Nasir Muhammad Umar, Naseem Muhammad Tahir, Ghazal Taher M, Zubair Muhammad, Ali Oualid, Abbas Sagheer, Ahmad Munir, Adnan Khan Muhammad
School of Computing, IVY CMS, Lahore, 54000, Pakistan.
Department of Computer Science, Faculty of Computing, Riphah International University, Islamabad, 45000, Pakistan.
Sci Rep. 2025 Apr 17;15(1):13359. doi: 10.1038/s41598-025-97353-0.
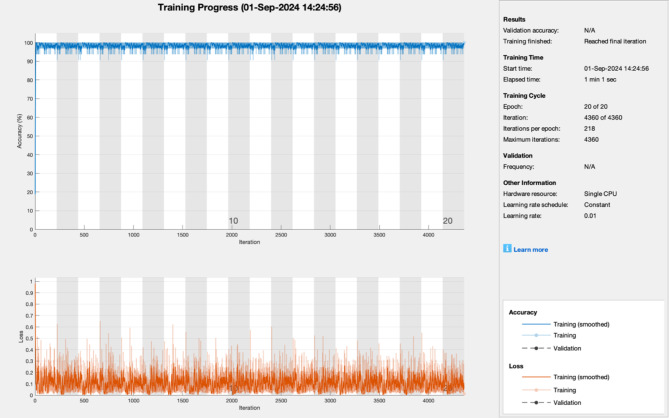
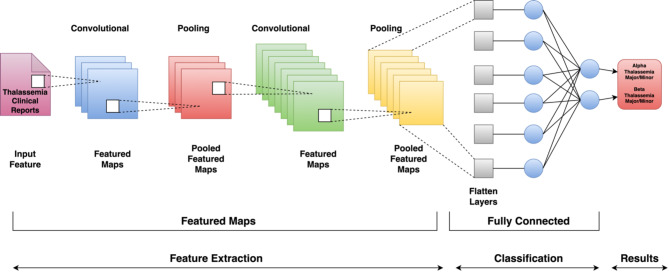
This study explores the performance of deep learning models, specifically Convolutional Neural Networks (CNN) and XGBoost, in predicting alpha and beta thalassemia using both public and private datasets. Thalassemia is a genetic disorder that impairs hemoglobin production, leading to anemia and other health complications. Early diagnosis is essential for effective management and prevention of severe health issues. The study applied CNN and XGBoost to two case studies: one for alpha-thalassemia and the other for beta-thalassemia. Public datasets were sourced from medical databases, while private datasets were collected from clinical records, offering a more comprehensive feature set and larger sample sizes. After data preprocessing and splitting, model performance was evaluated. XGBoost achieved 99.34% accuracy on the private dataset for alpha thalassemia, while CNN reached 98.10% accuracy on the private dataset for beta-thalassemia. The superior performance on private datasets was attributed to better data quality and volume. This study highlights the effectiveness of deep learning in medical diagnostics, demonstrating that high-quality data can significantly enhance the predictive capabilities of AI models. By integrating CNN and XGBoost, this approach offers a robust method for detecting thalassemia, potentially improving early diagnosis and reducing disease-related mortality.
本研究探讨了深度学习模型,特别是卷积神经网络(CNN)和XGBoost,在使用公共和私有数据集预测α和β地中海贫血方面的性能。地中海贫血是一种遗传性疾病,会损害血红蛋白的生成,导致贫血和其他健康并发症。早期诊断对于有效管理和预防严重健康问题至关重要。该研究将CNN和XGBoost应用于两个案例研究:一个用于α地中海贫血,另一个用于β地中海贫血。公共数据集来自医学数据库,而私有数据集则从临床记录中收集,提供了更全面的特征集和更大的样本量。经过数据预处理和拆分后,对模型性能进行了评估。XGBoost在α地中海贫血的私有数据集上达到了99.34%的准确率,而CNN在β地中海贫血的私有数据集上达到了98.10%的准确率。私有数据集上的卓越性能归因于更好的数据质量和数量。本研究强调了深度学习在医学诊断中的有效性,表明高质量数据可以显著提高人工智能模型的预测能力。通过整合CNN和XGBoost,这种方法为检测地中海贫血提供了一种强大的方法,有可能改善早期诊断并降低与疾病相关的死亡率。