Ahmad Muhammad, Batyrshin Ildar, Sidorov Grigori
Centro de Investigación en Computación, Instituto Politécnico Nacional, Mexico City, 07738, Mexico, 52 5591887293.
JMIR Infodemiology. 2025 Jun 19;5:e70525. doi: 10.2196/70525.
The opioid crisis poses a significant health challenge in the United States, with increasing overdoses and death rates due to opioids mixed with other illicit substances. Various strategies have been developed by federal and local governments and health organizations to address this crisis. One of the most significant objectives is to understand the epidemic through better health surveillance, and machine learning techniques can support this by identifying opioid users at risk of overdose through the analysis of social media data, as many individuals may avoid direct testing but still share their experiences online.
In this study, we take advantage of recent developments in machine learning that allow for insights into patterns of opioid use and potential risk factors in a less invasive manner using self-reported information available on social platforms.
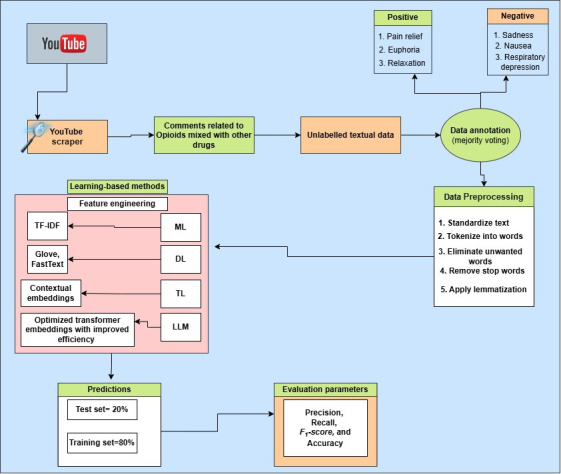
This study used YouTube comments posted between December 2020 and March 2024, in which individuals shared their self-reported experiences of opioid drugs mixed with other substances. We manually annotated our dataset into multiclass categories, capturing both the positive effects of opioid use, such as pain relief, euphoria, and relaxation, and negative experiences, including nausea, sadness, and respiratory depression, to provide a comprehensive understanding of the multifaceted impact of opioids. By analyzing this sentiment, we used 4 state-of-the-art machine learning models, 2 deep learning models, 3 transformer models, and 1 large language model (GPT-3.5 Turbo) to predict overdose risks to improve health care response and intervention strategies.
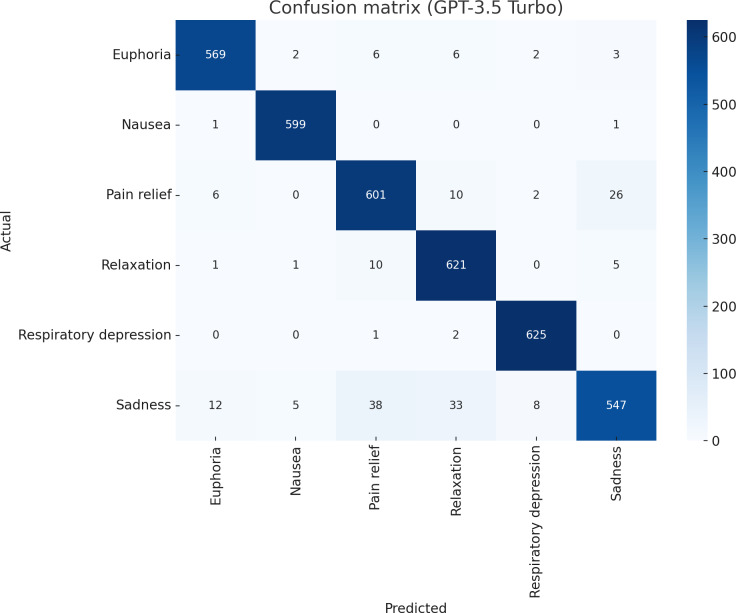
Our proposed methodology (GPT-3.5 Turbo) was highly precise and accurate, helping to automatically identify sentiment based on the adverse effects of opioid drug combinations and high-risk drug use in YouTube comments. Our proposed methodology demonstrated the highest achievable F1-score of 0.95 and a 3.26% performance improvement over traditional machine learning models such as extreme gradient boosting, which demonstrated an F1-score of 0.92.
This study demonstrates the potential of leveraging machine learning and large language models, such as GPT-3.5 Turbo, to analyze public sentiment surrounding opioid use and its associated risks. By using YouTube comments as a rich source of self-reported data, the study provides valuable insights into both the positive and negative effects of opioids, particularly when mixed with other substances. The proposed methodology significantly outperformed traditional models, contributing to more accurate predictions of overdose risks and enhancing health care responses to the opioid crisis.
阿片类药物危机给美国带来了重大的健康挑战,因阿片类药物与其他非法物质混合导致的过量用药和死亡率不断上升。联邦和地方政府以及卫生组织已制定了各种策略来应对这一危机。其中一个最重要的目标是通过更好的健康监测来了解这一流行病,机器学习技术可以通过分析社交媒体数据来识别有过量用药风险的阿片类药物使用者,从而支持这一目标,因为许多人可能会避免直接检测,但仍会在网上分享他们的经历。
在本研究中,我们利用机器学习的最新进展,以一种侵入性较小的方式,通过社交平台上可用的自我报告信息,深入了解阿片类药物使用模式和潜在风险因素。
本研究使用了2020年12月至2024年3月期间发布的YouTube评论,其中个人分享了他们自我报告的阿片类药物与其他物质混合使用的经历。我们将数据集手动标注为多类类别,既捕捉阿片类药物使用的积极影响,如疼痛缓解、欣快感和放松,也捕捉负面经历,包括恶心、悲伤和呼吸抑制,以全面了解阿片类药物的多方面影响。通过分析这种情绪,我们使用了4种先进的机器学习模型、2种深度学习模型、3种Transformer模型和1种大语言模型(GPT-3.5 Turbo)来预测过量用药风险,以改善医疗保健应对措施和干预策略。
我们提出的方法(GPT-3.5 Turbo)具有很高的精确性和准确性,有助于根据阿片类药物组合的不良反应和YouTube评论中的高风险药物使用情况自动识别情绪。我们提出的方法展示了最高可达0.95的F1分数,比诸如极端梯度提升等传统机器学习模型的性能提高了3.26%,后者的F1分数为0.92。
本研究证明了利用机器学习和大语言模型(如GPT-3.5 Turbo)来分析围绕阿片类药物使用及其相关风险的公众情绪的潜力。通过将YouTube评论用作丰富的自我报告数据来源,该研究提供了关于阿片类药物的积极和消极影响的宝贵见解,特别是当与其他物质混合时。所提出的方法显著优于传统模型,有助于更准确地预测过量用药风险,并加强对阿片类药物危机的医疗保健应对。