Vaithianathan Rhema, Benavides-Prado Diana, Rebbe Rebecca, Putnam-Hornstein Emily
Centre for Social Data Analytics, Auckland University of Technology, Private Bag 92006, Auckland, 1142, New Zealand.
School of Computer Science, The University of Auckland, Auckland, New Zealand.
Prev Sci. 2025 Apr;26(3):321-330. doi: 10.1007/s11121-025-01802-1. Epub 2025 Apr 22.
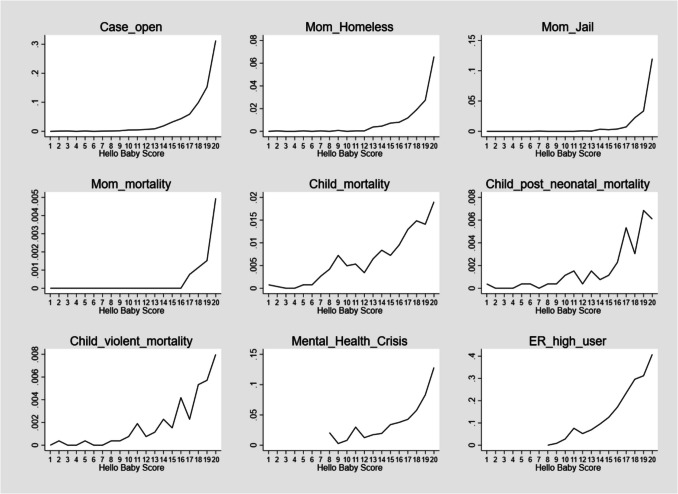
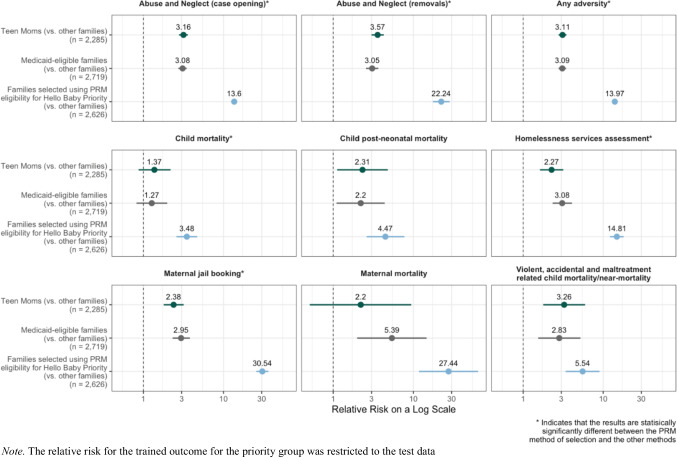
Population-based efforts to prevent child abuse and neglect are challenging because annual incidence rates are relatively low. Even among families that meet eligibility and risk criteria for intensive home-visiting programs, the baseline rate of maltreatment tends to be low because we use simple criteria. This creates both service (i.e., cost) and evaluation (i.e., power) challenges because a large number of families need to receive the preventive intervention to produce detectable changes in subsequent maltreatment. The increase in the availability of administrative data has made it possible to use predictive risk models (PRMs) to risk-stratify whole birth cohorts and identify children at the highest risk of maltreatment and other early childhood adversities. The current paper describes the development and validation of a PRM implemented in Allegheny County, Pennsylvania, to stratify families and newborn infants into three levels of prioritized services based on the predicted risk of child removal due to maltreatment by age 3. Using a research dataset of anonymized records for children born in Allegheny County between 2012 and 2015, predictive features were coded using data available in the county's administrative data systems. This spine was linked to child removal outcomes between 2012 and 2018, so we had a 3-year follow-up for each child. A PRM was trained to predict removals in the first 3 years of life using the least absolute shrinkage and selection operator. Predictive accuracy was measured for the highest 5% of risk scores in a holdout dataset. The model was validated using nontraining outcomes such as maternal mortality, infant mortality, and maltreatment-related fatalities and near-fatalities. The model achieved an area under the receiver operating characteristic curve of .93 (95% CI [0.92, 0.95]), recall of 19.93%, and precision of 54.10%. Children identified for the top tier of services had a relative risk ratio of maltreatment-related fatality or near-fatality of 5.54 (95% CI [3.41, 9.00]). Using alternative eligibility approaches (e.g., poverty, teen maternal age) proved far inferior to using PRM in targeting services for children at high baseline risk of maltreatment.
基于人群的预防儿童虐待和忽视的努力具有挑战性,因为年发病率相对较低。即使在符合强化家访计划资格和风险标准的家庭中,虐待的基线发生率往往也很低,因为我们使用的是简单的标准。这带来了服务(即成本)和评估(即效力)方面的挑战,因为需要大量家庭接受预防性干预,才能在随后的虐待情况中产生可检测到的变化。行政数据可用性的提高使得使用预测风险模型(PRM)对整个出生队列进行风险分层,并识别出遭受虐待和其他幼儿期逆境风险最高的儿童成为可能。本文描述了在宾夕法尼亚州阿勒格尼县实施的一个PRM的开发和验证过程,该模型根据预测的因虐待在3岁前被带走的风险,将家庭和新生儿分为三个优先服务级别。利用阿勒格尼县2012年至2015年出生儿童的匿名记录研究数据集,使用该县行政数据系统中可用的数据对预测特征进行编码。这个主干与2012年至2018年期间儿童被带走的结果相关联,因此我们对每个儿童进行了3年的随访。使用最小绝对收缩和选择算子训练了一个PRM,以预测生命最初3年的被带走情况。在一个保留数据集中,对风险评分最高的5%的预测准确性进行了测量。该模型使用非训练结果(如孕产妇死亡率、婴儿死亡率以及与虐待相关的死亡和近乎死亡情况)进行验证。该模型的受试者工作特征曲线下面积为0.93(95%置信区间[0.92, 0.95]),召回率为19.93%,精确率为54.10%。被确定为最高服务级别的儿童遭受虐待相关死亡或近乎死亡的相对风险比为5.54(95%置信区间[3.41, 9.00])。事实证明,使用替代资格认定方法(如贫困、青少年母亲年龄)在针对虐待基线风险高的儿童提供服务方面远不如使用PRM。