Lee Kwang-Sig, Ham Byung-Joo
AI Center, Korea University College of Medicine & Anam Hospital, Seoul, Republic of Korea.
Department of Psychiatry, Korea University College of Medicine & Anam Hospital, Seoul, Republic of Korea.
Psychiatry Investig. 2024 Dec;21(12):1382-1390. doi: 10.30773/pi.2024.0249. Epub 2024 Dec 23.
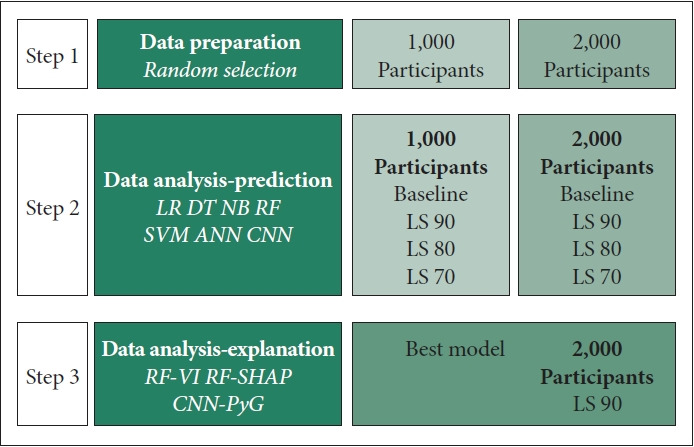
It takes significant time and energy to collect data on explicit networks. This study used graph machine learning to identify hidden networks and predict mental health conditions in the middle-aged and old.
Data came from the Korean Longitudinal Study of Ageing (2016-2018), with 2,000 participants aged 56 or more. The dependent variable was mental disease (no vs. yes) in 2018. Twenty-eight predictors in 2016 were included. Graph machine learning with systematic hyper-parameter selection was conducted.
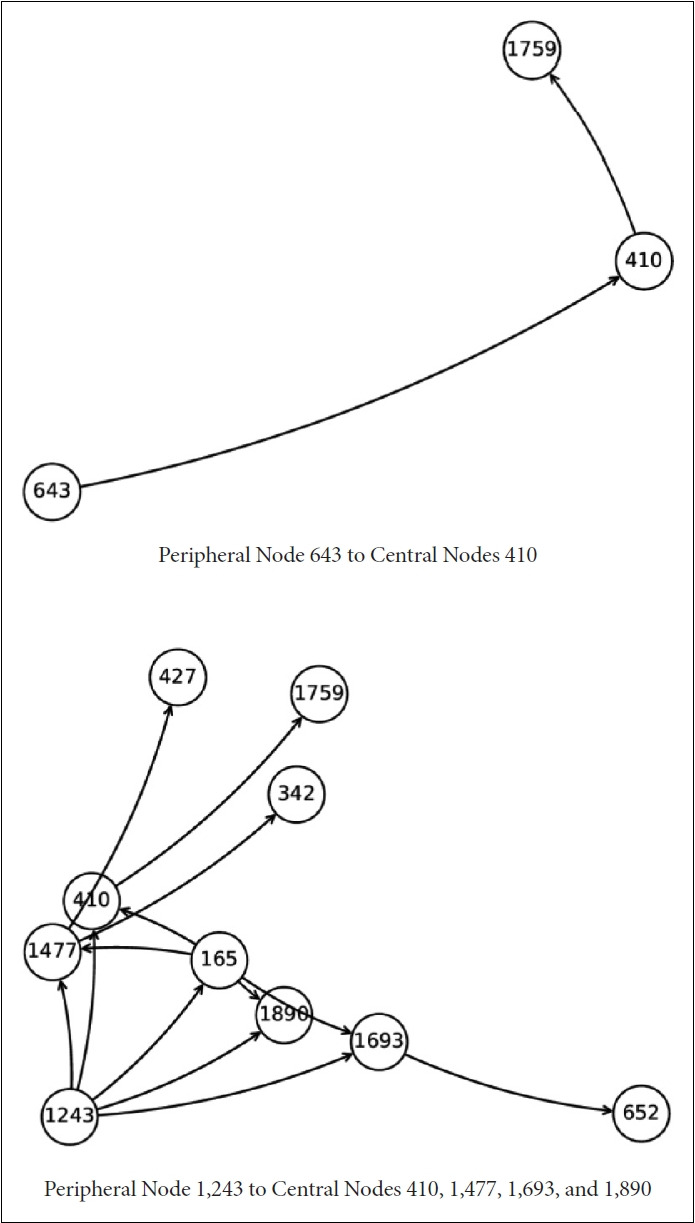
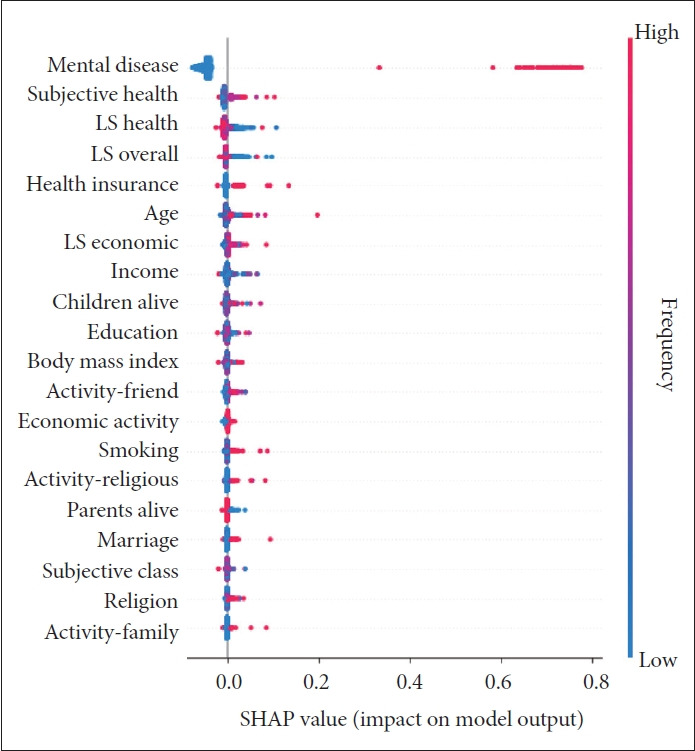
The area under the curve was similar across different models in different scenarios. However, sensitivity (93%) was highest for the graph random forest in the scenario of 2,000 participants and the centrality requirement of life satisfaction 90. Based on the graph random forest, top-10 determinants of mental disease were mental disease in previous period (2016), age, income, life satisfaction-health, life satisfaction-overall, subjective health, body mass index, life satisfaction-economic, children alive and health insurance. Especially, life satisfaction-overall was a top-5 determinant in the graph random forest, which considers life satisfaction as an emotional connection and a group interaction.
Improving an individual's life satisfaction as a personal condition is expected to strengthen the individual's emotional connection as a group interaction, which would reduce the risk of the individual's mental disease in the end. This would bring an important clinical implication for highlighting the importance of a patient's life satisfaction and emotional connection regarding the diagnosis and management of the patient's mental disease.
收集显性网络的数据需要大量的时间和精力。本研究使用图机器学习来识别隐藏网络并预测中老年人的心理健康状况。
数据来自韩国老龄化纵向研究(2016 - 2018年),有2000名年龄在56岁及以上的参与者。因变量是2018年的精神疾病(无 vs. 有)。纳入了2016年的28个预测因素。进行了具有系统超参数选择的图机器学习。
在不同场景下,不同模型的曲线下面积相似。然而,在2000名参与者且生活满意度中心性要求为90的场景中,图随机森林的灵敏度最高(93%)。基于图随机森林,精神疾病的前10个决定因素是前期(2016年)的精神疾病、年龄、收入、生活满意度 - 健康、生活满意度 - 总体、主观健康、体重指数、生活满意度 - 经济、在世子女数量和健康保险。特别是,生活满意度 - 总体是图随机森林中的前5个决定因素之一,该模型将生活满意度视为一种情感联系和群体互动。
将提高个人的生活满意度作为一种个人条件,有望加强个人作为群体互动的情感联系,最终降低个人患精神疾病的风险。这对于突出患者生活满意度和情感联系在患者精神疾病诊断和管理中的重要性具有重要的临床意义。