Gallo Robert J, Baiocchi Michael, Savage Thomas R, Chen Jonathan H
Center for Innovation to Implementation, VA Palo Alto Health Care System, Menlo Park, CA 94025, United States.
Department of Health Policy, Stanford University, Stanford, CA 94305, United States.
J Am Med Inform Assoc. 2025 Feb 1;32(2):386-390. doi: 10.1093/jamia/ocae294.
We aimed to demonstrate the importance of establishing best practices in large language model research, using repeat prompting as an illustrative example.
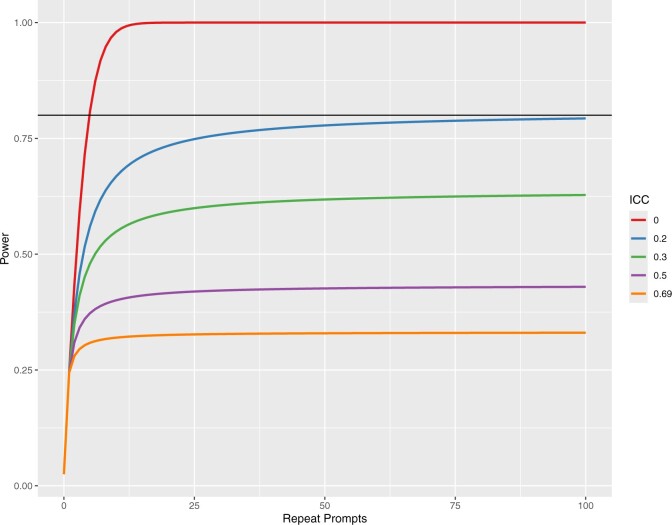
Using data from a prior study investigating potential model bias in peer review of medical abstracts, we compared methods that ignore correlation in model outputs from repeated prompting with a random effects method that accounts for this correlation.
High correlation within groups was found when repeatedly prompting the model, with intraclass correlation coefficient of 0.69. Ignoring the inherent correlation in the data led to over 100-fold inflation of effective sample size. After appropriately accounting for this issue, the authors' results reverse from a small but highly significant finding to no evidence of model bias.
The establishment of best practices for LLM research is urgently needed, as demonstrated in this case where accounting for repeat prompting in analyses was critical for accurate study conclusions.
我们旨在以重复提示为例,证明在大语言模型研究中建立最佳实践的重要性。
利用先前一项调查医学摘要同行评审中潜在模型偏差的研究数据,我们将忽略重复提示模型输出中的相关性的方法与考虑这种相关性的随机效应方法进行了比较。
对模型进行重复提示时,组内发现高度相关性,组内相关系数为0.69。忽略数据中固有的相关性导致有效样本量膨胀超过100倍。在适当考虑这个问题后,作者的结果从小而高度显著的发现转变为没有模型偏差的证据。
迫切需要建立大语言模型研究的最佳实践,如本例所示,在分析中考虑重复提示对于得出准确的研究结论至关重要。