Wright Erik S
Department of Biomedical Informatics, University of Pittsburgh, Pittsburgh, PA 15219, USA.
Center for Evolutionary Biology and Medicine, Pittsburgh, PA 15219, USA.
Genome Biol Evol. 2025 Feb 3;17(2). doi: 10.1093/gbe/evaf013.
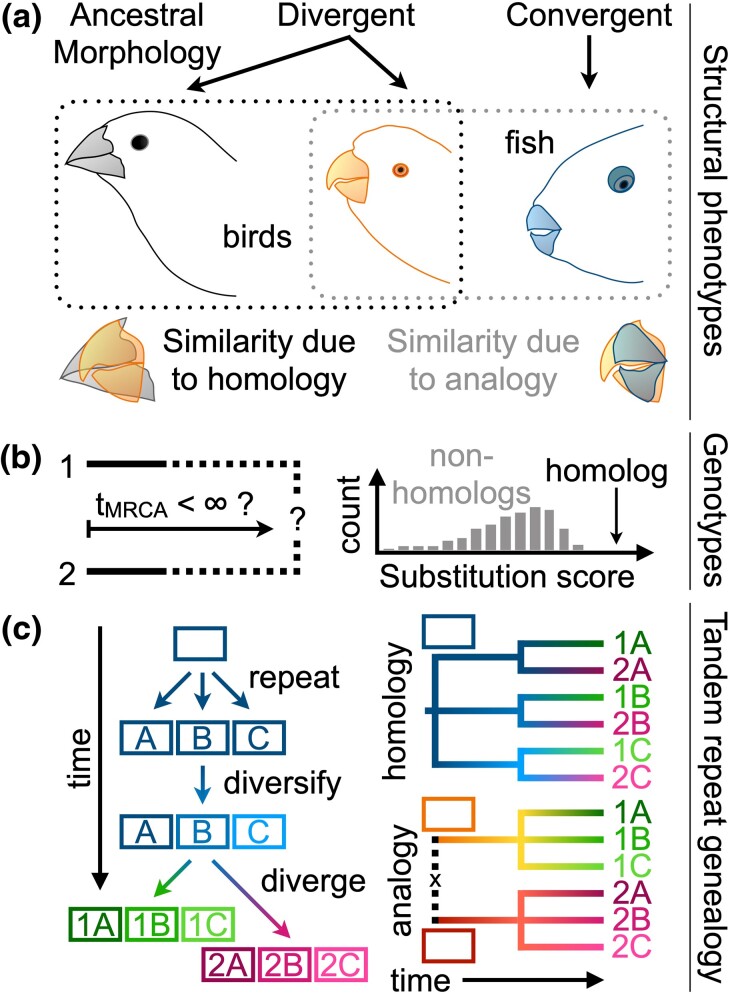
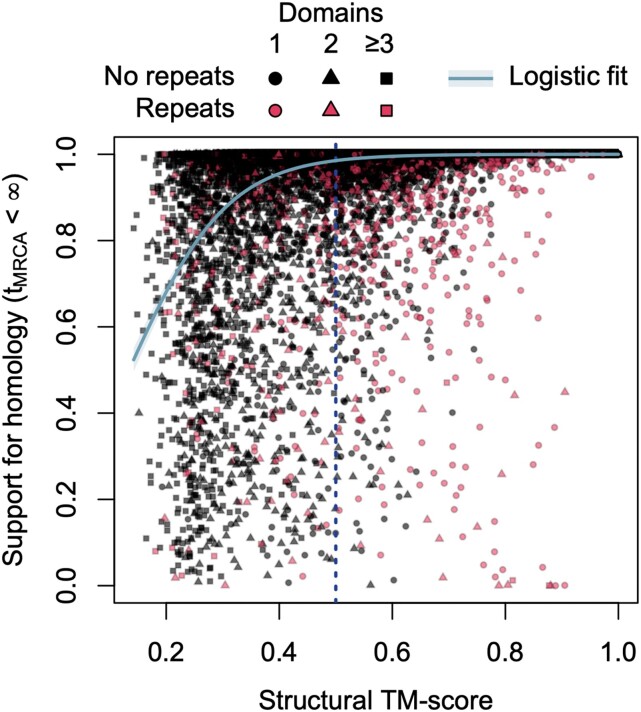
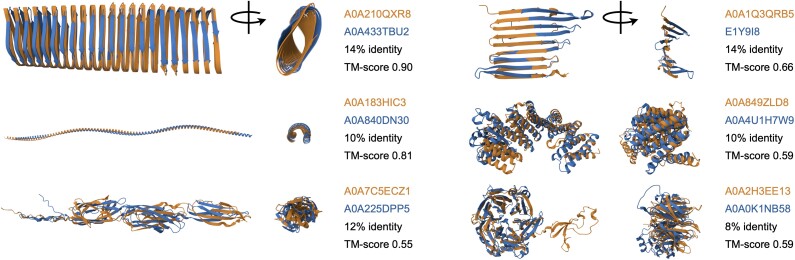
Homology is a key concept underpinning the comparison of sequences across organisms. Sequence-level homology is based on a statistical framework optimized over decades of work. Recently, computational protein structure prediction has enabled large-scale homology inference beyond the limits of accurate sequence alignment. In this regime, it is possible to observe nearly identical protein structures lacking detectable sequence similarity. In the absence of a robust statistical framework for structure comparison, it is largely assumed similar structures are homologous. However, it is conceivable that matching structures could arise through convergent evolution, resulting in analogous proteins without shared ancestry. Large databases of predicted structures offer a means of determining whether analogs are present among structure matches. Here, I find that a small subset (∼2.6%) of Foldseek clusters lack sequence-level support for homology, including ∼1% of strong structure matches with template modeling score ≥ 0.5. This result by itself does not imply these structure pairs are nonhomologous, since their sequences could have diverged beyond the limits of recognition. Yet, strong matches without sequence-level support for homology are enriched in structures with predicted repeats that could induce spurious matches. Some of these structural repeats are underpinned by sequence-level tandem repeats in both matching structures. I show that many of these tandem repeat units have genealogies inconsistent with their corresponding structures sharing a common ancestor, implying these highly similar structure pairs are analogous rather than homologous. This result suggests caution is warranted when inferring homology from structural resemblance alone in the absence of sequence-level support for homology.
同源性是支撑跨生物体序列比较的关键概念。序列水平的同源性基于经过数十年研究优化的统计框架。最近,计算蛋白质结构预测使得大规模同源性推断超出了精确序列比对的限制。在这种情况下,有可能观察到缺乏可检测序列相似性的近乎相同的蛋白质结构。在缺乏用于结构比较的强大统计框架的情况下,人们大多认为相似结构是同源的。然而,可以想象匹配的结构可能通过趋同进化产生,从而导致没有共同祖先的类似蛋白质。大量预测结构数据库提供了一种确定结构匹配中是否存在类似物的方法。在这里,我发现Foldseek聚类的一小部分(约2.6%)缺乏序列水平的同源性支持,包括约1%的模板建模得分≥0.5的强结构匹配。这一结果本身并不意味着这些结构对是非同源的,因为它们的序列可能已经分化到超出识别的极限。然而,缺乏序列水平同源性支持的强匹配在具有预测重复序列的结构中富集,这些重复序列可能会导致虚假匹配。其中一些结构重复序列在两个匹配结构中都由序列水平的串联重复序列支撑。我表明,许多这些串联重复单元的谱系与它们相应的结构共享共同祖先不一致,这意味着这些高度相似的结构对是类似物而非同源物。这一结果表明,在没有序列水平同源性支持的情况下,仅从结构相似性推断同源性时需要谨慎。