Bosma Joeran S, Dercksen Koen, Builtjes Luc, André Romain, Roest Christian, Fransen Stefan J, Noordman Constant R, Navarro-Padilla Mar, Lefkes Judith, Alves Natália, de Grauw Max J J, van Eekelen Leander, Spronck Joey M A, Schuurmans Megan, de Wilde Bram, Hendrix Ward, Aswolinskiy Witali, Saha Anindo, Twilt Jasper J, Geijs Daan, Veltman Jeroen, Yakar Derya, de Rooij Maarten, Ciompi Francesco, Hering Alessa, Geerdink Jeroen, Huisman Henkjan
Diagnostic Image Analysis Group, Department of Medical Imaging, Radboud University Medical Center, Nijmegen, The Netherlands.
Department of Health & Information Technology, Ziekenhuisgroep Twente, Almelo, The Netherlands.
NPJ Digit Med. 2025 May 17;8(1):289. doi: 10.1038/s41746-025-01626-x.
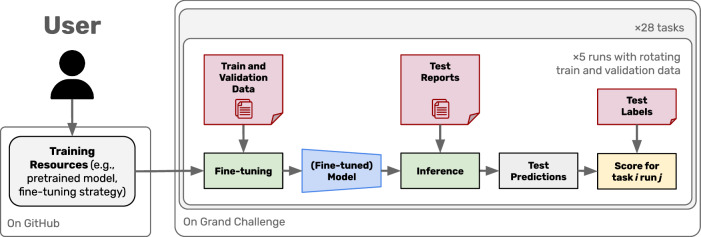
Artificial Intelligence can mitigate the global shortage of medical diagnostic personnel but requires large-scale annotated datasets to train clinical algorithms. Natural Language Processing (NLP), including Large Language Models (LLMs), shows great potential for annotating clinical data to facilitate algorithm development but remains underexplored due to a lack of public benchmarks. This study introduces the DRAGON challenge, a benchmark for clinical NLP with 28 tasks and 28,824 annotated medical reports from five Dutch care centers. It facilitates automated, large-scale, cost-effective data annotation. Foundational LLMs were pretrained using four million clinical reports from a sixth Dutch care center. Evaluations showed the superiority of domain-specific pretraining (DRAGON 2025 test score of 0.770) and mixed-domain pretraining (0.756), compared to general-domain pretraining (0.734, p < 0.005). While strong performance was achieved on 18/28 tasks, performance was subpar on 10/28 tasks, uncovering where innovations are needed. Benchmark, code, and foundational LLMs are publicly available.
人工智能可以缓解全球医学诊断人员短缺的问题,但需要大规模的带注释数据集来训练临床算法。包括大语言模型(LLMs)在内的自然语言处理(NLP)在注释临床数据以促进算法开发方面显示出巨大潜力,但由于缺乏公共基准,仍未得到充分探索。本研究介绍了DRAGON挑战,这是一个用于临床NLP的基准,包含来自荷兰五个护理中心的28个任务和28824份带注释的医学报告。它有助于实现自动化、大规模且经济高效的数据注释。基础大语言模型使用来自荷兰第六个护理中心的400万份临床报告进行预训练。评估显示,与通用领域预训练(0.734,p < 0.005)相比,特定领域预训练(DRAGON 2025测试分数为0.770)和混合领域预训练(0.756)具有优越性。虽然在28个任务中的18个任务上取得了强劲的性能,但在28个任务中的10个任务上性能低于标准,揭示了需要创新的地方。基准、代码和基础大语言模型均可公开获取。