Han Hyejung, Choi Yoon Hee, Kim Si Yeong, Park Jung Hwa, Chung Jin, Na Hee Sam
Department of Oral Microbiology, School of Dentistry, Pusan National University, Yangsan, Republic of Korea.
Department of Internal Medicine, Dongnam Institute of Radiological and Medical Sciences, Busan, Republic of Korea.
Front Microbiol. 2024 Nov 25;15:1485073. doi: 10.3389/fmicb.2024.1485073. eCollection 2024.
The study of the human microbiome is crucial for understanding disease mechanisms, identifying biomarkers, and guiding preventive measures. Advances in sequencing platforms, particularly 16S rRNA sequencing, have revolutionized microbiome research. Despite the benefits, large microbiome reference databases (DBs) pose challenges, including computational demands and potential inaccuracies. This study aimed to determine if full-length 16S rRNA sequencing data produced by PacBio could be used to optimize reference DBs and be applied to Illumina V3-V4 targeted sequencing data for microbial study.
Oral and gut microbiome data (PRJNA1049979) were retrieved from NCBI. DADA2 was applied to full-length 16S rRNA PacBio data to obtain amplicon sequencing variants (ASVs). The RDP reference DB was used to assign the ASVs, which were then used as a reference DB to train the classifier. QIIME2 was used for V3-V4 targeted Illumina data analysis. BLAST was used to analyze alignment statistics. Linear discriminant analysis Effect Size (LEfSe) was employed for discriminant analysis.
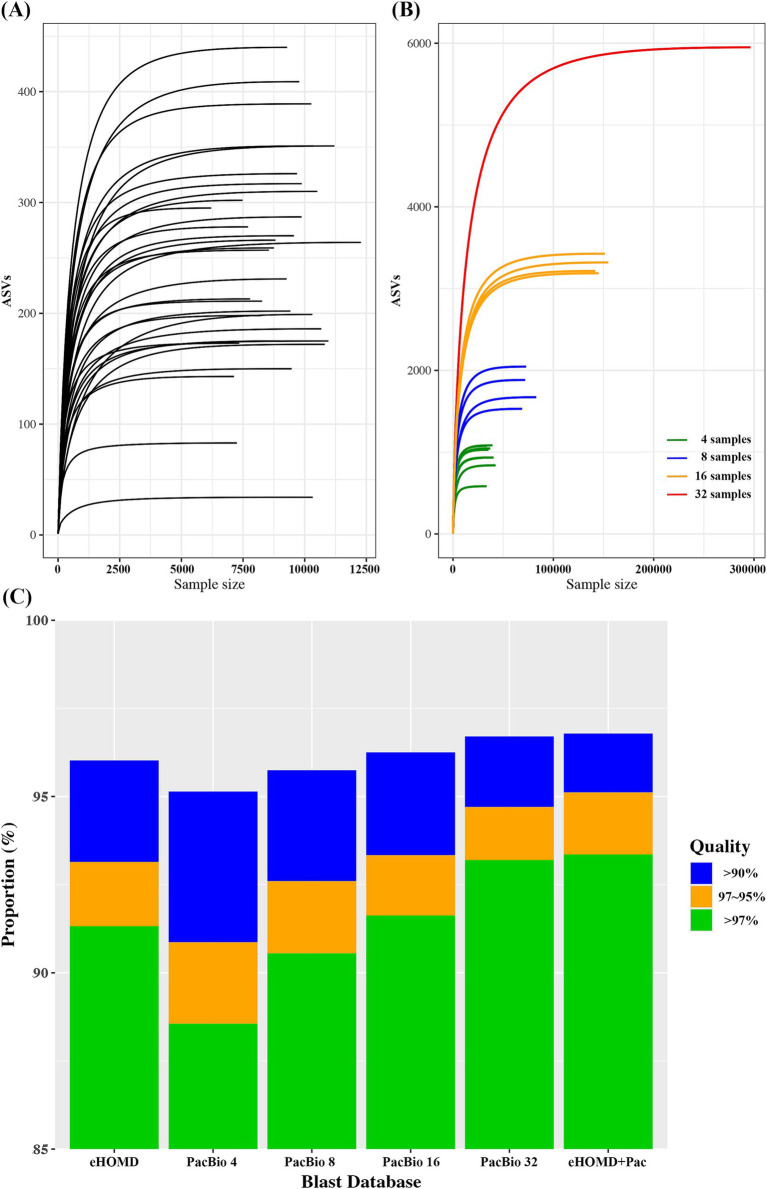
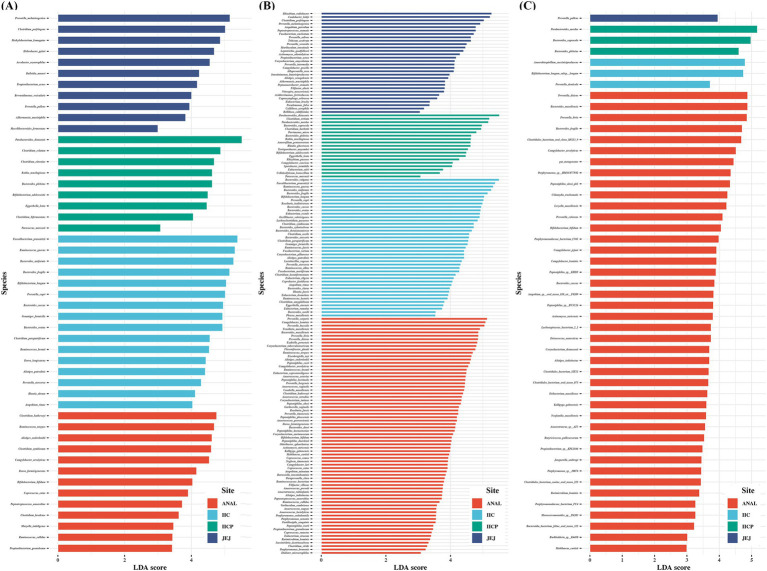
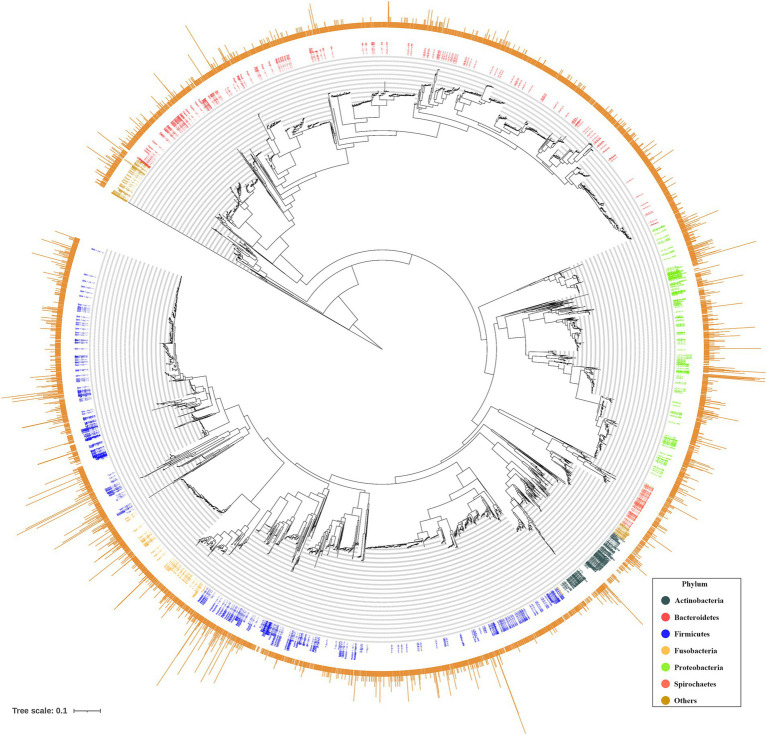
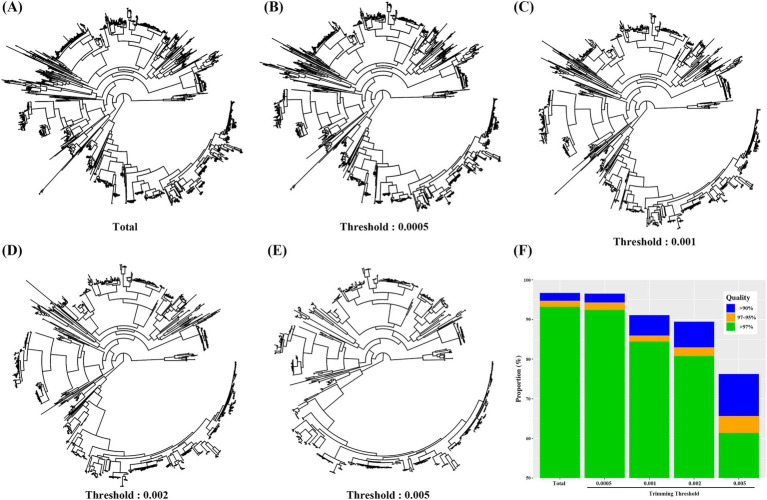
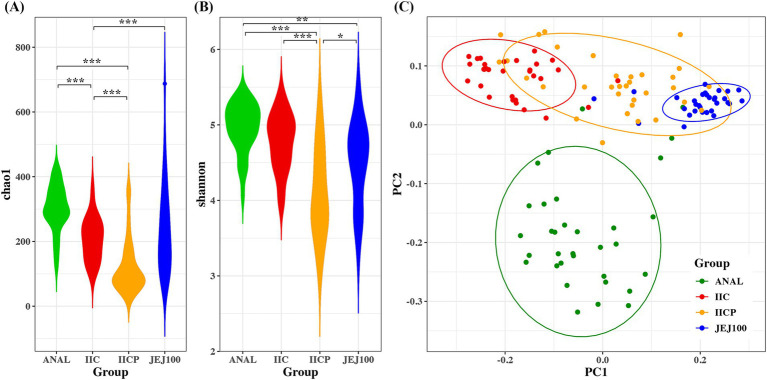
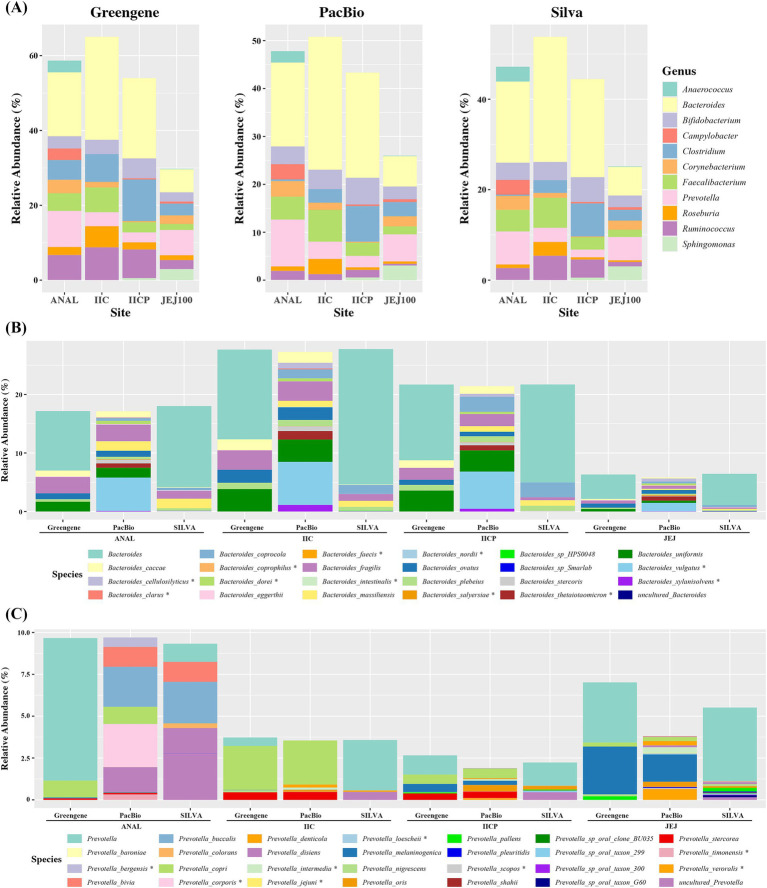
ASVs produced by PacBio showed coverage of the oral microbiome similar to the Human Oral Microbiome Database. A phylogenetic tree was trimmed at various thresholds to obtain an optimized reference DB. This established method was then applied to gut microbiome data, and the optimized gut microbiome reference DB provided improved taxa classification and biomarker discovery efficiency.
Full-length 16S rRNA sequencing data produced by PacBio can be used to construct a microbiome reference DB. Utilizing an optimized reference DB can increase the accuracy of microbiome classification and enhance biomarker discovery.
人类微生物组的研究对于理解疾病机制、识别生物标志物和指导预防措施至关重要。测序平台的进步,尤其是16S rRNA测序,彻底改变了微生物组研究。尽管有这些好处,但大型微生物组参考数据库带来了挑战,包括计算需求和潜在的不准确。本研究旨在确定PacBio产生的全长16S rRNA测序数据是否可用于优化参考数据库,并应用于Illumina V3-V4靶向测序数据以进行微生物研究。
从NCBI检索口腔和肠道微生物组数据(PRJNA1049979)。将DADA2应用于全长16S rRNA PacBio数据以获得扩增子测序变体(ASV)。使用RDP参考数据库对ASV进行分类,然后将其用作参考数据库来训练分类器。使用QIIME2进行V3-V4靶向Illumina数据分析。使用BLAST分析比对统计。采用线性判别分析效应大小(LEfSe)进行判别分析。
PacBio产生的ASV显示出与人类口腔微生物组数据库相似的口腔微生物组覆盖率。在不同阈值下修剪系统发育树以获得优化的参考数据库。然后将此既定方法应用于肠道微生物组数据,优化后的肠道微生物组参考数据库提高了分类单元分类和生物标志物发现效率。
PacBio产生的全长16S rRNA测序数据可用于构建微生物组参考数据库。利用优化的参考数据库可以提高微生物组分类的准确性并增强生物标志物发现。