Sun Yilan, Cheng Guozhen, Wei Dongliang, Luo Jiacheng, Liu Jiannan
Department of Oral and Maxillofacial Head and Neck Oncology, Shanghai Ninth People's Hospital, Shanghai Jiao Tong University School of Medicine, Shanghai, China.
College of Stomatology, Shanghai Jiao Tong University, Shanghai, China.
Front Immunol. 2024 Dec 3;15:1493377. doi: 10.3389/fimmu.2024.1493377. eCollection 2024.
Early detection of oral squamous cell carcinoma (OSCC) is critical for improving clinical outcomes. Precision diagnostics integrating metabolomics and machine learning offer promising non-invasive solutions for identifying tumor-derived biomarkers.
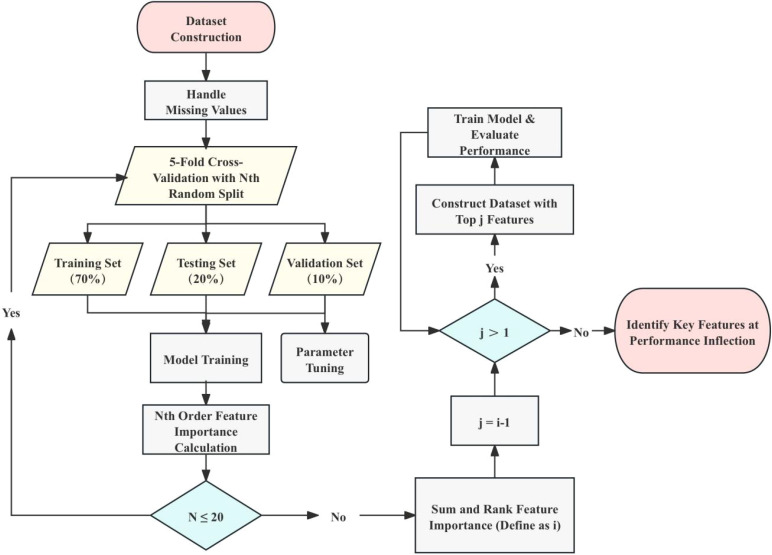
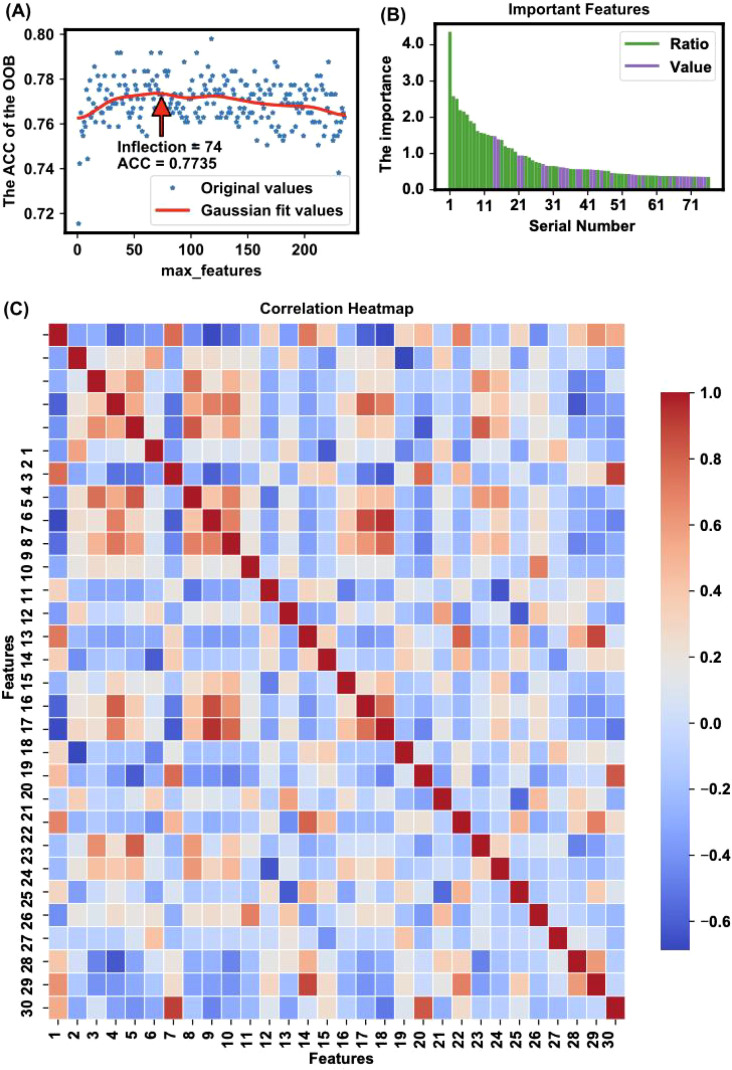
We analyzed a multicenter public dataset comprising 61 OSCC patients and 61 healthy controls. Plasma metabolomics data were processed to extract 29 numerical and 47 ratio features. The Extra Trees (ET) algorithm was applied for feature selection, and the TabPFN model was used for classification and prediction.
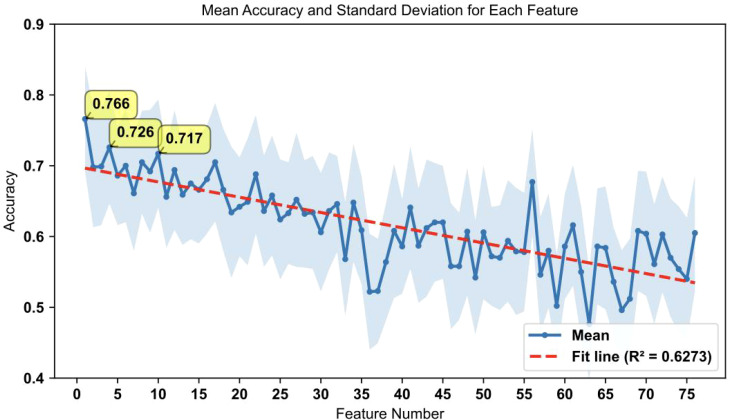
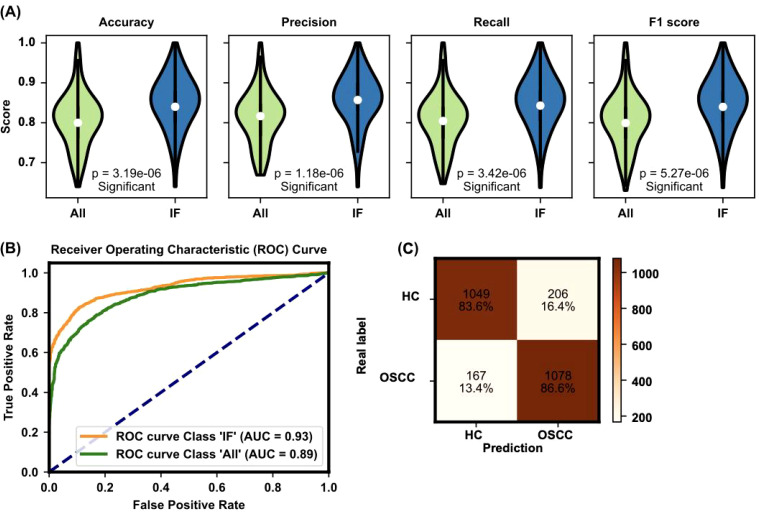
The model achieved an area under the curve (AUC) of 93% and an overall accuracy of 76.6% when using top-ranked individual biomarkers. Key metabolic features significantly differentiated OSCC patients from healthy controls, providing a detailed metabolic fingerprint of the disease.
Our findings demonstrate the utility of integrating omics data with advanced machine learning techniques to develop accurate, non-invasive diagnostic tools for OSCC. The study highlights actionable metabolic signatures that have potential applications in personalized therapeutics and early intervention strategies.
早期发现口腔鳞状细胞癌(OSCC)对于改善临床结果至关重要。整合代谢组学和机器学习的精准诊断为识别肿瘤衍生生物标志物提供了有前景的非侵入性解决方案。
我们分析了一个多中心公共数据集,其中包括61名OSCC患者和61名健康对照。对血浆代谢组学数据进行处理,以提取29个数值特征和47个比率特征。应用Extra Trees(ET)算法进行特征选择,并使用TabPFN模型进行分类和预测。
当使用排名靠前的单个生物标志物时,该模型的曲线下面积(AUC)为93%,总体准确率为76.6%。关键代谢特征显著区分了OSCC患者与健康对照,提供了该疾病详细的代谢指纹。
我们的研究结果证明了将组学数据与先进的机器学习技术相结合,以开发用于OSCC的准确、非侵入性诊断工具的实用性。该研究突出了可操作的代谢特征,这些特征在个性化治疗和早期干预策略中具有潜在应用。