Huang Jingwei, Yang Donghan M, Rong Ruichen, Nezafati Kuroush, Treager Colin, Chi Zhikai, Wang Shidan, Cheng Xian, Guo Yujia, Klesse Laura J, Xiao Guanghua, Peterson Eric D, Zhan Xiaowei, Xie Yang
Quantitative Biomedical Research Center, Peter O'Donnell School of Public Health, University of Texas Southwestern Medical Center, 5323 Harry Hines Blvd, Dallas, TX, USA 75390, USA.
Department of Pathology, University of Texas Southwestern Medical Center, 5323 Harry Hines Blvd, Dallas, TX, USA 75390, USA.
NPJ Digit Med. 2024 May 1;7(1):106. doi: 10.1038/s41746-024-01079-8.
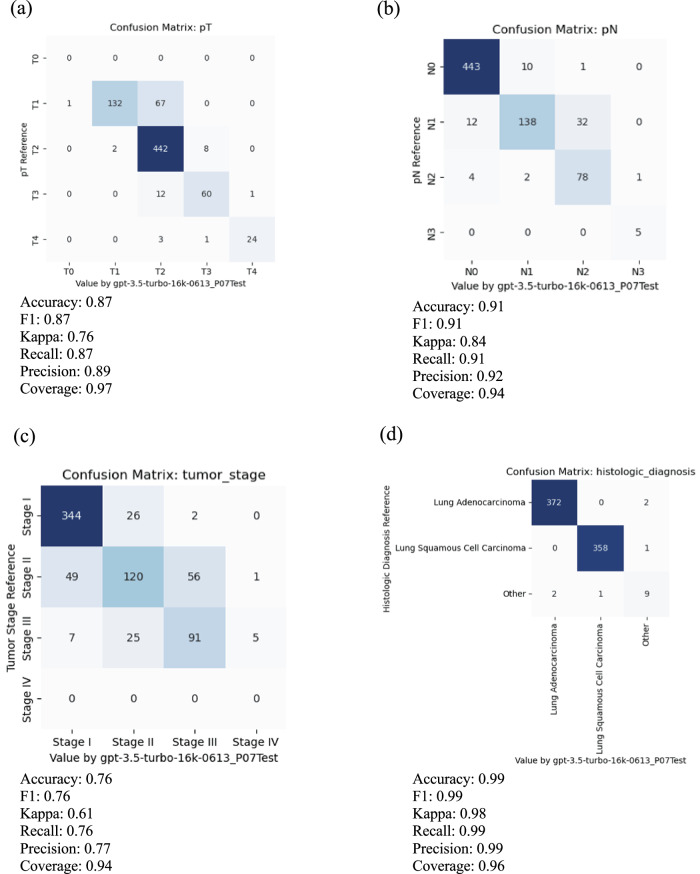
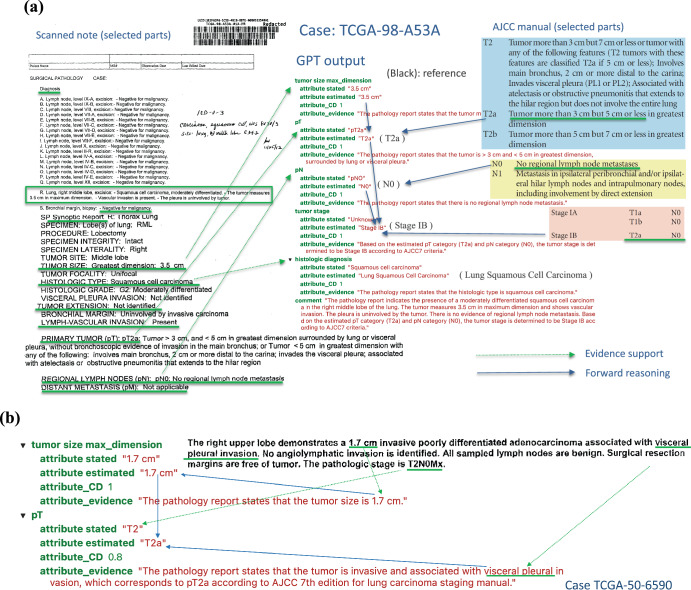
Existing natural language processing (NLP) methods to convert free-text clinical notes into structured data often require problem-specific annotations and model training. This study aims to evaluate ChatGPT's capacity to extract information from free-text medical notes efficiently and comprehensively. We developed a large language model (LLM)-based workflow, utilizing systems engineering methodology and spiral "prompt engineering" process, leveraging OpenAI's API for batch querying ChatGPT. We evaluated the effectiveness of this method using a dataset of more than 1000 lung cancer pathology reports and a dataset of 191 pediatric osteosarcoma pathology reports, comparing the ChatGPT-3.5 (gpt-3.5-turbo-16k) outputs with expert-curated structured data. ChatGPT-3.5 demonstrated the ability to extract pathological classifications with an overall accuracy of 89%, in lung cancer dataset, outperforming the performance of two traditional NLP methods. The performance is influenced by the design of the instructive prompt. Our case analysis shows that most misclassifications were due to the lack of highly specialized pathology terminology, and erroneous interpretation of TNM staging rules. Reproducibility shows the relatively stable performance of ChatGPT-3.5 over time. In pediatric osteosarcoma dataset, ChatGPT-3.5 accurately classified both grades and margin status with accuracy of 98.6% and 100% respectively. Our study shows the feasibility of using ChatGPT to process large volumes of clinical notes for structured information extraction without requiring extensive task-specific human annotation and model training. The results underscore the potential role of LLMs in transforming unstructured healthcare data into structured formats, thereby supporting research and aiding clinical decision-making.
现有的将自由文本临床记录转换为结构化数据的自然语言处理(NLP)方法通常需要特定问题的注释和模型训练。本研究旨在评估ChatGPT从自由文本医学记录中高效、全面提取信息的能力。我们开发了一种基于大语言模型(LLM)的工作流程,利用系统工程方法和螺旋式“提示工程”过程,借助OpenAI的应用程序编程接口(API)对ChatGPT进行批量查询。我们使用一个包含1000多份肺癌病理报告的数据集和一个包含191份儿童骨肉瘤病理报告的数据集评估了该方法的有效性,将ChatGPT-3.5(gpt-3.5-turbo-16k)的输出与专家整理的结构化数据进行比较。在肺癌数据集中,ChatGPT-3.5展示了提取病理分类的能力,总体准确率为89%,优于两种传统NLP方法的性能。性能受指导性提示设计的影响。我们的案例分析表明,大多数错误分类是由于缺乏高度专业化的病理学术语以及对TNM分期规则的错误解读。可重复性表明ChatGPT-3.5随时间推移性能相对稳定。在儿童骨肉瘤数据集中,ChatGPT-3.5对分级和切缘状态的准确分类率分别为98.6%和100%。我们的研究表明,使用ChatGPT处理大量临床记录以提取结构化信息是可行的,无需大量特定任务的人工注释和模型训练。结果强调了大语言模型在将非结构化医疗数据转换为结构化格式方面的潜在作用,从而支持研究并辅助临床决策。