Kaster Levi, Hillis Ethan, Oh Inez Y, Aravamuthan Bhooma R, Lanzotti Virginia C, Vickstrom Casey R, Gurnett Christina A, Payne Philip R O, Gupta Aditi
Institute for Informatics, Data Science and Biostatistics, Washington University School of Medicine in St. Louis, St. Louis, MO, USA.
Department of Neurology, Washington University School of Medicine in St. Louis, St. Louis, MO, USA.
J Neurodev Disord. 2025 Apr 30;17(1):24. doi: 10.1186/s11689-025-09612-w.
Functional biomarkers in neurodevelopmental disorders, such as verbal and ambulatory abilities, are essential for clinical care and research activities. Treatment planning, intervention monitoring, and identifying comorbid conditions in individuals with intellectual and developmental disabilities (IDDs) rely on standardized assessments of these abilities. However, traditional assessments impose a burden on patients and providers, often leading to longitudinal inconsistencies and inequities due to evolving guidelines and associated time-cost. Therefore, this study aimed to develop an automated approach to classify verbal and ambulatory abilities from EHR data of IDD and cerebral palsy (CP) patients. Application of large language models (LLMs) to clinical notes, which are rich in longitudinal data, may provide a low-burden pipeline for extracting functional biomarkers efficiently and accurately.
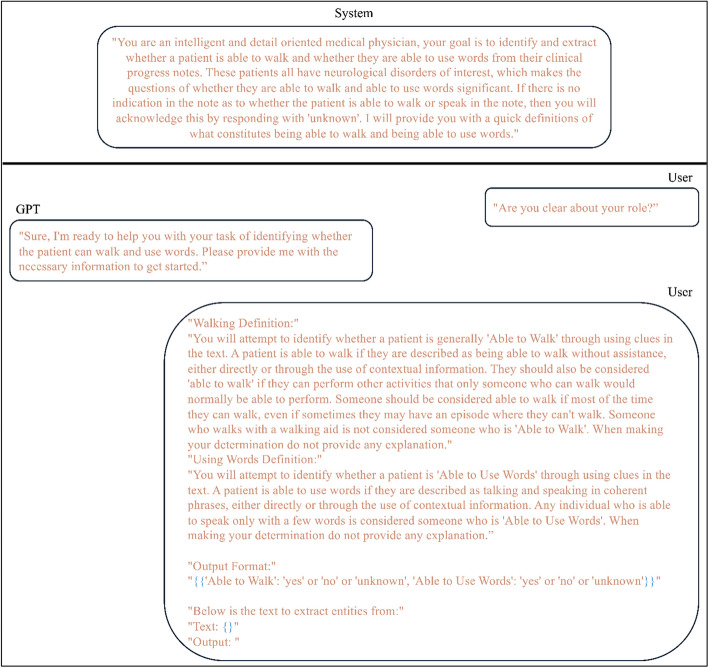
Data from the multi-institutional National Brain Gene Registry (BGR) and a CP clinic cohort were utilized, comprising 3,245 notes from 125 individuals and 5,462 clinical notes from 260 individuals, respectively. Employing three LLMs-GPT-3.5 Turbo, GPT-4 Turbo, and GPT-4 Omni-we provided the models with a clinical note and utilized a detailed conversational format to prompt the models to answer: "Does the individual use any words?" and "Can the individual walk without aid?" These responses were evaluated against ground-truth abilities, which were established using neurobehavioral assessments collected for each dataset.
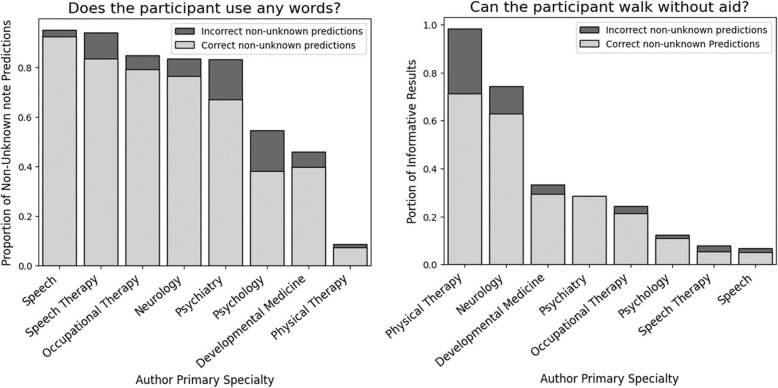
LLM pipelines demonstrated high accuracy (weighted-F1 scores > .90) in predicting ambulatory ability for both cohorts, likely due to the consistent use of Gross Motor Functional Classification System (GMFCS) as a consistent ground-truth standard. However, verbal ability predictions were more accurate in the BGR cohort, likely due to higher adherence between the prompt and ground-truth assessment questions. While LLMs can be computationally expensive, analysis of our protocol affirmed the cost effectiveness when applied to select notes from the EHR.
LLMs are effective at extracting functional biomarkers from EHR data and broadly generalizable across variable note-taking practices and institutions. Individual verbal and ambulatory ability were accurately extracted, supporting the method's ability to streamline workflows by offering automated, efficient data extraction for patient care and research. Future studies are needed to extend this methodology to additional populations and to demonstrate more granular functional data classification.
神经发育障碍中的功能生物标志物,如言语和行走能力,对于临床护理和研究活动至关重要。智力和发育障碍(IDD)患者的治疗计划、干预监测以及共病情况的识别依赖于对这些能力的标准化评估。然而,传统评估给患者和医护人员带来负担,由于指南不断演变以及相关的时间成本,常常导致纵向不一致和不公平。因此,本研究旨在开发一种自动化方法,从IDD和脑瘫(CP)患者的电子健康记录(EHR)数据中对言语和行走能力进行分类。将大语言模型(LLM)应用于富含纵向数据的临床记录,可能为高效、准确地提取功能生物标志物提供一种低负担的途径。
利用来自多机构的国家脑基因登记处(BGR)和一个CP临床队列的数据,分别包括来自125名个体的3245份记录和来自260名个体的5462份临床记录。我们使用三个LLM——GPT-3.5 Turbo、GPT-4 Turbo和GPT-4 Omni——为模型提供一份临床记录,并采用详细的对话形式促使模型回答:“该个体是否使用任何词语?”以及“该个体能否独立行走?”将这些回答与通过为每个数据集收集的神经行为评估确定的真实能力进行比较。
LLM流程在预测两个队列的行走能力方面显示出高准确率(加权F1分数>.90),这可能是由于一致使用粗大运动功能分类系统(GMFCS)作为一致的真实标准。然而,言语能力预测在BGR队列中更准确,这可能是由于提示与真实评估问题之间的更高一致性。虽然LLM计算成本可能很高,但对我们方案的分析证实,当应用于从EHR中选择的记录时具有成本效益。
LLM在从EHR数据中提取功能生物标志物方面有效,并且在不同的记录方式和机构中具有广泛的通用性。个体的言语和行走能力被准确提取,支持该方法通过为患者护理和研究提供自动化、高效的数据提取来简化工作流程的能力。未来需要开展研究,将这种方法扩展到更多人群,并展示更细致的功能数据分类。