Hanami Raniah Nur, Mahendra Rahmad, Wicaksono Alfan Farizki
Faculty of Computer Science, Universitas Indonesia, Kampus UI, Depok, 16424, West Java, Indonesia.
J Biomed Semantics. 2025 Jul 28;16(1):13. doi: 10.1186/s13326-025-00334-5.
Online consumer health forums serve as a way for the public to connect with medical professionals. While these medical forums offer a valuable service, online Question Answering (QA) forums can struggle to deliver timely answers due to the limited number of available healthcare professionals. One way to solve this problem is by developing an automatic QA system that can provide patients with quicker answers. One key component of such a system could be a module for classifying the semantic type of a question. This would allow the system to understand the patient's intent and route them towards the relevant information.
This paper proposes a novel two-step approach to address the challenge of semantic type classification in Indonesian consumer health questions. We acknowledge the scarcity of Indonesian health domain data, a hurdle for machine learning models. To address this gap, we first introduce a novel corpus of annotated Indonesian consumer health questions. Second, we utilize this newly created corpus to build and evaluate a data-driven predictive model for classifying question semantic types. To enhance the trustworthiness and interpretability of the model's predictions, we employ an explainable model framework, LIME. This framework facilitates a deeper understanding of the role played by word-based features in the model's decision-making process. Additionally, it empowers us to conduct a comprehensive bias analysis, allowing for the detection of "semantic bias", where words with no inherent association with a specific semantic type disproportionately influence the model's predictions.
The annotation process revealed moderate agreement between expert annotators. In addition, not all words with high LIME probability could be considered true characteristics of a question type. This suggests a potential bias in the data used and the machine learning models themselves. Notably, XGBoost, Naïve Bayes, and MLP models exhibited a tendency to predict questions containing the words "kanker" (cancer) and "depresi" (depression) as belonging to the DIAGNOSIS category. In terms of prediction performance, Perceptron and XGBoost emerged as the top-performing models, achieving the highest weighted average F1 scores across all input scenarios and weighting factors. Naïve Bayes performed best after balancing the data with Borderline SMOTE, indicating its promise for handling imbalanced datasets.
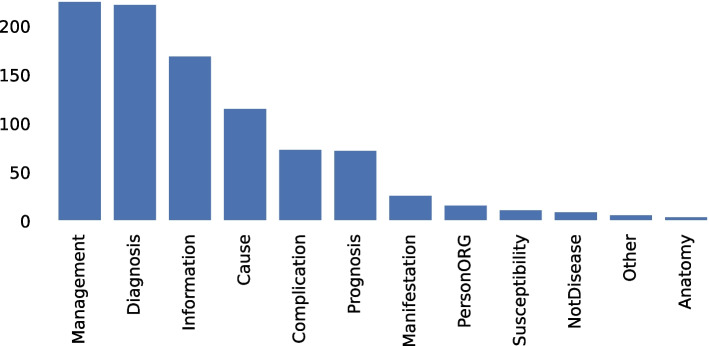
We constructed a corpus of query semantics in the domain of Indonesian consumer health, containing 964 questions annotated with their corresponding semantic types. This corpus served as the foundation for building a predictive model. We further investigated the impact of disease-biased words on model performance. These words exhibited high LIME scores, yet lacked association with a specific semantic type. We trained models using datasets with and without these biased words and found no significant difference in model performance between the two scenarios, suggesting that the models might possess an ability to mitigate the influence of such bias during the learning process.

在线消费者健康论坛是公众与医学专业人员建立联系的一种方式。虽然这些医学论坛提供了有价值的服务,但由于可用医疗专业人员数量有限,在线问答(QA)论坛可能难以及时提供答案。解决这个问题的一种方法是开发一个自动问答系统,该系统可以为患者提供更快的答案。这种系统的一个关键组件可能是一个用于对问题的语义类型进行分类的模块。这将使系统能够理解患者的意图,并将他们引导至相关信息。
本文提出了一种新颖的两步法来应对印度尼西亚消费者健康问题中语义类型分类的挑战。我们认识到印度尼西亚健康领域数据的稀缺性,这是机器学习模型面临的一个障碍。为了弥补这一差距,我们首先引入了一个带注释的印度尼西亚消费者健康问题的新语料库。其次,我们利用这个新创建的语料库来构建和评估一个用于对问题语义类型进行分类的数据驱动预测模型。为了提高模型预测的可信度和可解释性,我们采用了一个可解释模型框架LIME。这个框架有助于更深入地理解基于单词的特征在模型决策过程中所起的作用。此外,它使我们能够进行全面的偏差分析,从而检测出“语义偏差”,即与特定语义类型没有内在关联的单词对模型预测产生不成比例的影响。
注释过程显示专家注释者之间的一致性适中。此外,并非所有具有高LIME概率的单词都可被视为问题类型的真实特征。这表明所用数据和机器学习模型本身可能存在偏差。值得注意的是,XGBoost、朴素贝叶斯和MLP模型表现出将包含单词“kanker”(癌症)和“depresi”(抑郁症)的问题预测为属于诊断类别的倾向。在预测性能方面,感知机和XGBoost成为表现最佳的模型,在所有输入场景和加权因子下均获得最高的加权平均F1分数。朴素贝叶斯在使用Borderline SMOTE对数据进行平衡后表现最佳,表明其在处理不平衡数据集方面的潜力。
我们构建了一个印度尼西亚消费者健康领域的查询语义语料库,其中包含964个标注了相应语义类型的问题。这个语料库作为构建预测模型的基础。我们进一步研究了疾病偏向性单词对模型性能的影响。这些单词表现出较高的LIME分数,但与特定语义类型缺乏关联。我们使用有无这些偏向性单词的数据集训练模型,发现两种情况下模型性能没有显著差异,这表明模型可能具有在学习过程中减轻此类偏差影响的能力。