Adhikary Prottay Kumar, Motiyani Isha, Oke Gayatri, Joshi Maithili, Pathak Kanupriya, Singh Salam Michael, Chakraborty Tanmoy
Department of Electrical Engineering, Indian Institute of Technology Delhi, Room: 3B-7 (Block III 3rd Floor), Hauz Khas, New Delhi, 110016, India, 91 26591076 ext 011.
Yardi School of Artificial Intelligence, Indian Institute of Technology Delhi, New Delhi, India.
J Med Internet Res. 2025 Jul 16;27:e71977. doi: 10.2196/71977.
The quality and accessibility of menstrual health education (MHE) in low- and middle-income countries, including India, remain inadequate due to persistent challenges (eg, poverty, social stigma, and gender inequality). While community-driven initiatives have sought to raise awareness, artificial intelligence offers a scalable and efficient solution for disseminating accurate information. However, existing general-purpose large language models (LLMs) are often ill-suited for this task, tending to exhibit low accuracy, cultural insensitivity, and overly complex responses. To address these limitations, we developed MenstLLaMA-a specialized LLM tailored to the Indian context and designed to deliver MHE empathetically, supportively, and accessibly.
We aimed to develop and evaluate MenstLLaMA-a specialized LLM tailored to deliver accurate, culturally sensitive MHE-and assess its effectiveness in comparison to existing general-purpose models.
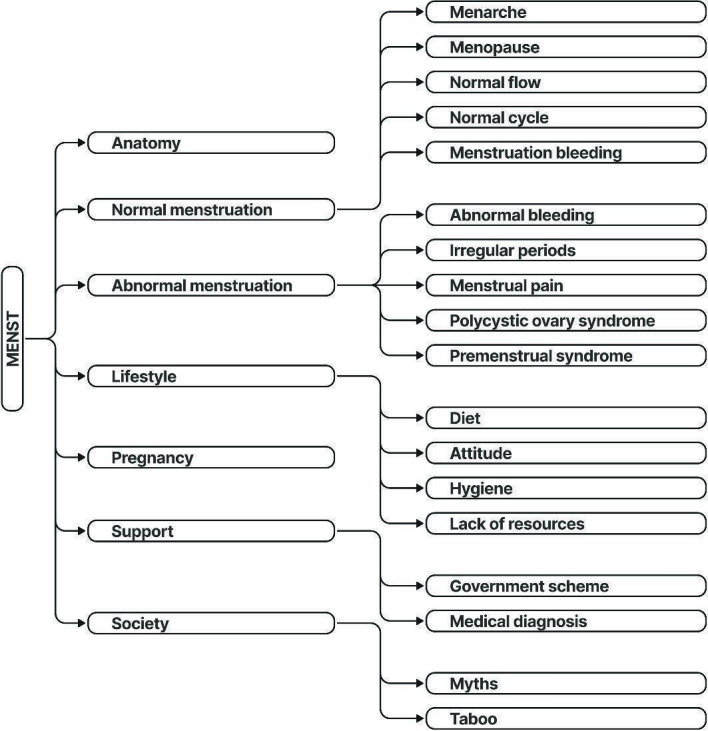
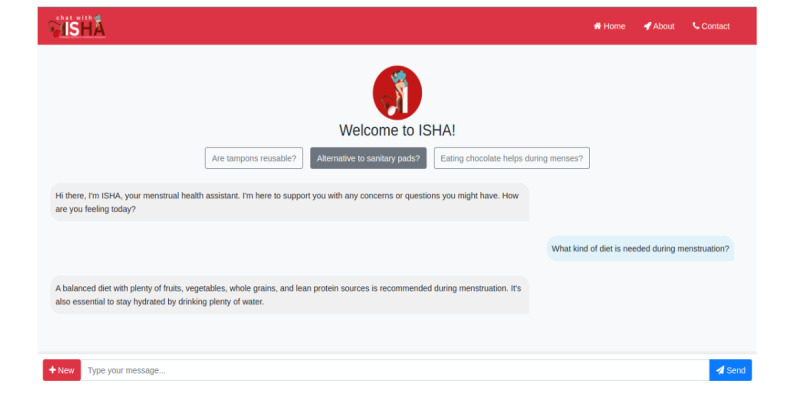
We curated MENST-a novel, domain-specific dataset comprising 23,820 question-answer pairs aggregated from medical websites, government portals, and health education resources. This dataset was systematically annotated with metadata capturing age groups, regions, topics, and sociocultural contexts. MenstLLaMA was developed by fine-tuning Meta-LLaMA-3-8B-Instruct, using parameter-efficient fine-tuning with low-rank adaptation to achieve domain alignment while minimizing computational overhead. We benchmarked MenstLLaMA against 9 state-of-the-art general-purpose LLMs, including GPT-4o, Claude-3, Gemini 1.5 Pro, and Mistral. The evaluation followed a multilayered framework: (1) automatic evaluation using standard natural language processing metrics (BLEU [Bilingual Evaluation Understudy], METEOR [Metric for Evaluation of Translation with Explicit Ordering], ROUGE-L [Recall-Oriented Understudy for Gisting Evaluation-Longest Common Subsequence], and BERTScore [Bidirectional Encoder Representations from Transformers Score]); (2) evaluation by clinical experts (N=18), who rated 200 expert-curated queries for accuracy and appropriateness; (3) medical practitioner interaction through the ISHA (Intelligent System for Menstrual Health Assistance) interactive chatbot, assessing qualitative dimensions (eg, relevance, understandability, preciseness, correctness, and context sensitivity); and (4) a user study with volunteer participants (N=200), who evaluated MenstLLaMA in 15- to 20-minute randomized sessions, rating the system across 7 qualitative user satisfaction metrics.
MenstLLaMA achieved the highest scores in BLEU (0.059) and BERTScore (0.911), outperforming GPT-4o (BLEU: 0.052, BERTScore: 0.896) and Claude-3 (BERTScore: 0.888). Clinical experts preferred MenstLLaMA's responses over gold-standard answers in several culturally sensitive cases. In medical practitioners' evaluations using the ISHA-the chat interface powered by MenstLLaMA-the model scored 3.5 in relevance, 3.6 in understandability, 3.1/5 in preciseness, 3.5/5 in correctness, and 4.0/5 in context sensitivity. User evaluations indicated even stronger results, with ratings of 4.7/5 for understandability, 4.3/5 for relevance, 4.28/5 for preciseness, 4.1/5 for correctness, 4.6/5 for tone, 4.2/5 for flow, and 3.9/5 for context sensitivity.
MenstLLaMA demonstrates exceptional accuracy, empathy, and user satisfaction within the domain of MHE, bridging critical gaps left by general-purpose LLMs. Its potential for integration into broader health education platforms positions it as a transformative tool for menstrual well-being. Future research could explore its long-term impact on public perception and menstrual hygiene practices, while expanding demographic representation, enhancing context sensitivity, and integrating multimodal and voice-based interactions to improve accessibility across diverse user groups.
包括印度在内的低收入和中等收入国家,月经健康教育(MHE)的质量和可及性由于持续存在的挑战(如贫困、社会耻辱和性别不平等)仍然不足。虽然社区驱动的倡议试图提高认识,但人工智能为传播准确信息提供了一种可扩展且高效的解决方案。然而,现有的通用大语言模型(LLMs)往往不适合这项任务,倾向于表现出低准确性、文化不敏感性和过于复杂的回答。为了解决这些限制,我们开发了MenstLLaMA——一个专门针对印度背景定制的大语言模型,旨在以共情、支持和易于理解的方式提供月经健康教育。
我们旨在开发和评估MenstLLaMA——一个专门用于提供准确、文化敏感的月经健康教育的大语言模型,并与现有的通用模型相比评估其有效性。
我们精心策划了MENST——一个新颖的、特定领域的数据集,由从医学网站、政府门户网站和健康教育资源汇总的23820个问答对组成。该数据集用捕获年龄组、地区、主题和社会文化背景的元数据进行了系统注释。MenstLLaMA是通过对Meta-LLaMA-3-8B-Instruct进行微调开发的,使用参数高效微调与低秩适应来实现领域对齐,同时最小化计算开销。我们将MenstLLaMA与9个最先进的通用大语言模型进行了基准测试,包括GPT-4o、Claude-3、Gemini 1.5 Pro和Mistral。评估遵循一个多层框架:(1)使用标准自然语言处理指标(BLEU [双语评估辅助工具]、METEOR [带显式排序的翻译评估指标]、ROUGE-L [用于摘要评估的召回导向辅助工具——最长公共子序列]和BERTScore [来自Transformer的双向编码器表示分数])进行自动评估;(2)由临床专家(N = 18)进行评估,他们对200个专家策划的查询的准确性和适当性进行评分;(3)通过ISHA(月经健康援助智能系统)交互式聊天机器人与医学从业者进行交互,评估定性维度(如相关性、可理解性、精确性、正确性和上下文敏感性);以及(4)与志愿者参与者(N = 200)进行用户研究,他们在15至20分钟的随机会话中对MenstLLaMA进行评估,根据7个定性用户满意度指标对系统进行评分。
MenstLLaMA在BLEU(0.059)和BERTScore(0.911)中获得最高分,优于GPT-4o(BLEU:0.052,BERTScore:0.896)和Claude-3(BERTScore:0.888)。在几个文化敏感的案例中,临床专家更喜欢MenstLLaMA的回答而不是金标准答案。在使用由MenstLLaMA驱动的聊天界面ISHA进行的医学从业者评估中,该模型在相关性方面得分为3.5,在可理解性方面得分为3.6,在精确性方面得分为3.1/5,在正确性方面得分为3.5/5,在上下文敏感性方面得分为4.0/5。用户评估显示结果更强,在可理解性方面得分为4.7/5,在相关性方面得分为4.3/5,在精确性方面得分为4.28/5,在正确性方面得分为4.1/5,在语气方面得分为4.6/5,在流畅性方面得分为4.2/5,在上下文敏感性方面得分为3.9/5。
MenstLLaMA在月经健康教育领域展示了卓越的准确性、共情能力和用户满意度,弥补了通用大语言模型留下的关键差距。它融入更广泛健康教育平台的潜力使其成为月经健康的变革性工具。未来的研究可以探索其对公众认知和月经卫生习惯的长期影响,同时扩大人口代表性,增强上下文敏感性,并整合多模态和基于语音的交互,以提高不同用户群体的可及性。