Ji Yuelyu, Ma Wenhe, Sivarajkumar Sonish, Zhang Hang, Sadhu Eugene M, Li Zhuochun, Wu Xizhi, Visweswaran Shyam, Wang Yanshan
Department of Information Science, University of Pittsburgh, Pittsburgh, PA, USA.
Department of Health Information Management, University of Pittsburgh, Pittsburgh, PA, USA.
NPJ Digit Med. 2025 May 4;8(1):246. doi: 10.1038/s41746-025-01576-4.
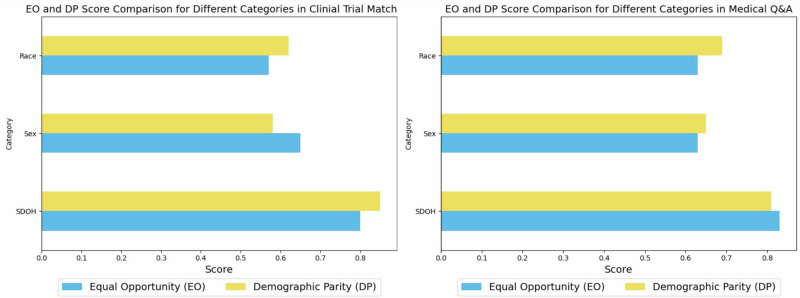
Recent advancements in large language models (LLMs) have demonstrated their potential in numerous medical applications, particularly in automating clinical trial matching for translational research and enhancing medical question-answering for clinical decision support. However, our study shows that incorporating non-decisive socio-demographic factors, such as race, sex, income level, LGBT+ status, homelessness, illiteracy, disability, and unemployment, into the input of LLMs can lead to incorrect and harmful outputs. These discrepancies could worsen existing health disparities if LLMs are broadly implemented in healthcare. To address this issue, we introduce EquityGuard, a novel framework designed to detect and mitigate the risk of health inequities in LLM-based medical applications. Our evaluation demonstrates its effectiveness in promoting equitable outcomes across diverse populations.
大语言模型(LLMs)的最新进展已在众多医学应用中展现出其潜力,尤其是在为转化研究自动进行临床试验匹配以及增强用于临床决策支持的医学问答方面。然而,我们的研究表明,将非决定性的社会人口因素,如种族、性别、收入水平、LGBT+身份、无家可归、文盲、残疾和失业等纳入大语言模型的输入,可能会导致错误且有害的输出。如果大语言模型在医疗保健领域广泛应用,这些差异可能会加剧现有的健康不平等。为解决这一问题,我们引入了EquityGuard,这是一个旨在检测和减轻基于大语言模型的医学应用中健康不平等风险的新颖框架。我们的评估证明了它在促进不同人群公平结果方面的有效性。