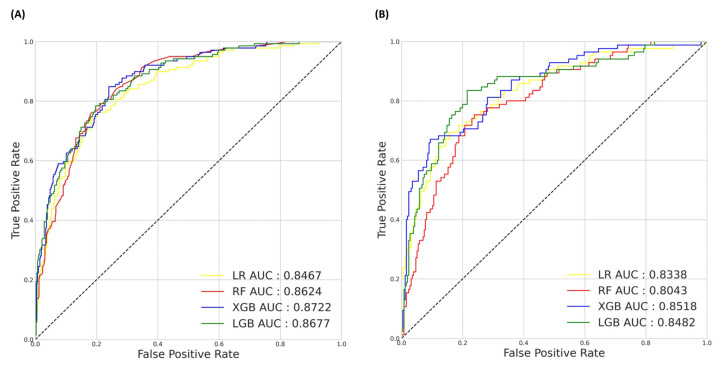
: Breast cancer is the most common cancer in women worldwide, requiring strategic efforts to reduce its mortality. This study aimed to develop a predictive classification model for breast cancer mortality using real-world data, including various clinical features. : A total of 11,286 patients with breast cancer from the National Cancer Center were included in this study. The mortality rate of the total sample was approximately 6.2%. Propensity score matching was used to reduce bias. Several machine learning models, including extreme gradient boosting, were applied to 31 clinical features. To enhance model interpretability, we used the SHapley Additive exPlanations method. ML analyses were also performed on the samples, excluding patients who developed other cancers after breast cancer. : Among the ML models, the XGB model exhibited the highest discriminatory power, with an area under the curve of 0.8722 and a specificity of 0.9472. Key predictors of the mortality classification model included occurrence in other organs, age at diagnosis, N stage, T stage, curative radiation treatment, and Ki-67(%). Even after excluding patients who developed other cancers after breast cancer, the XGB model remained the best-performing, with an AUC of 0.8518 and a specificity of 0.9766. Additionally, the top predictors from SHAP were similar to the results for the overall sample. : Our models provided excellent predictions of breast cancer mortality using real-world data from South Korea. Explainable artificial intelligence, such as SHAP, validated the clinical applicability and interpretability of these models.
乳腺癌是全球女性中最常见的癌症,需要采取战略措施降低其死亡率。本研究旨在利用包括各种临床特征在内的真实世界数据,开发一种用于预测乳腺癌死亡率的分类模型。
本研究纳入了国家癌症中心的11286例乳腺癌患者。总样本的死亡率约为6.2%。采用倾向得分匹配法减少偏差。将包括极端梯度提升在内的几种机器学习模型应用于31项临床特征。为了提高模型的可解释性,我们使用了SHapley加性解释方法。还对样本进行了机器学习分析,排除了乳腺癌后发生其他癌症的患者。
在机器学习模型中,XGB模型表现出最高的区分能力,曲线下面积为0.8722,特异性为0.9472。死亡率分类模型的关键预测因素包括其他器官的发生情况、诊断时的年龄、N分期、T分期、根治性放射治疗和Ki-67(%)。即使排除了乳腺癌后发生其他癌症的患者,XGB模型仍然是表现最佳的,曲线下面积为0.8518,特异性为0.9766。此外,SHAP的顶级预测因素与总体样本的结果相似。
我们的模型利用韩国的真实世界数据对乳腺癌死亡率进行了出色的预测。诸如SHAP之类的可解释人工智能验证了这些模型的临床适用性和可解释性。