Ding Rong, He Shiqi, Wu Xuemei, Zhong Liwen, Chen Guopeng, Gu Rui
State Key Laboratory of Southwestern Chinese Medicine Resources, School of Ethnic Medicine, Chengdu University of Traditional Chinese Medicine, Chengdu, China.
School of Pharmacy, Chengdu University of Traditional Chinese Medicine, Chengdu, China.
Front Pharmacol. 2024 Nov 18;15:1503508. doi: 10.3389/fphar.2024.1503508. eCollection 2024.
The scarcity and preciousness of plateau characteristic medicinal plants pose a significant challenge in obtaining sufficient quantities of experimental samples for quality evaluation. Insufficient sample sizes often lead to ambiguous and questionable quality assessments and suboptimal performance in pattern recognition. Shilajit, a popular Tibetan medicine, is harvested from high altitudes above 2000 m, making it difficult to obtain. Additionally, the complex geographical environment results in low uniformity of Shilajit quality.
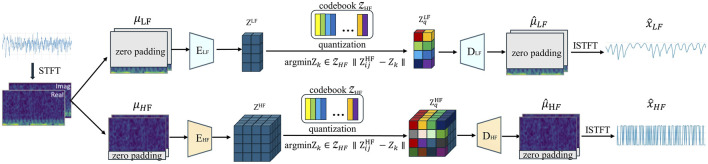
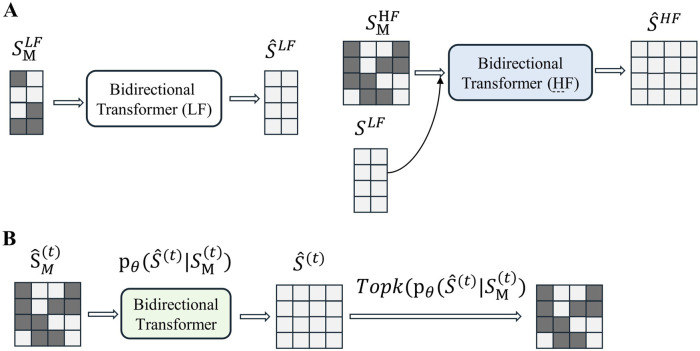
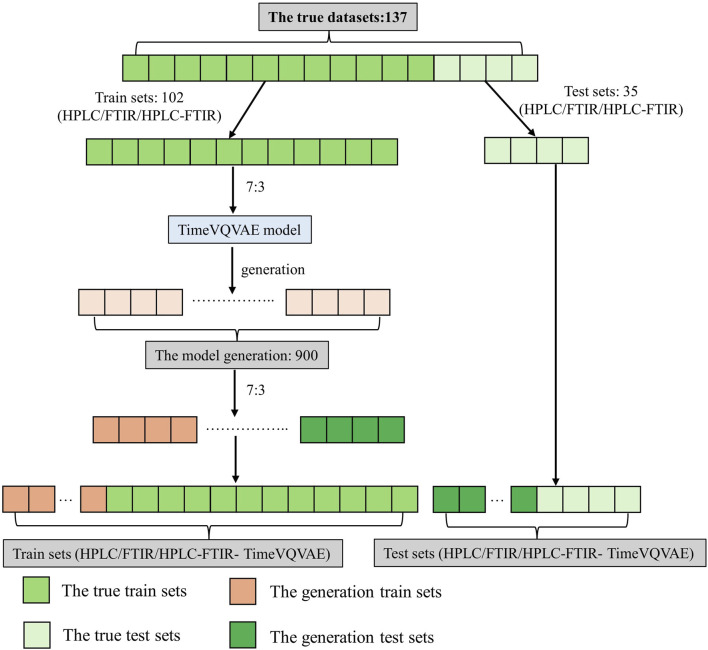
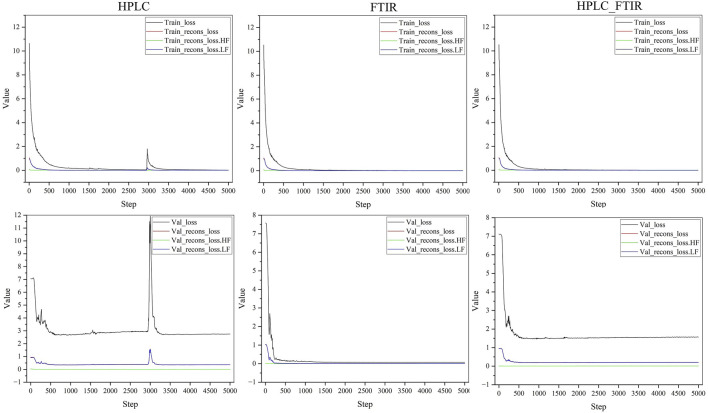
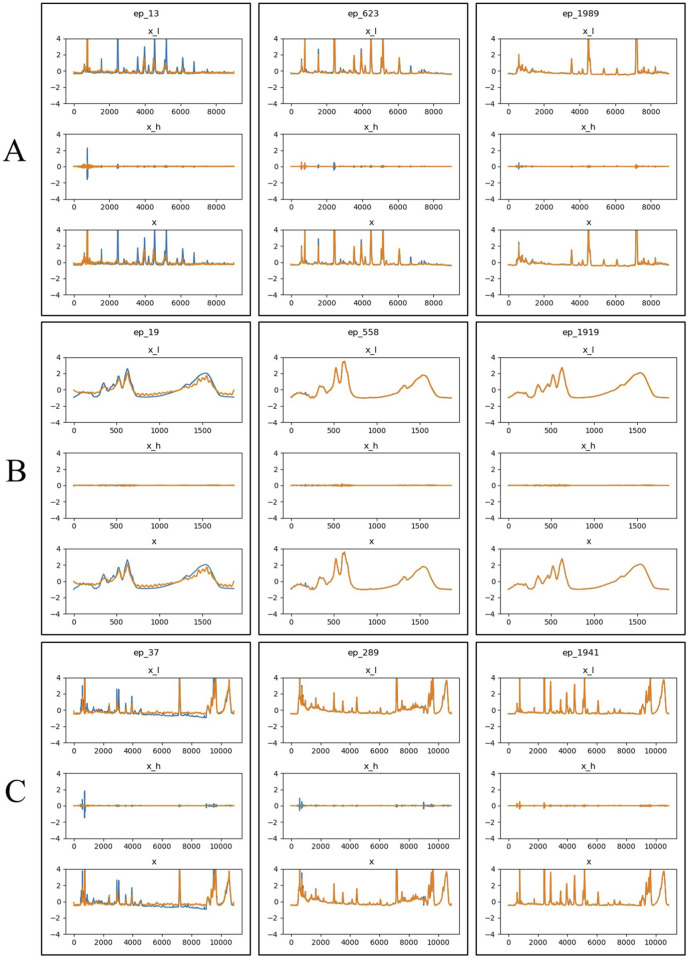
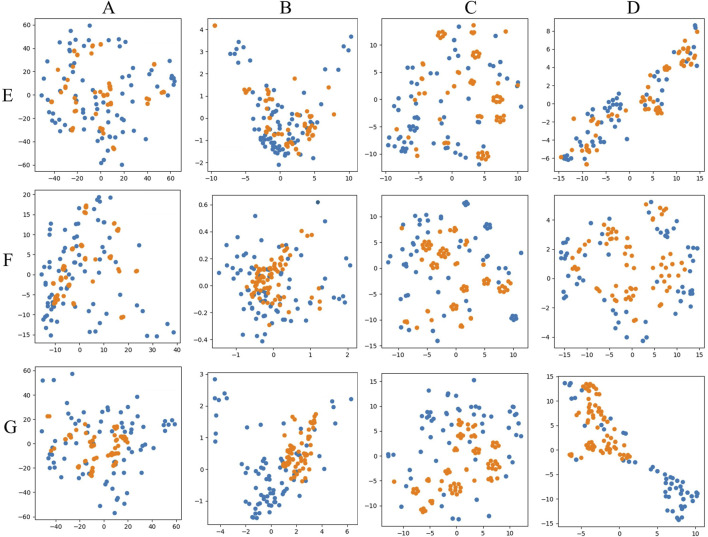
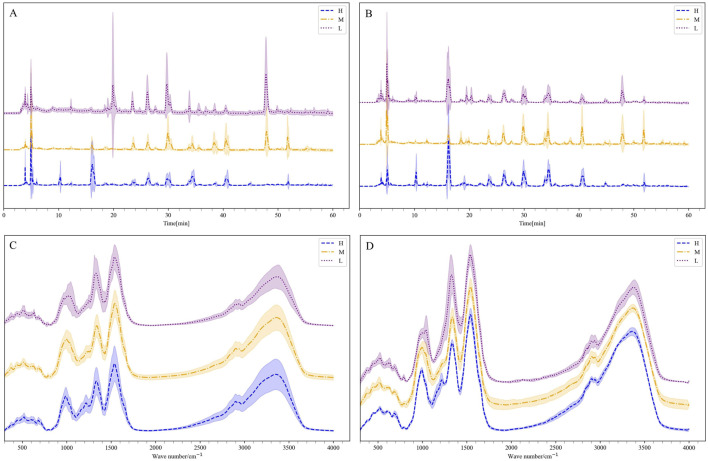
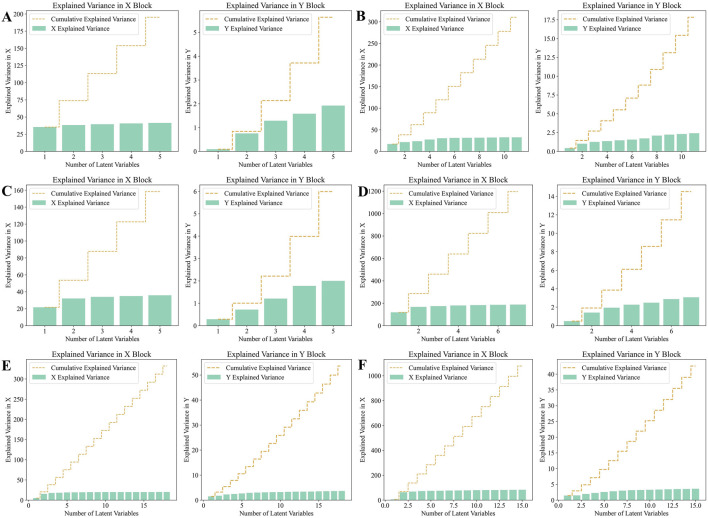
To address these challenges, this study employed a deep learning model, time vector quantization variational auto- encoder (TimeVQVAE), to generate data matrices based on chromatographic and spectral for different grades of Shilajit, thereby increasing in the amount of data. Partial least squares discriminant analysis (PLS-DA) was used to identify three grades of Shilajit samples based on original, generated, and combined data.
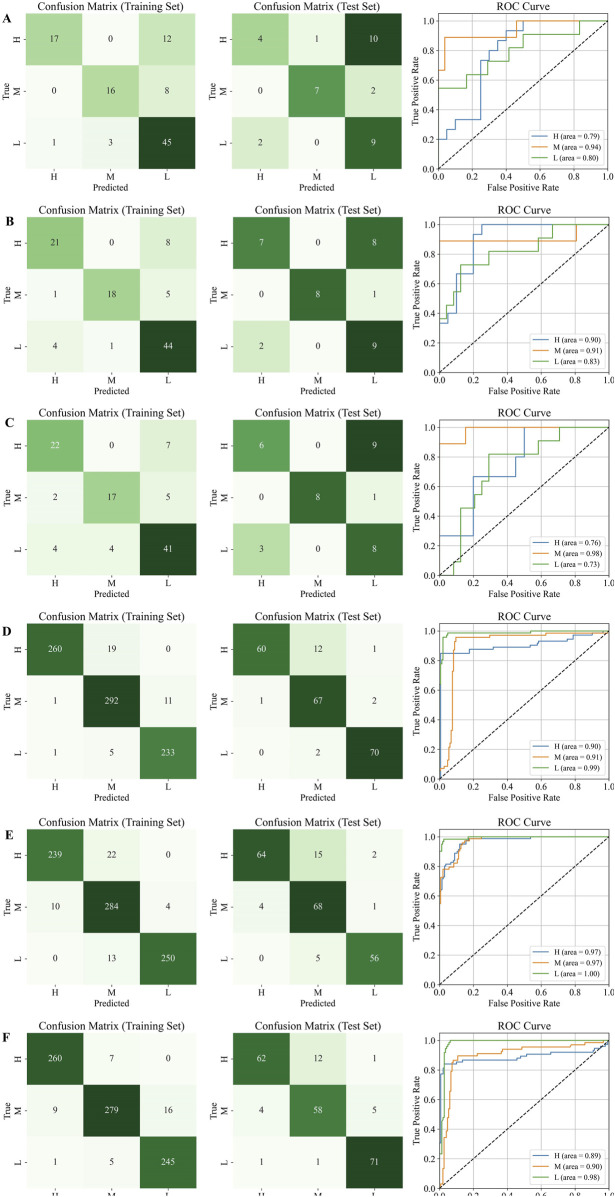
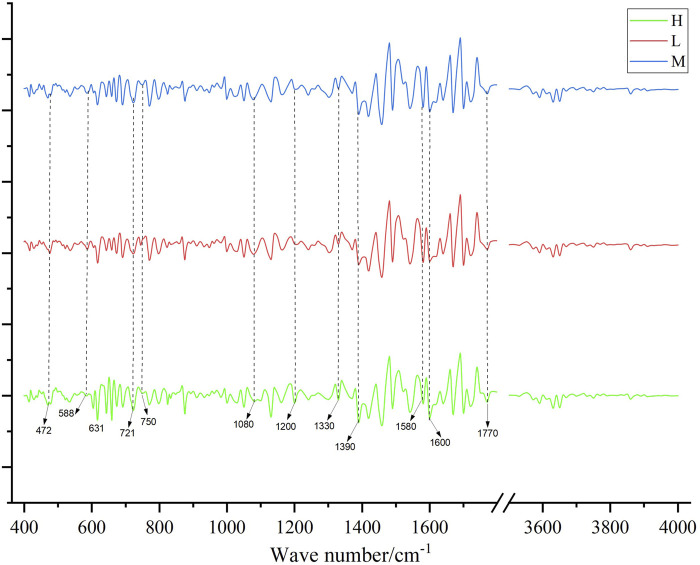
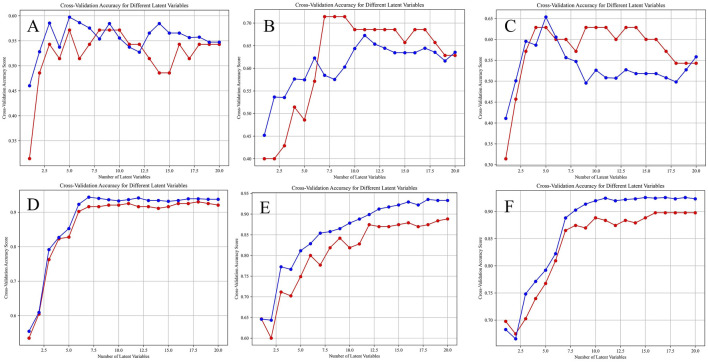
Compared with the originally generated high performance liquid chromatography (HPLC) and Fourier transform infrared spectroscopy (FTIR) data, the data generated by TimeVQVAE effectively preserved the chemical profile. In the test set, the average matrices for HPLC, FTIR, and combined data increased by 32.2%, 15.9%, and 23.0%, respectively. On the real test data, the PLS-DA model's classification accuracy initially reached a maximum of 0.7905. However, after incorporating TimeVQVAE-generated data, the accuracy significantly improved, reaching 0.9442 in the test set. Additionally, the PLS-DA model trained with the fused data showed enhanced stability.
This study offers a novel and effective approach for researching medicinal materials with small sample sizes, and addresses the limitations of improving model performance through data augmentation strategies.
高原特色药用植物的稀缺性和珍贵性给获取足够数量的实验样品以进行质量评估带来了重大挑战。样本量不足往往导致质量评估模糊且不可靠,以及模式识别性能欠佳。希拉季特是一种广受欢迎的藏药,采自海拔2000米以上的高海拔地区,难以获取。此外,复杂的地理环境导致希拉季特质量的均匀性较低。
为应对这些挑战,本研究采用深度学习模型——时间矢量量化变分自编码器(TimeVQVAE),基于不同等级希拉季特的色谱和光谱数据生成数据矩阵,从而增加数据量。偏最小二乘判别分析(PLS-DA)用于基于原始数据、生成数据和组合数据识别三个等级的希拉季特样本。
与最初生成的高效液相色谱(HPLC)和傅里叶变换红外光谱(FTIR)数据相比,TimeVQVAE生成的数据有效地保留了化学特征。在测试集中,HPLC、FTIR和组合数据的平均矩阵分别增加了32.2%、15.9%和23.0%。在实际测试数据上,PLS-DA模型的分类准确率最初最高达到0.7905。然而,在纳入TimeVQVAE生成的数据后,准确率显著提高,在测试集中达到0.9442。此外,用融合数据训练的PLS-DA模型显示出更高的稳定性。
本研究为小样本量药用材料的研究提供了一种新颖有效的方法,并解决了通过数据增强策略提高模型性能的局限性。