Lerat Emmanuelle, Ochman Howard
Department of Ecology and Evolutionary Biology, University of Arizona, Tucson, AZ 87521, USA.
Nucleic Acids Res. 2005 Jun 2;33(10):3125-32. doi: 10.1093/nar/gki631. Print 2005.
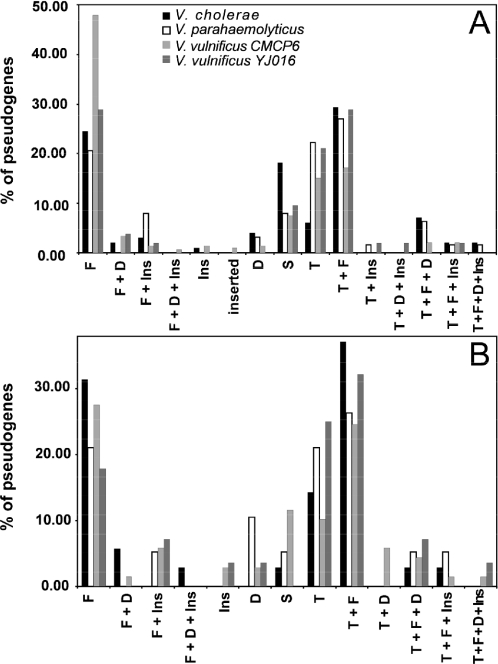
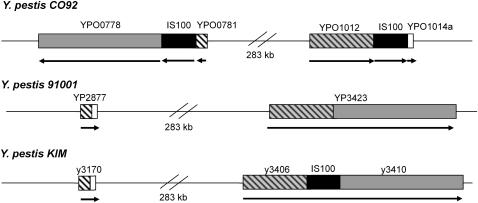
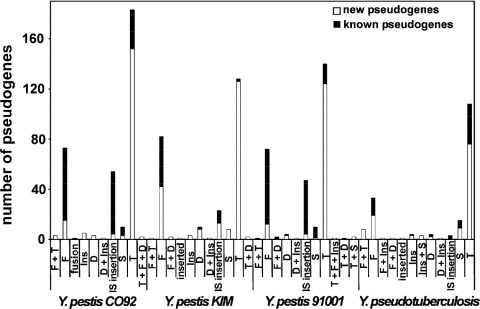
Pseudogenes are now known to be a regular feature of bacterial genomes and are found in particularly high numbers within the genomes of recently emerged bacterial pathogens. As most pseudogenes are recognized by sequence alignments, we use newly available genomic sequences to identify the pseudogenes in 11 genomes from 4 bacterial genera, each of which contains at least 1 human pathogen. The numbers of pseudogenes range from 27 in Staphylococcus aureus MW2 to 337 in Yersinia pestis CO92 (e.g. 1-8% of the annotated genes in the genome). Most pseudogenes are formed by small frameshifting indels, but because stop codons are A + T-rich, the two low-G + C Gram-positive taxa (Streptococcus and Staphylococcus) have relatively high fractions of pseudogenes generated by nonsense mutations when compared with more G + C-rich genomes. Over half of the pseudogenes are produced from genes whose original functions were annotated as 'hypothetical' or 'unknown'; however, several broadly distributed genes involved in nucleotide processing, repair or replication have become pseudogenes in one of the sequenced Vibrio vulnificus genomes. Although many of our comparisons involved closely related strains with broadly overlapping gene inventories, each genome contains a largely unique set of pseudogenes, suggesting that pseudogenes are formed and eliminated relatively rapidly from most bacterial genomes.
现在已知假基因是细菌基因组的一个常见特征,并且在最近出现的细菌病原体的基因组中数量特别多。由于大多数假基因是通过序列比对识别的,我们利用新获得的基因组序列来鉴定来自4个细菌属的11个基因组中的假基因,每个细菌属至少包含1种人类病原体。假基因的数量从金黄色葡萄球菌MW2中的27个到鼠疫耶尔森菌CO92中的337个不等(例如,占基因组中注释基因的1 - 8%)。大多数假基因是由小的移码插入缺失形成的,但是由于终止密码子富含A + T,与富含G + C的基因组相比,两个低G + C含量的革兰氏阳性类群(链球菌属和葡萄球菌属)中由无义突变产生的假基因比例相对较高。超过一半的假基因来自其原始功能被注释为“假设的”或“未知的”基因;然而,在创伤弧菌的一个测序基因组中,几个参与核苷酸加工、修复或复制的广泛分布的基因变成了假基因。尽管我们的许多比较涉及基因库广泛重叠的密切相关菌株,但每个基因组都包含一组在很大程度上独特的假基因,这表明假基因在大多数细菌基因组中形成和消除的速度相对较快。