Zhai Jingchen, Qi Xiguang, Cai Lianjin, Liu Yue, Tang Haocheng, Xie Lei, Wang Junmei
Department of Pharmaceutical Sciences and Computational Chemical Genomics Screening Center, School of Pharmacy, University of Pittsburgh, 3501 Terrace St, Pittsburgh, PA 15261, United States.
Department of Computer Science, Hunter College, The City University of New York, 695 Park Ave, New York, NY 10065, United States.
Brief Bioinform. 2025 May 1;26(3). doi: 10.1093/bib/bbaf212.
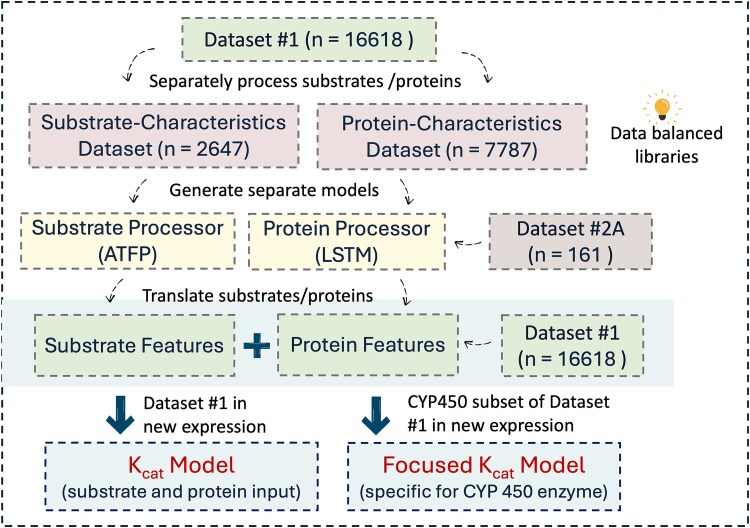
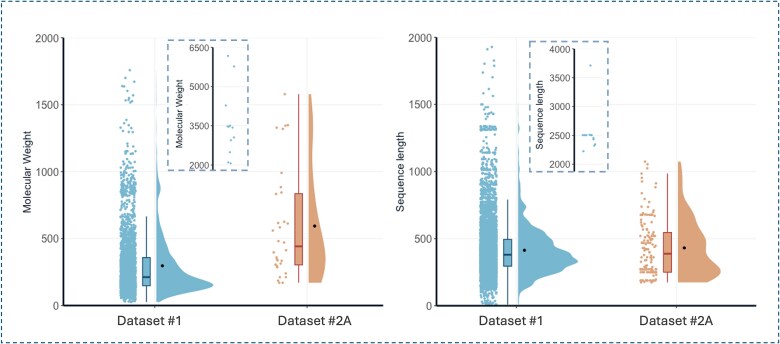
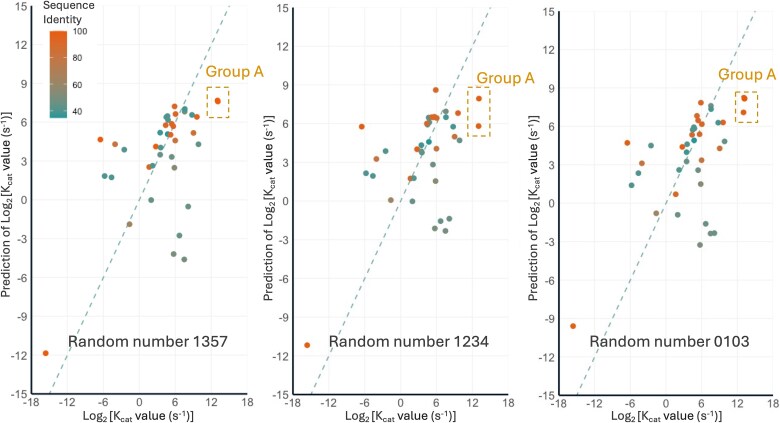
Catalytic constant (Kcat) is to describe the efficiency of catalyzing reactions. The Kcat value of an enzyme-substrate pair indicates the rate an enzyme converts saturated substrates into product during the catalytic process. However, it is challenging to construct robust prediction models for this important property. Most of the existing models, including the one recently published by Nature Catalysis (Li et al.), are suffering from the overfitting issue. In this study, we proposed a novel protocol to construct Kcat prediction models, introducing an intermedia step to separately develop substrate and protein processors. The substrate processor leverages analyzing Simplified Molecular Input Line Entry System (SMILES) strings using a graph neural network model, attentive FP, while the protein processor abstracts protein sequence information utilizing long short-term memory architecture. This protocol not only mitigates the impact of data imbalance in the original dataset but also provides greater flexibility in customizing the general-purpose Kcat prediction model to enhance the prediction accuracy for specific enzyme classes. Our general-purpose Kcat prediction model demonstrates significantly enhanced stability and slightly better accuracy (R2 value of 0.54 versus 0.50) in comparison with Li et al.'s model using the same dataset. Additionally, our modeling protocol enables personalization of fine-tuning the general-purpose Kcat model for specific enzyme categories through focused learning. Using Cytochrome P450 (CYP450) enzymes as a case study, we achieved the best R2 value of 0.64 for the focused model. The high-quality performance and expandability of the model guarantee its broad applications in enzyme engineering and drug research & development.
催化常数(Kcat)用于描述催化反应的效率。酶 - 底物对的Kcat值表示酶在催化过程中将饱和底物转化为产物的速率。然而,为这一重要性质构建稳健的预测模型具有挑战性。大多数现有模型,包括《自然·催化》(Li等人)最近发表的模型,都存在过拟合问题。在本研究中,我们提出了一种构建Kcat预测模型的新方案,引入了一个中间步骤来分别开发底物和蛋白质处理器。底物处理器利用图神经网络模型Attentive FP分析简化分子输入线性规范(SMILES)字符串,而蛋白质处理器利用长短期记忆架构提取蛋白质序列信息。该方案不仅减轻了原始数据集中数据不平衡的影响,还在定制通用Kcat预测模型方面提供了更大的灵活性,以提高对特定酶类别的预测准确性。与Li等人使用相同数据集的模型相比,我们的通用Kcat预测模型显示出显著增强的稳定性和略高的准确性(R2值为0.54,而之前为0.50)。此外,我们的建模方案能够通过聚焦学习针对特定酶类别对通用Kcat模型进行个性化微调。以细胞色素P450(CYP450)酶为例,我们的聚焦模型实现了0.64的最佳R2值。该模型的高质量性能和可扩展性保证了其在酶工程和药物研发中的广泛应用。