Alabduljabbar Reham
Information Technology Department, College of Computer and Information Sciences, King Saud University, Riyadh, Saudi Arabia.
PeerJ Comput Sci. 2024 Oct 25;10:e2421. doi: 10.7717/peerj-cs.2421. eCollection 2024.
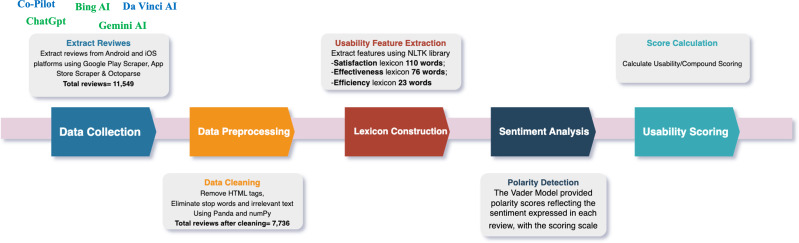
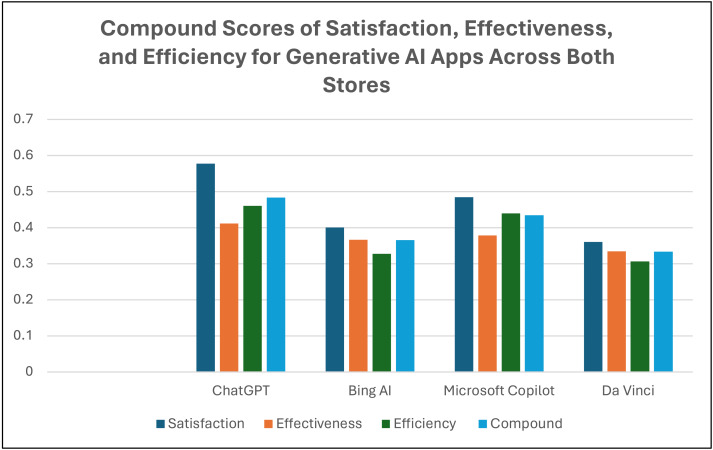
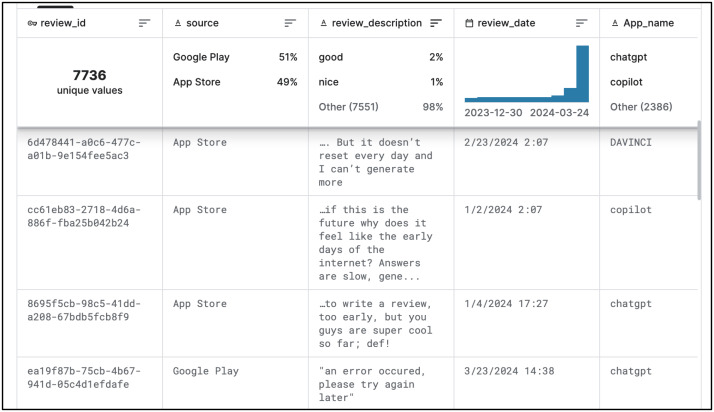
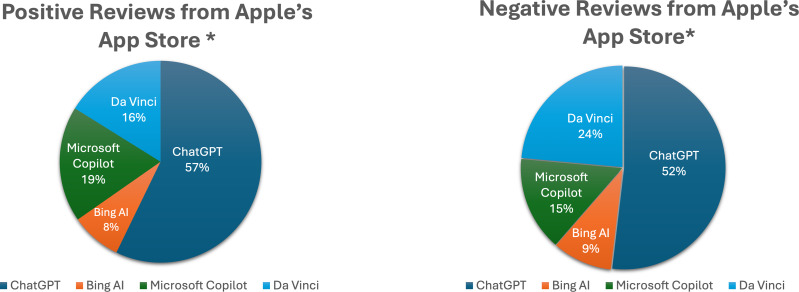
This article presents a usability evaluation and comparison of generative AI applications through the analysis of user reviews from popular digital marketplaces, specifically Apple's App Store and Google Play. The study aims to bridge the research gap in real-world usability assessments of generative AI tools. A total of 11,549 reviews were extracted and analyzed from January to March 2024 for five generative AI apps: ChatGPT, Bing AI, Microsoft Copilot, Gemini AI, and Da Vinci AI. The dataset has been made publicly available, allowing for further analysis by other researchers. The evaluation follows ISO 9241 usability standards, focusing on effectiveness, efficiency, and user satisfaction. This study is believed to be the first usability evaluation for generative AI applications using user reviews across digital marketplaces. The results show that ChatGPT achieved the highest compound usability scores among Android and iOS users, with scores of 0.504 and 0.462, respectively. Conversely, Gemini AI scored the lowest among Android apps at 0.016, and Da Vinci AI had the lowest among iOS apps at 0.275. Satisfaction scores were critical in usability assessments, with ChatGPT obtaining the highest rates of 0.590 for Android and 0.565 for iOS, while Gemini AI had the lowest satisfaction rate at -0.138 for Android users. The findings revealed usability issues related to ease of use, functionality, and reliability in generative AI tools, providing valuable insights from user opinions and feedback. Based on the analysis, actionable recommendations were proposed to enhance the usability of generative AI tools, aiming to address identified usability issues and improve the overall user experience. This study contributes to a deeper understanding of user experiences and offers valuable guidance for enhancing the usability of generative AI applications.
本文通过分析来自热门数字市场(具体为苹果应用商店和谷歌应用商店)的用户评论,对生成式人工智能应用程序进行了可用性评估和比较。该研究旨在弥合生成式人工智能工具在实际可用性评估方面的研究差距。2024年1月至3月,共提取并分析了11549条针对五款生成式人工智能应用程序的评论:ChatGPT、必应人工智能、微软Copilot、Gemini人工智能和达芬奇人工智能。该数据集已公开提供,供其他研究人员进一步分析。评估遵循ISO 9241可用性标准,重点关注有效性、效率和用户满意度。据信,这项研究是首次利用跨数字市场的用户评论对生成式人工智能应用程序进行可用性评估。结果显示,ChatGPT在安卓和iOS用户中获得了最高的综合可用性得分,分别为0.504和0.462。相反,Gemini人工智能在安卓应用中得分最低,为0.016,而达芬奇人工智能在iOS应用中得分最低,为0.275。满意度得分在可用性评估中至关重要,ChatGPT在安卓系统中的满意度得分最高,为0.590,在iOS系统中为0.565,而Gemini人工智能在安卓用户中的满意度得分最低,为-0.138。研究结果揭示了生成式人工智能工具在易用性、功能和可靠性方面的可用性问题,从用户意见和反馈中提供了有价值的见解。基于分析,提出了可操作的建议,以提高生成式人工智能工具的可用性,旨在解决已识别的可用性问题并改善整体用户体验。这项研究有助于更深入地理解用户体验,并为提高生成式人工智能应用程序的可用性提供有价值的指导。