Lister Hill National Center for Biomedical Communications, U.S. National Library of Medicine, 8600 Rockville Pike, Bethesda, MD, USA.
BMC Bioinformatics. 2018 Feb 6;19(1):34. doi: 10.1186/s12859-018-2045-1.
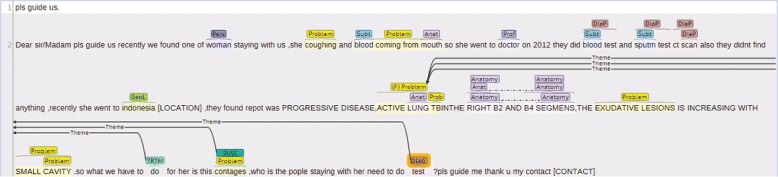
Consumers increasingly use online resources for their health information needs. While current search engines can address these needs to some extent, they generally do not take into account that most health information needs are complex and can only fully be expressed in natural language. Consumer health question answering (QA) systems aim to fill this gap. A major challenge in developing consumer health QA systems is extracting relevant semantic content from the natural language questions (question understanding). To develop effective question understanding tools, question corpora semantically annotated for relevant question elements are needed. In this paper, we present a two-part consumer health question corpus annotated with several semantic categories: named entities, question triggers/types, question frames, and question topic. The first part (CHQA-email) consists of relatively long email requests received by the U.S. National Library of Medicine (NLM) customer service, while the second part (CHQA-web) consists of shorter questions posed to MedlinePlus search engine as queries. Each question has been annotated by two annotators. The annotation methodology is largely the same between the two parts of the corpus; however, we also explain and justify the differences between them. Additionally, we provide information about corpus characteristics, inter-annotator agreement, and our attempts to measure annotation confidence in the absence of adjudication of annotations.
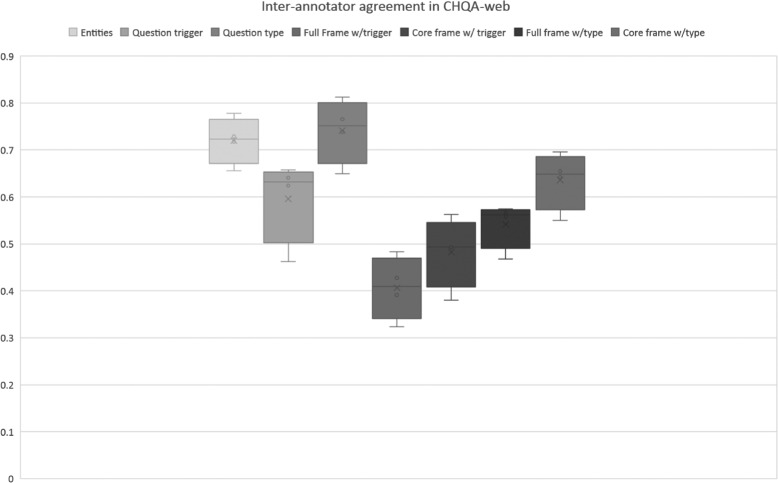
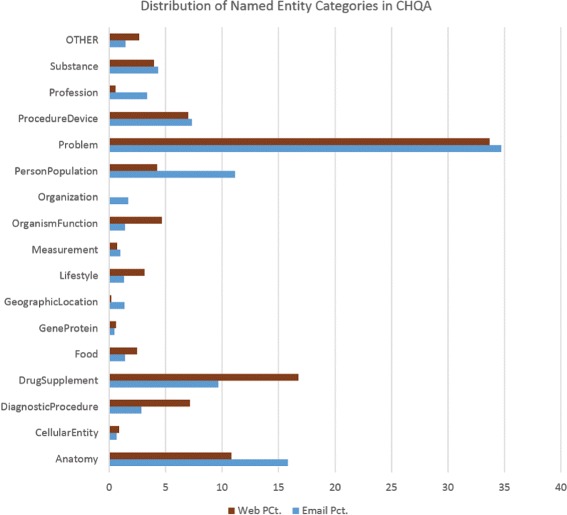
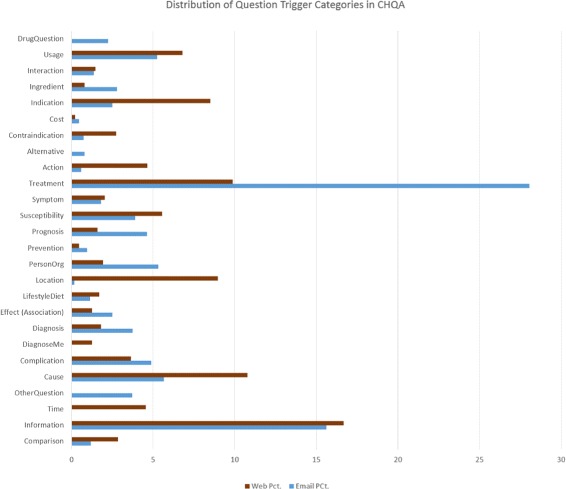
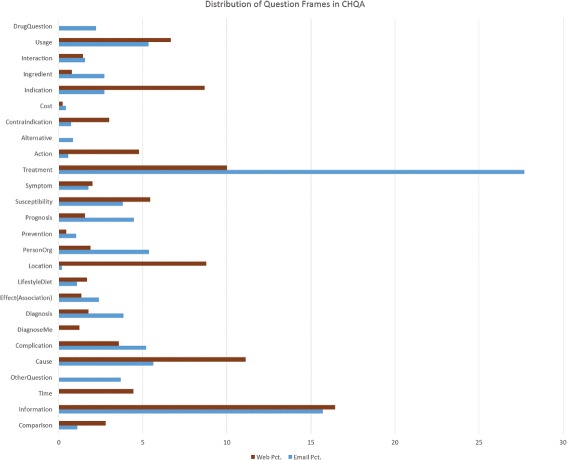
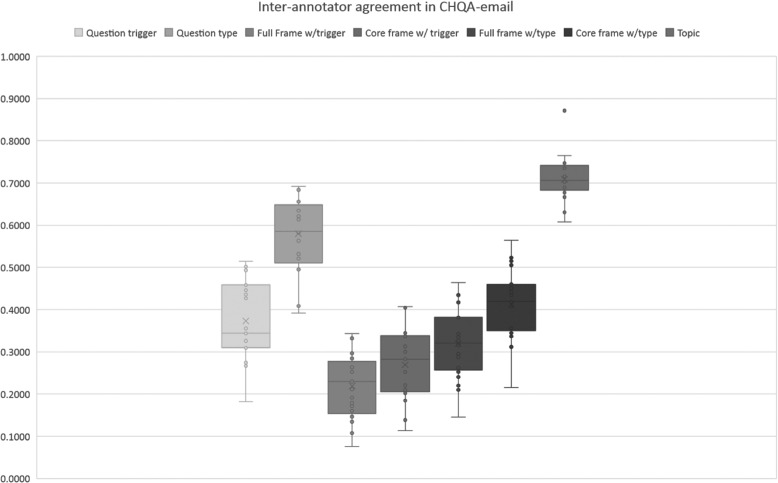
The resulting corpus consists of 2614 questions (CHQA-email: 1740, CHQA-web: 874). Problems are the most frequent named entities, while treatment and general information questions are the most common question types. Inter-annotator agreement was generally modest: question types and topics yielded highest agreement, while the agreement for more complex frame annotations was lower. Agreement in CHQA-web was consistently higher than that in CHQA-email. Pairwise inter-annotator agreement proved most useful in estimating annotation confidence.
To our knowledge, our corpus is the first focusing on annotation of uncurated consumer health questions. It is currently used to develop machine learning-based methods for question understanding. We make the corpus publicly available to stimulate further research on consumer health QA.
消费者越来越多地使用在线资源来满足他们的健康信息需求。虽然当前的搜索引擎在一定程度上可以满足这些需求,但它们通常没有考虑到大多数健康信息需求是复杂的,只能用自然语言充分表达。消费者健康问答(QA)系统旨在填补这一空白。开发消费者健康 QA 系统的一个主要挑战是从自然语言问题中提取相关的语义内容(问题理解)。为了开发有效的问题理解工具,需要具有相关问题元素语义注释的问题语料库。在本文中,我们提出了一个两部分的消费者健康问题语料库,该语料库标注了几个语义类别:命名实体、问题触发器/类型、问题框架和问题主题。第一部分(CHQA-email)由美国国家医学图书馆(NLM)客户服务收到的相对较长的电子邮件请求组成,而第二部分(CHQA-web)由向 MedlinePlus 搜索引擎提出的较短问题组成查询。每个问题都由两名注释员进行注释。注释方法在语料库的两部分之间基本相同;然而,我们也解释并证明了它们之间的差异。此外,我们提供了有关语料库特征、注释者间一致性以及在没有注释裁决的情况下尝试测量注释置信度的信息。
最终的语料库由 2614 个问题组成(CHQA-email:1740,CHQA-web:874)。问题是最常见的命名实体,而治疗和一般信息问题是最常见的问题类型。注释者间一致性通常是适度的:问题类型和主题的一致性最高,而更复杂的框架注释的一致性较低。CHQA-web 的一致性始终高于 CHQA-email。成对注释者间一致性在估计注释置信度方面最有用。
据我们所知,我们的语料库是第一个专注于未经过滤的消费者健康问题注释的语料库。它目前用于开发基于机器学习的问题理解方法。我们将语料库公开提供,以激发对消费者健康 QA 的进一步研究。