Chandrasekar Rajagopal Subramaniam, Kane Michael, Krishnamurti Lakshmanan
Section of Pediatric Hematology/Oncology/BMT, Yale School of Medicine, 2073 A, LMP Builidng 330 Cedar Streeet, New Haven, CT, United States, 1 412-612-4761.
School of Data Science and AI, Indian Institute of Technology, Madras, Chennai, India.
JMIR AI. 2025 Sep 15;4:e64519. doi: 10.2196/64519.
Disease-modifying therapies ameliorate disease severity of sickle cell disease (SCD), but hematopoietic cell transplantation (HCT), and more recently, autologous gene therapy are the only treatments that have curative potential for SCD. While registry-based studies provide population-level estimates, they do not address the uncertainty regarding individual outcomes of HCT. Computational machine learning (ML) has the potential to identify generalizable predictive patterns and quantify uncertainty in estimates, thereby improving clinical decision-making. There is no existing ML model for SCD, and ML models for HCT for other diseases focus on single outcomes rather than all relevant outcomes.
This study aims to address the existing knowledge gap by developing and validating an individualized ML prediction model SPRIGHT (Sickle Cell Predicting Outcomes of Hematopoietic Cell Transplantation), incorporating multiple relevant pre-HCT features to make predictions of key post-HCT clinical outcomes.
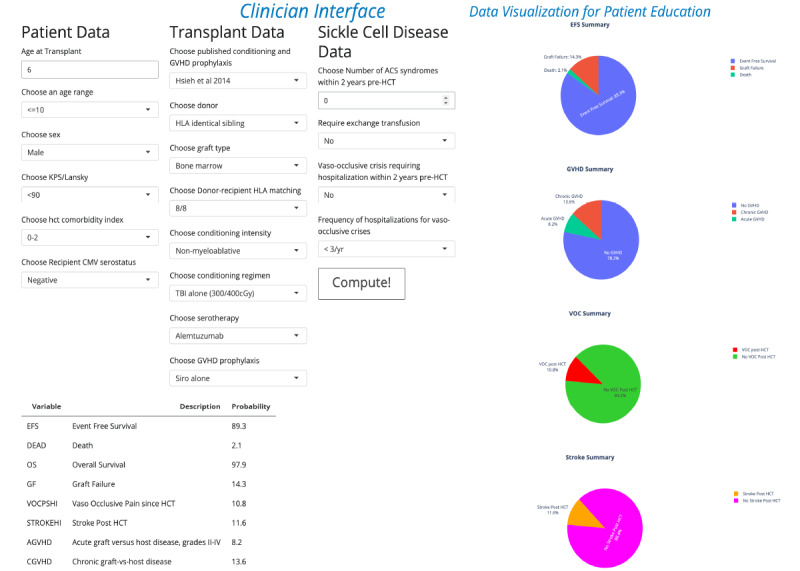
We applied a supervised random forest ML model to clinical parameters in a deidentified Center for International Blood and Marrow Transplant Research (CIBMTR) dataset of 1641 patients who underwent HCT between 1991 and 2021 and were followed for a median of 42.5 (IQR 52.5;range 0.3-312.9) months. We applied forward and reverse feature selection methods to optimize a set of predictive variables. To counter the imbalance bias toward predicting positive outcomes due to the small number of negative outcomes, we constructed a training dataset, taking each outcome as variable of interest, and performed 2-times repeated 10-fold cross-validation. SPRIGHT is a web-based individualized prediction tool accessible by smartphone, tablet, or personal computer. It incorporates predictive variables of age, age group, Karnofsky or Lansky score, comorbidity index, recipient cytomegalovirus seropositivity, history of acute chest syndrome, need for exchange transfusion, occurrence and frequency of vaso-occlusive crisis (VOC) before HCT, and either a published or custom chemotherapy or radiation conditioning, serotherapy, and graft-versus-host disease prophylaxis. SPRIGHT makes individualized predictions of overall survival (OS), event-free survival, graft failure, acute graft-versus-host disease (AGVHD), chronic graft-versus-host disease (CGVHD), and occurrence of VOC or stroke post-HCT.
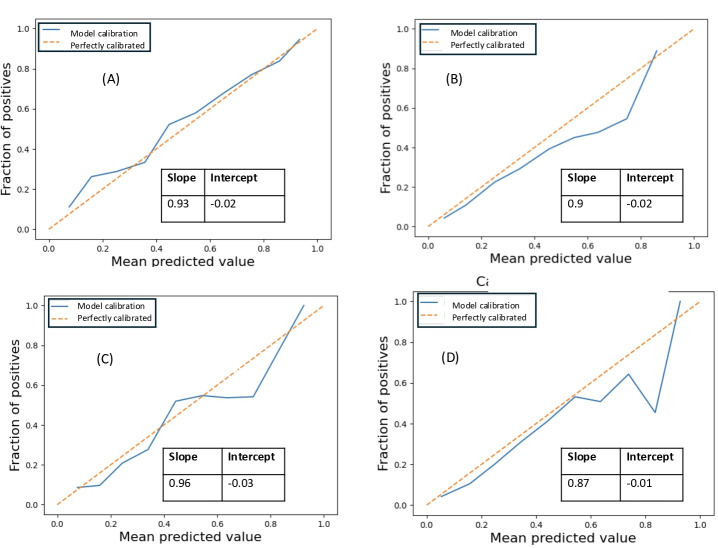
The model's ability to distinguish between positive and negative classes, that is, discrimination, was evaluated using the area under the curve, accuracy, and balanced accuracy. Discrimination met or exceeded published predictive benchmarks with area under the curve for OS (0.7925), event-free survival (0.7900), graft failure (0.8024), acute graft-versus-host disease (0.6793), chronic graft-versus-host disease (0.7320), and VOC post-HCT (0.8779). SPRIGHT revealed good calibration with a slope of 0.87-0.96, with small negative intercepts (-0.01 to 0.03), for 4 out of the 5 outcomes. However, OS exhibits nonideal calibration, which may be reflective of the overall high OS in all subgroups.
A web-based ML prediction tool incorporating multiple clinically relevant variables predicts key clinical outcomes with a high level of discrimination and calibration and has potential in shared decision-making.

疾病修饰疗法可改善镰状细胞病(SCD)的疾病严重程度,但造血细胞移植(HCT)以及最近的自体基因疗法是仅有的具有治愈SCD潜力的治疗方法。虽然基于登记处的研究提供了人群水平的估计,但它们并未解决HCT个体结果的不确定性问题。计算机器学习(ML)有潜力识别可推广的预测模式并量化估计中的不确定性,从而改善临床决策。目前尚无针对SCD的ML模型,而针对其他疾病的HCT的ML模型侧重于单一结果而非所有相关结果。
本研究旨在通过开发和验证个体化ML预测模型SPRIGHT(镰状细胞造血细胞移植结果预测模型)来填补现有知识空白,该模型纳入多个相关的HCT前特征以预测关键的HCT后临床结果。
我们将监督随机森林ML模型应用于国际血液和骨髓移植研究中心(CIBMTR)的一个去识别化数据集的临床参数,该数据集包含1641例在1991年至2021年间接受HCT且中位随访时间为42.5(四分位间距52.5;范围0.3 - 312.9)个月的患者。我们应用向前和向后特征选择方法来优化一组预测变量。为了应对由于阴性结果数量少而导致的预测阳性结果的不平衡偏差,我们构建了一个训练数据集,将每个结果作为感兴趣的变量,并进行2次重复的10折交叉验证。SPRIGHT是一个基于网络的个体化预测工具,可通过智能手机、平板电脑或个人计算机访问。它纳入了年龄、年龄组、卡诺夫斯基或兰斯基评分、合并症指数、受者巨细胞病毒血清学阳性、急性胸综合征病史、换血需求、HCT前血管闭塞性危机(VOC)发生情况及频率,以及已发表的或定制的化疗或放疗预处理、血清疗法和移植物抗宿主病预防等预测变量。SPRIGHT可对总生存期(OS)、无事件生存期、移植物失败、急性移植物抗宿主病(AGVHD)、慢性移植物抗宿主病(CGVHD)以及HCT后VOC或中风的发生情况进行个体化预测。
使用曲线下面积、准确性和平衡准确性评估了模型区分阳性和阴性类别的能力,即辨别力。辨别力达到或超过已发表的预测基准,OS的曲线下面积为0.7925,无事件生存期为0.7900,移植物失败为0.8024,急性移植物抗宿主病为0.6793,慢性移植物抗宿主病为0.7320,HCT后VOC为0.8779。SPRIGHT显示出良好的校准,5个结果中的4个结果的斜率为0.87 - 0.96,截距为小的负值(-0.01至0.03)。然而,OS表现出不理想的校准,这可能反映了所有亚组中总体较高的OS。
一个纳入多个临床相关变量的基于网络的ML预测工具能够以较高的辨别力和校准度预测关键临床结果,并在共同决策中具有潜力。