Ogundokun Roseline Oluwaseun, Owolawi Pius Adewale, Tu Chunling, van Wyk Etienne
Department of Computer Systems Engineering, Tshwane University of Technology (TUT), Pretoria 0001, South Africa.
Tomography. 2025 Aug 18;11(8):91. doi: 10.3390/tomography11080091.
Accurate subtype identification of lymphoma cancer is crucial for effective diagnosis and treatment planning. Although standard deep learning algorithms have demonstrated robustness, they are still prone to overfitting and limited generalization, necessitating more reliable and robust methods.
This study presents an autoencoder-augmented stacked ensemble learning (SEL) framework integrating deep feature extraction (DFE) and ensembles of machine learning classifiers to improve lymphoma subtype identification.
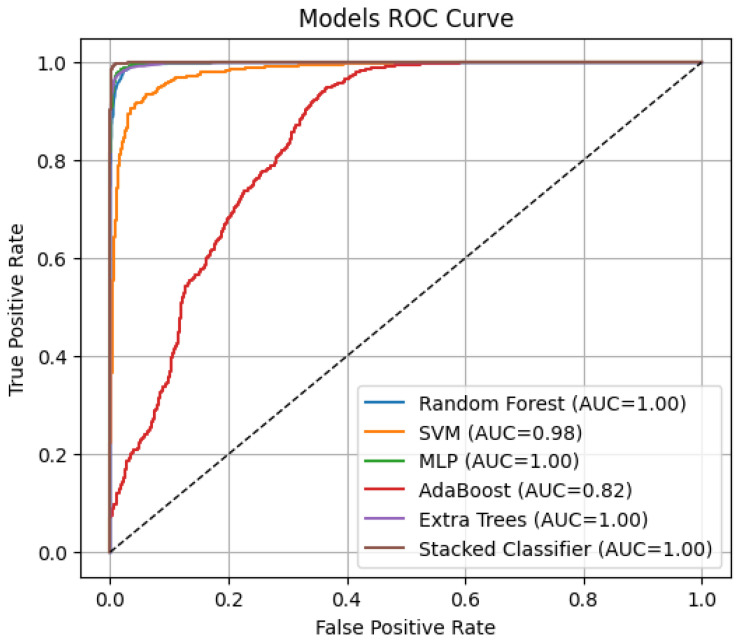
Convolutional autoencoder (CAE) was utilized to obtain high-level feature representations of histopathological images, followed by dimensionality reduction via Principal Component Analysis (PCA). Various models were utilized for classifying extracted features, i.e., Random Forest (RF), Support Vector Machine (SVM), Multi-Layer Perceptron (MLP), AdaBoost, and Extra Trees classifiers. A Gradient Boosting Machine (GBM) meta-classifier was utilized in an SEL approach to further fine-tune final predictions.
All the models were tested using accuracy, area under the curve (AUC), and Average Precision (AP) metrics. The stacked ensemble classifier performed better than all the individual models with a 99.04% accuracy, 0.9998 AUC, and 0.9996 AP, far exceeding what regular deep learning (DL) methods would achieve. Of standalone classifiers, MLP (97.71% accuracy, 0.9986 AUC, 0.9973 AP) and Random Forest (96.71% accuracy, 0.9977 AUC, 0.9953 AP) provided the best prediction performance, while AdaBoost was the poorest performer (68.25% accuracy, 0.8194 AUC, 0.6424 AP). PCA and t-SNE plots confirmed that DFE effectively enhances class discrimination.
This study demonstrates a highly accurate and reliable approach to lymphoma classification by using autoencoder-assisted ensemble learning, reducing the misclassification rate and significantly enhancing the accuracy of diagnosis. AI-based models are designed to assist pathologists by providing interpretable outputs such as class probabilities and visualizations (e.g., Grad-CAM), enabling them to understand and validate predictions in the diagnostic workflow. Future studies should enhance computational efficacy and conduct multi-centre validation studies to confirm the model's generalizability on extensive collections of histopathological datasets.
淋巴瘤癌症的准确亚型识别对于有效的诊断和治疗规划至关重要。尽管标准的深度学习算法已显示出稳健性,但它们仍然容易出现过拟合和泛化能力有限的问题,因此需要更可靠和稳健的方法。
本研究提出了一种自动编码器增强的堆叠集成学习(SEL)框架,该框架集成了深度特征提取(DFE)和机器学习分类器集成,以改进淋巴瘤亚型识别。
利用卷积自动编码器(CAE)获取组织病理学图像的高级特征表示,然后通过主成分分析(PCA)进行降维。使用各种模型对提取的特征进行分类,即随机森林(RF)、支持向量机(SVM)、多层感知器(MLP)、AdaBoost和极端随机树分类器。在SEL方法中使用梯度提升机(GBM)元分类器进一步微调最终预测。
所有模型均使用准确率、曲线下面积(AUC)和平均精度(AP)指标进行测试。堆叠集成分类器的表现优于所有单个模型,准确率为99.04%,AUC为0.9998,AP为0.9996,远远超过常规深度学习(DL)方法所能达到的水平。在独立分类器中,MLP(准确率97.71%,AUC为0.9986,AP为0.9973)和随机森林(准确率96.71%,AUC为0.9977,AP为0.9953)提供了最佳预测性能,而AdaBoost的表现最差(准确率68.25%,AUC为0.8194,AP为0.6424)。PCA和t-SNE图证实DFE有效地增强了类别区分。
本研究通过使用自动编码器辅助的集成学习展示了一种高度准确和可靠的淋巴瘤分类方法,降低了错误分类率并显著提高了诊断准确性。基于人工智能的模型旨在通过提供可解释的输出(如类别概率和可视化,例如Grad-CAM)来辅助病理学家,使他们能够在诊断工作流程中理解和验证预测。未来的研究应提高计算效率并进行多中心验证研究,以确认该模型在大量组织病理学数据集上的可推广性。