Schwerdtner Paul, Law Frederick, Wang Qing, Gazen Cenk, Chen Yi-Fan, Ihme Matthias, Peherstorfer Benjamin
Courant Institute of Mathematical Sciences, New York University, 251 Mercer Street, New York, NY 10012, USA.
Google Research, Mountain View, CA 94043, USA.
PNAS Nexus. 2024 Dec 10;3(12):pgae554. doi: 10.1093/pnasnexus/pgae554. eCollection 2024 Dec.
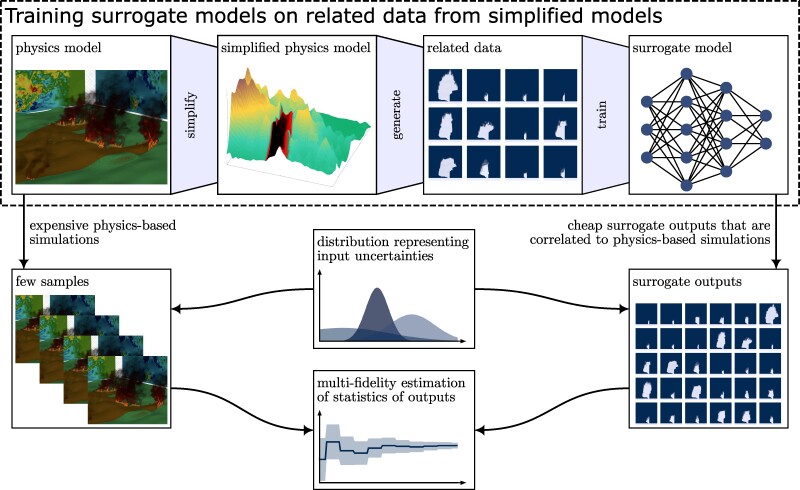
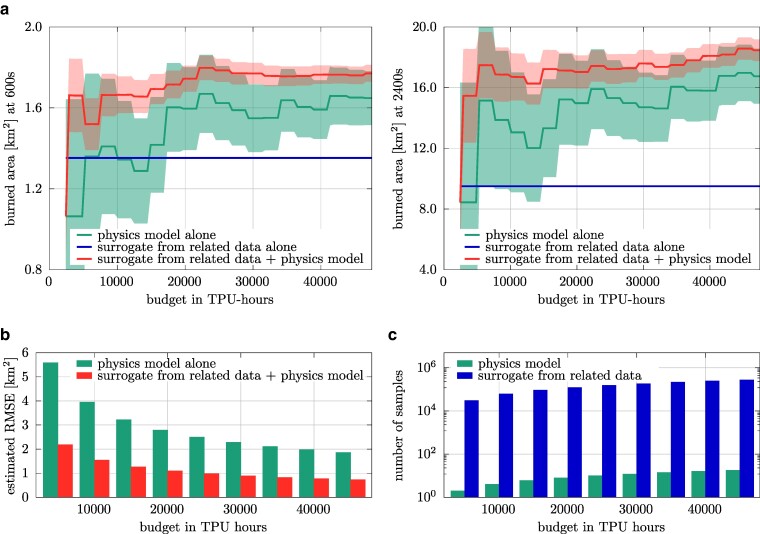
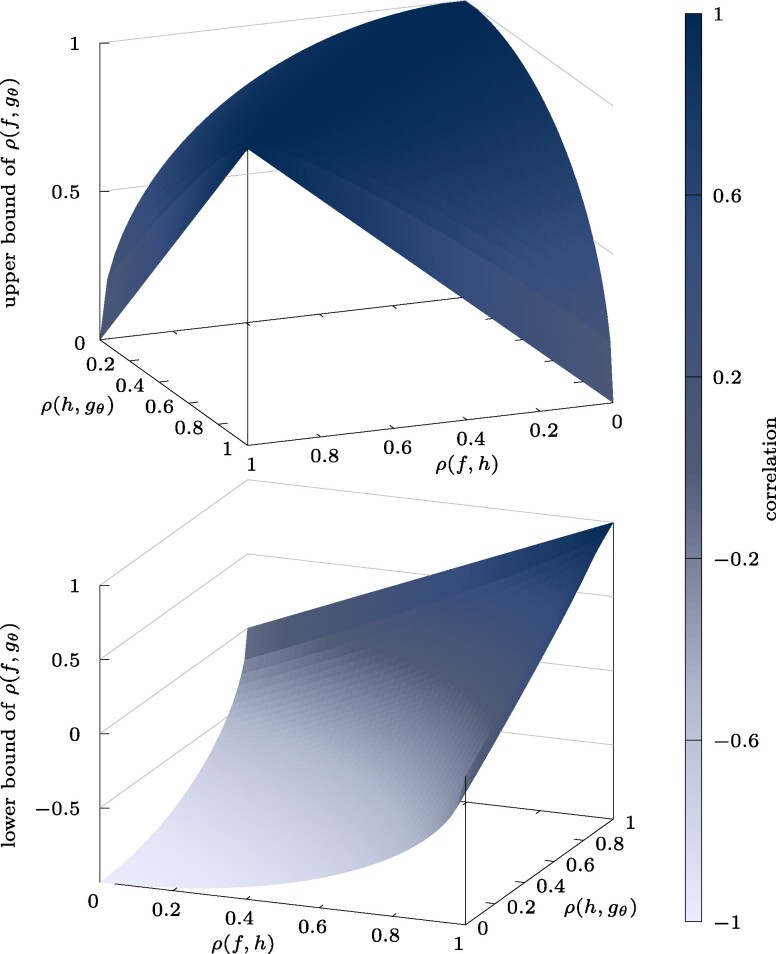
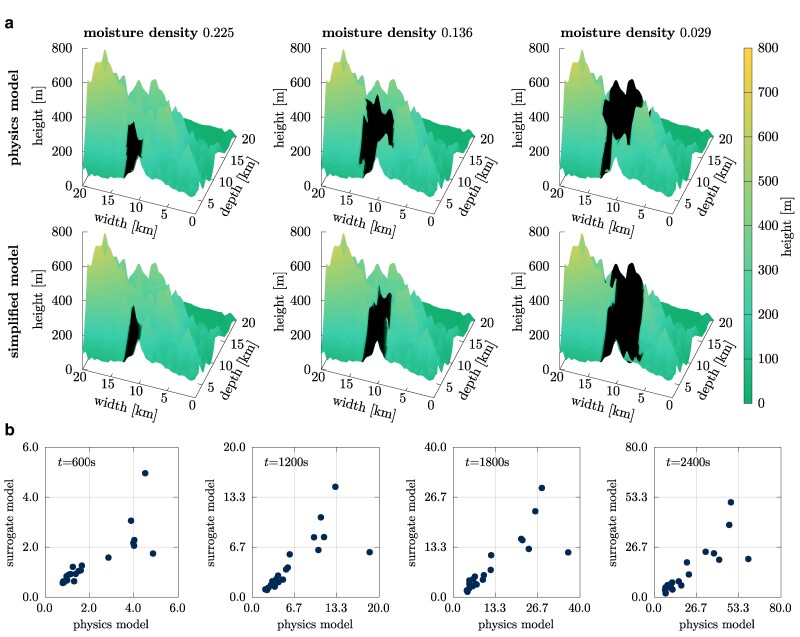
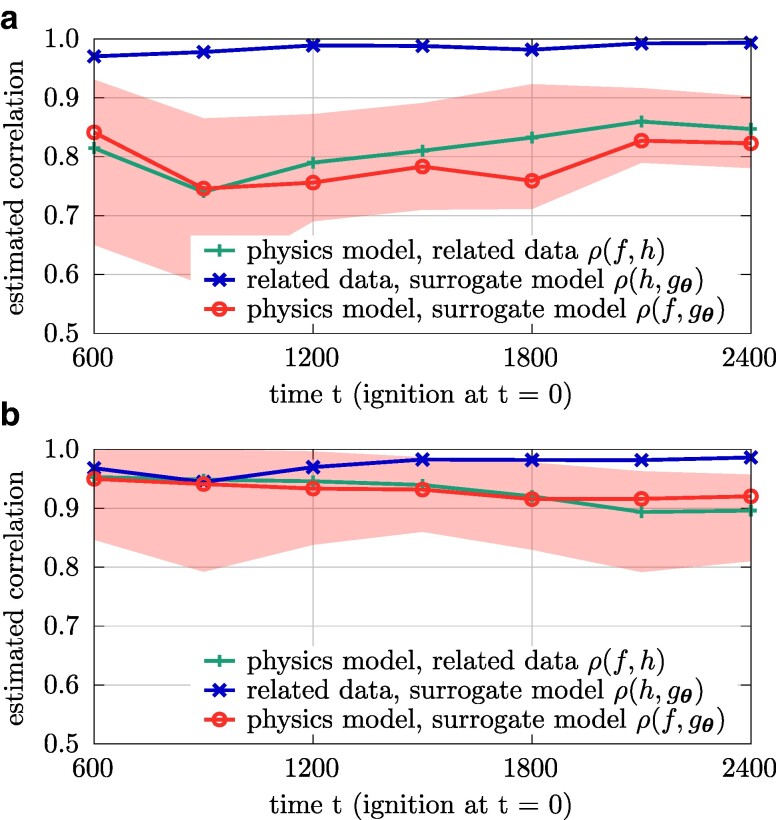
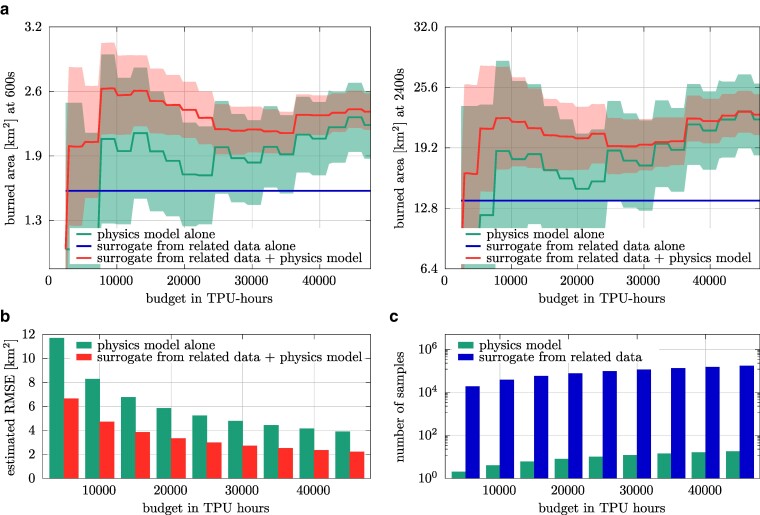
Uncertainties in wildfire simulations pose a major challenge for making decisions about fire management, mitigation, and evacuations. However, ensemble calculations to quantify uncertainties are prohibitively expensive with high-fidelity models that are needed to capture today's ever-more intense and severe wildfires. This work shows that surrogate models trained on related data enable scaling multifidelity uncertainty quantification to high-fidelity wildfire simulations of unprecedented scale with billions of degrees of freedom. The key insight is that correlation is all that matters while bias is irrelevant for speeding up uncertainty quantification when surrogate models are combined with high-fidelity models in multifidelity approaches. This allows the surrogate models to be trained on abundantly available or cheaply generated related data samples that can be strongly biased as long as they are correlated to predictions of high-fidelity simulations. Numerical results with scenarios of the Tubbs 2017 wildfire demonstrate that surrogate models trained on related data make multifidelity uncertainty quantification in large-scale wildfire simulations practical by reducing the training time by several orders of magnitude from 3 months to under 3 h and predicting the burned area at least twice as accurately compared with using high-fidelity simulations alone for a fixed computational budget. More generally, the results suggest that leveraging related data can greatly extend the scope of surrogate modeling, potentially benefiting other fields that require uncertainty quantification in computationally expensive high-fidelity simulations.
野火模拟中的不确定性给火灾管理、缓解和疏散决策带来了重大挑战。然而,使用捕捉当今日益强烈和严重野火所需的高保真模型进行量化不确定性的系综计算成本过高。这项工作表明,在相关数据上训练的代理模型能够将多保真度不确定性量化扩展到具有数十亿自由度的前所未有的规模的高保真野火模拟。关键的见解是,在多保真度方法中,当代理模型与高保真模型结合时,相关性才是关键,而偏差对于加速不确定性量化并不重要。这使得代理模型能够在大量可用或低成本生成的相关数据样本上进行训练,只要这些样本与高保真模拟的预测相关,即使存在强烈偏差也无妨。2017年塔布斯野火场景的数值结果表明,在相关数据上训练(的)代理模型通过将训练时间从3个月减少几个数量级至3小时以内,并在固定计算预算下预测烧毁面积的准确性至少提高一倍,从而使大规模野火模拟中的多保真度不确定性量化变得切实可行。更普遍地说,结果表明利用相关数据可以极大地扩展代理建模的范围,可能使其他需要在计算成本高昂的高保真模拟中进行不确定性量化的领域受益。