Fan Zijuan, Song Wenzhu, Ke Yan, Jia Ligan, Li Songyan, Li Jiao Jiao, Zhang Yuqing, Lin Jianhao, Wang Bin
Department of Orthopaedic Surgery, The First Affiliated Hospital, Zhejiang University School of Medicine, Qingchun Road No. 79, Hangzhou, China.
Department of Health Statistics, School of Public Health, Sun Yat-sen University, Guangzhou, China.
Arthritis Res Ther. 2024 Dec 19;26(1):213. doi: 10.1186/s13075-024-03450-2.
To use routine demographic and clinical data to develop an interpretable individual-level machine learning (ML) model to diagnose knee osteoarthritis (KOA) and to identify highly ranked features.
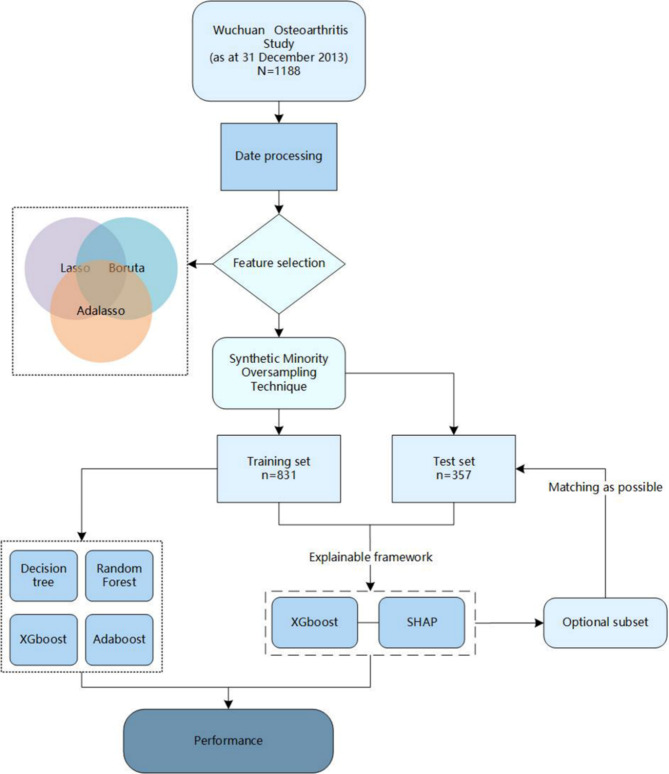
In this retrospective, population-based cohort study, anonymized questionnaire data was retrieved from the Wu Chuan KOA Study, Inner Mongolia, China. After feature selections, participants were divided in a 7:3 ratio into training and test sets. Class balancing was applied to the training set for data augmentation. Four ML classifiers were compared by cross-validation within the training set and their performance was further analyzed with an unseen test set. Classifications were evaluated using sensitivity, specificity, positive predictive value, negative predictive value, accuracy, area under the curve(AUC), G-means, and F1 scores. The best model was explained using Shapley values to extract highly ranked features.
A total of 1188 participants were investigated in this study, among whom 26.3% were diagnosed with KOA. Comparatively, XGBoost with Boruta exhibited the highest classification performance among the four models, with an AUC of 0.758, G-means of 0.800, and F1 scores of 0.703. The SHAP method reveals the top 17 features of KOA according to the importance ranking, and the average of the experience of joint pain was recognized as the most important features.
Our study highlights the usefulness of machine learning in unveiling important factors that influence the diagnosis of KOA to guide new prevention strategies. Further work is needed to validate this approach.
利用常规人口统计学和临床数据开发一种可解释的个体水平机器学习(ML)模型,以诊断膝关节骨关节炎(KOA)并识别排名靠前的特征。
在这项基于人群的回顾性队列研究中,从中国内蒙古武川KOA研究中检索匿名问卷数据。经过特征选择后,参与者以7:3的比例分为训练集和测试集。对训练集应用类平衡进行数据增强。在训练集内通过交叉验证比较了四种ML分类器,并使用未见过的测试集进一步分析了它们的性能。使用灵敏度、特异度、阳性预测值、阴性预测值、准确度、曲线下面积(AUC)、G均值和F1分数评估分类。使用Shapley值解释最佳模型以提取排名靠前的特征。
本研究共调查了1188名参与者,其中26.3%被诊断为KOA。相比之下,带有Boruta的XGBoost在四个模型中表现出最高的分类性能,AUC为0.758,G均值为0.800,F1分数为0.703。SHAP方法根据重要性排名揭示了KOA的前17个特征,关节疼痛经历的平均值被认为是最重要的特征。
我们的研究强调了机器学习在揭示影响KOA诊断的重要因素以指导新的预防策略方面的有用性。需要进一步的工作来验证这种方法。