Student Research Committee, Kerman University of Medical Sciences, Kerman, Iran.
Department of Health Information Sciences, Faculty of Management and Medical Information Sciences, Kerman University of Medical Sciences, Kerman, Iran.
BMC Bioinformatics. 2023 Oct 29;24(1):405. doi: 10.1186/s12859-023-05480-0.
Extracting information from free texts using natural language processing (NLP) can save time and reduce the hassle of manually extracting large quantities of data from incredibly complex clinical notes of cancer patients. This study aimed to systematically review studies that used NLP methods to identify cancer concepts from clinical notes automatically.
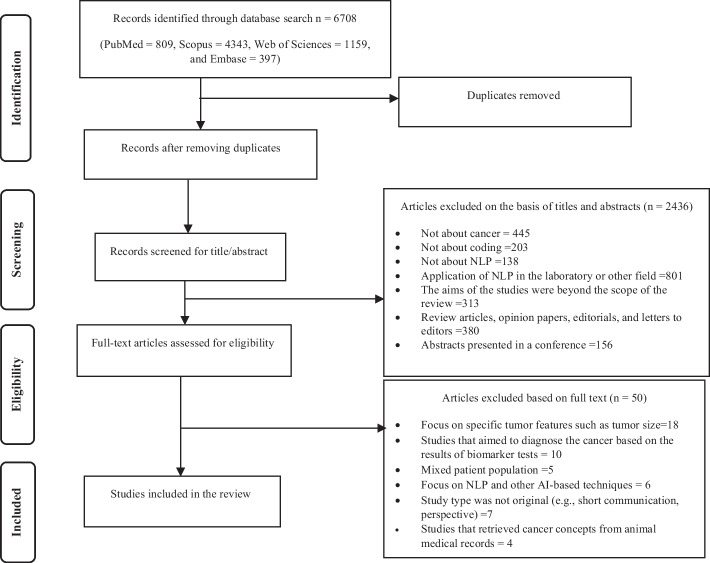
PubMed, Scopus, Web of Science, and Embase were searched for English language papers using a combination of the terms concerning "Cancer", "NLP", "Coding", and "Registries" until June 29, 2021. Two reviewers independently assessed the eligibility of papers for inclusion in the review.
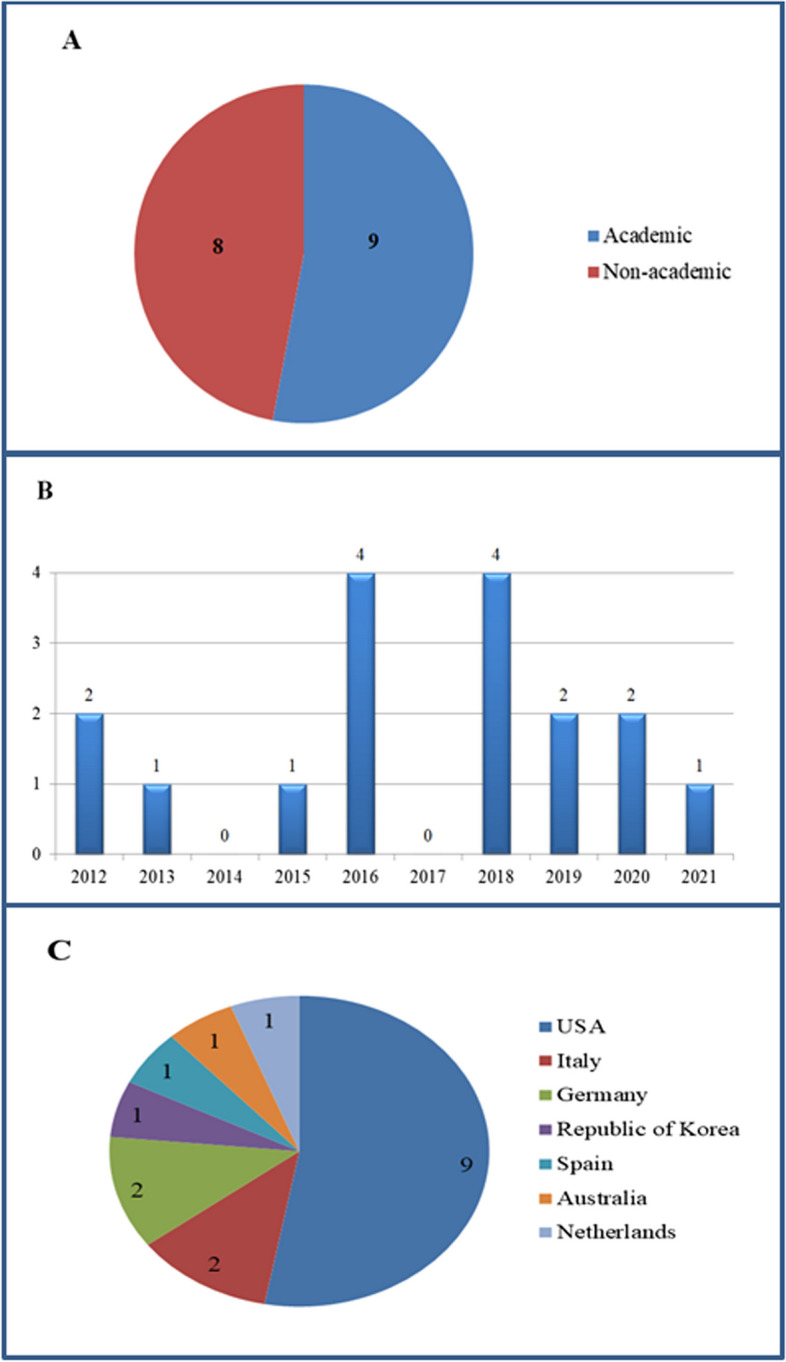
Most of the software programs used for concept extraction reported were developed by the researchers (n = 7). Rule-based algorithms were the most frequently used algorithms for developing these programs. In most articles, the criteria of accuracy (n = 14) and sensitivity (n = 12) were used to evaluate the algorithms. In addition, Systematized Nomenclature of Medicine-Clinical Terms (SNOMED-CT) and Unified Medical Language System (UMLS) were the most commonly used terminologies to identify concepts. Most studies focused on breast cancer (n = 4, 19%) and lung cancer (n = 4, 19%).
The use of NLP for extracting the concepts and symptoms of cancer has increased in recent years. The rule-based algorithms are well-liked algorithms by developers. Due to these algorithms' high accuracy and sensitivity in identifying and extracting cancer concepts, we suggested that future studies use these algorithms to extract the concepts of other diseases as well.
使用自然语言处理(NLP)从自由文本中提取信息可以节省时间,并减少从癌症患者极其复杂的临床记录中手动提取大量数据的麻烦。本研究旨在系统地综述使用 NLP 方法自动从临床记录中识别癌症概念的研究。
使用“癌症”、“NLP”、“编码”和“登记”等术语,结合组合词,在 PubMed、Scopus、Web of Science 和 Embase 中搜索英文文献,检索时间截至 2021 年 6 月 29 日。两名审查员独立评估纳入研究的论文的资格。
用于概念提取的软件程序大多是由研究人员开发的(n=7)。规则算法是开发这些程序最常用的算法。在大多数文章中,使用准确性(n=14)和敏感性(n=12)标准来评估算法。此外,系统医学术语命名法-临床术语(SNOMED-CT)和统一医学语言系统(UMLS)是最常用于识别概念的术语。大多数研究都集中在乳腺癌(n=4,19%)和肺癌(n=4,19%)。
近年来,使用 NLP 提取癌症概念和症状的应用有所增加。规则算法是开发人员喜欢的算法。由于这些算法在识别和提取癌症概念方面具有较高的准确性和敏感性,我们建议未来的研究也使用这些算法来提取其他疾病的概念。