Adzhubei Alexei A, Laerdahl Jon K, Vlasova Anna V
Norwegian School of Veterinary Science, BasAM-Genetics, PO Box 8146 Dep, NO-0033 Oslo, Norway.
BMC Bioinformatics. 2006 Jan 17;7:22. doi: 10.1186/1471-2105-7-22.
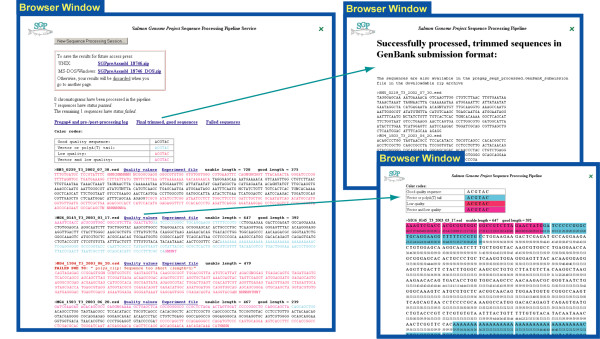
Trace or chromatogram files (raw data) are produced by automatic nucleic acid sequencing equipment or sequencers. Each file contains information which can be interpreted by specialised software to reveal the sequence (base calling). This is done by the sequencer proprietary software or publicly available programs. Depending on the size of a sequencing project the number of trace files can vary from just a few to thousands of files. Sequencing quality assessment on various criteria is important at the stage preceding clustering and contig assembly. Two major publicly available packages--Phred and Staden are used by preAssemble to perform sequence quality processing.
The preAssemble pre-assembly sequence processing pipeline has been developed for small to large scale automatic processing of DNA sequencer chromatogram (trace) data. The Staden Package Pregap4 module and base-calling program Phred are utilized in the pipeline, which produces detailed and self-explanatory output that can be displayed with a web browser. preAssemble can be used successfully with very little previous experience, however options for parameter tuning are provided for advanced users. preAssemble runs under UNIX and LINUX operating systems. It is available for downloading and will run as stand-alone software. It can also be accessed on the Norwegian Salmon Genome Project web site where preAssemble jobs can be run on the project server.
preAssemble is a tool allowing to perform quality assessment of sequences generated by automatic sequencing equipment. preAssemble is flexible since both interactive jobs on the preAssemble server and the stand alone downloadable version are available. Virtually no previous experience is necessary to run a default preAssemble job, on the other hand options for parameter tuning are provided. Consequently preAssemble can be used as efficiently for just several trace files as for large scale sequence processing.
痕量或色谱图文件(原始数据)由自动核酸测序设备或测序仪生成。每个文件都包含可由专门软件解释以揭示序列(碱基识别)的信息。这由测序仪的专有软件或公开可用的程序完成。根据测序项目的规模,痕量文件的数量可能从几个到数千个不等。在聚类和重叠群组装之前的阶段,根据各种标准进行测序质量评估很重要。预组装程序使用两个主要的公开可用软件包——Phred和Staden来进行序列质量处理。
已开发出预组装预装配序列处理流程,用于对DNA测序仪色谱图(痕量)数据进行从小规模到大规模的自动处理。该流程利用了Staden软件包的Pregap4模块和碱基识别程序Phred,生成的详细且自解释的输出可通过网络浏览器显示。几乎无需任何经验即可成功使用预组装程序,不过也为高级用户提供了参数调整选项。预组装程序在UNIX和LINUX操作系统下运行。它可供下载并将作为独立软件运行。也可以在挪威鲑鱼基因组计划网站上访问,在该网站上可以在项目服务器上运行预组装任务。
预组装程序是一种可对自动测序设备生成的序列进行质量评估的工具。预组装程序很灵活,因为既可以使用预组装服务器上的交互式任务,也可以使用独立的可下载版本。运行默认的预组装任务几乎无需任何经验,另一方面也提供了参数调整选项。因此,预组装程序对于几个痕量文件和大规模序列处理都能同样高效地使用。