Sundaravadivel P, Isaac R Augustian, Elangovan D, KrishnaRaj D, Rahul V V Lokesh, Raja R
Saveetha Engineering College, Chennai, 602105, Tamilnadu, India.
Sci Rep. 2025 May 22;15(1):17851. doi: 10.1038/s41598-025-00873-y.
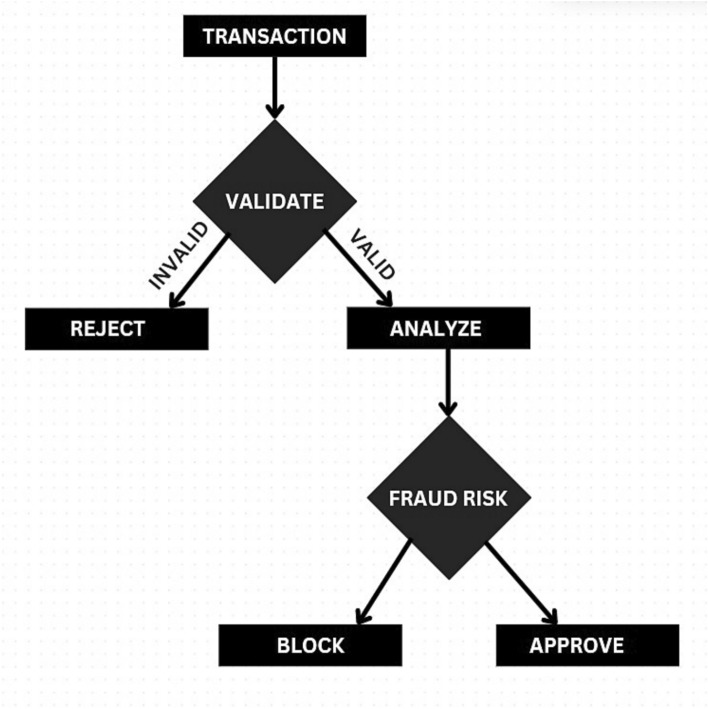
In the financial world, Credit card fraud is a budding apprehension in the banking sector, necessitating the development of efficient detection methods to minimize financial losses. The usage of credit cards is experiencing a steady increase, thereby leading to a rise in the default rate that banks encounter. Although there has been much research investigating the efficacy of conventional Machine Learning (ML) models, there has been relatively less emphasis on Deep Learning (DL) techniques. In this article, a machine learning-based system to detect fraudulent transactions using a publicly available dataset of credit card transactions. The dataset, highly imbalanced with fraudulent transactions representing less than 0.2% of the total, was processed using techniques like Synthetic Minority Over-sampling Technique (SMOTE) to handle class imbalance. To predict credit card default, this study evaluates the efficacy of a DL (Deep Learning) model and compares it to other ML models, such as Decision Tree (DT) and Adaboost. The objective of this research is to identify the specific DL parameters that contribute to the observed enhancements in the accuracy of credit card default prediction. This research makes use of the UCI ML repository to access the credit card defaulted customer dataset. Subsequently, various techniques are employed to pre-process the unprocessed data and visually present the outcomes through the use of exploratory data analysis (EDA). Furthermore, the algorithms are hyper tuned to evaluate the enhancement in prediction. We used standard evaluation metrics to evaluate all the models. The evaluation indicates that the Adaboost and DT exhibit the highest accuracy rate of 82 % in predicting credit card default, surpassing the accuracy of the ANN model, which is 78 %. Several classification algorithms, comprising Logistic Regression, Random Forest, and Neural Networks, were evaluated to determine their effectiveness in identifying fraudulent activities. The Random Forest model emerged as the best performing algorithm with an accuracy of 99.5% and a high recall score, indicating its robustness in detecting fraudulent transactions. This system can be deployed in real-time financial systems to enhance fraud prevention mechanisms and ensure secure financial transactions.
在金融领域,信用卡欺诈是银行业中一个新兴的担忧问题,因此需要开发高效的检测方法以将财务损失降至最低。信用卡的使用量正在稳步增长,从而导致银行面临的违约率上升。尽管已经有很多研究调查传统机器学习(ML)模型的有效性,但对深度学习(DL)技术的关注相对较少。在本文中,我们构建了一个基于机器学习的系统,用于使用公开可用的信用卡交易数据集检测欺诈交易。该数据集严重不平衡,欺诈交易占总数不到0.2%,我们使用了诸如合成少数过采样技术(SMOTE)等技术来处理类别不平衡问题。为了预测信用卡违约情况,本研究评估了深度学习(DL)模型的有效性,并将其与其他机器学习模型,如决策树(DT)和Adaboost进行比较。本研究的目的是确定有助于提高信用卡违约预测准确性的特定深度学习参数。本研究利用UCI机器学习库来获取信用卡违约客户数据集。随后,采用各种技术对未处理的数据进行预处理,并通过探索性数据分析(EDA)直观地呈现结果。此外,对算法进行超参数调整以评估预测的改进情况。我们使用标准评估指标来评估所有模型。评估表明,Adaboost和DT在预测信用卡违约方面表现出最高准确率,为82%,超过了人工神经网络模型78%的准确率。我们评估了包括逻辑回归、随机森林和神经网络在内的几种分类算法在识别欺诈活动方面的有效性。随机森林模型成为表现最佳的算法,准确率为99.5%,召回率高,表明其在检测欺诈交易方面的稳健性。该系统可部署在实时金融系统中,以加强欺诈预防机制并确保安全的金融交易。