McClintick Jeanette N, Edenberg Howard J
Department of Medical and Molecular Genetics, Indiana University, Indianapolis, Indiana, USA.
BMC Bioinformatics. 2006 Jan 31;7:49. doi: 10.1186/1471-2105-7-49.
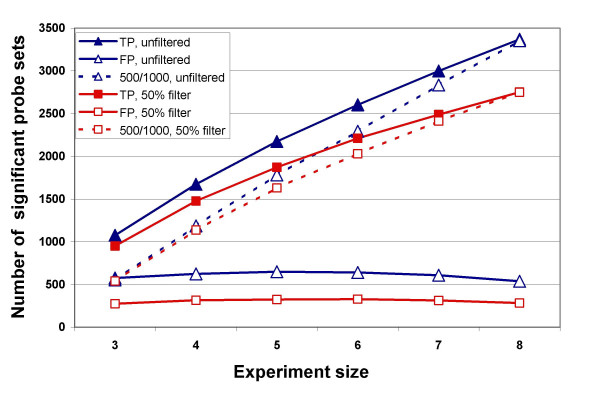
Affymetrix GeneChips are widely used for expression profiling of tens of thousands of genes. The large number of comparisons can lead to false positives. Various methods have been used to reduce false positives, but they have rarely been compared or quantitatively evaluated. Here we describe and evaluate a simple method that uses the detection (Present/Absent) call generated by the Affymetrix microarray suite version 5 software (MAS5) to remove data that is not reliably detected before further analysis, and compare this with filtering by expression level. We explore the effects of various thresholds for removing data in experiments of different size (from 3 to 10 arrays per treatment), as well as their relative power to detect significant differences in expression.
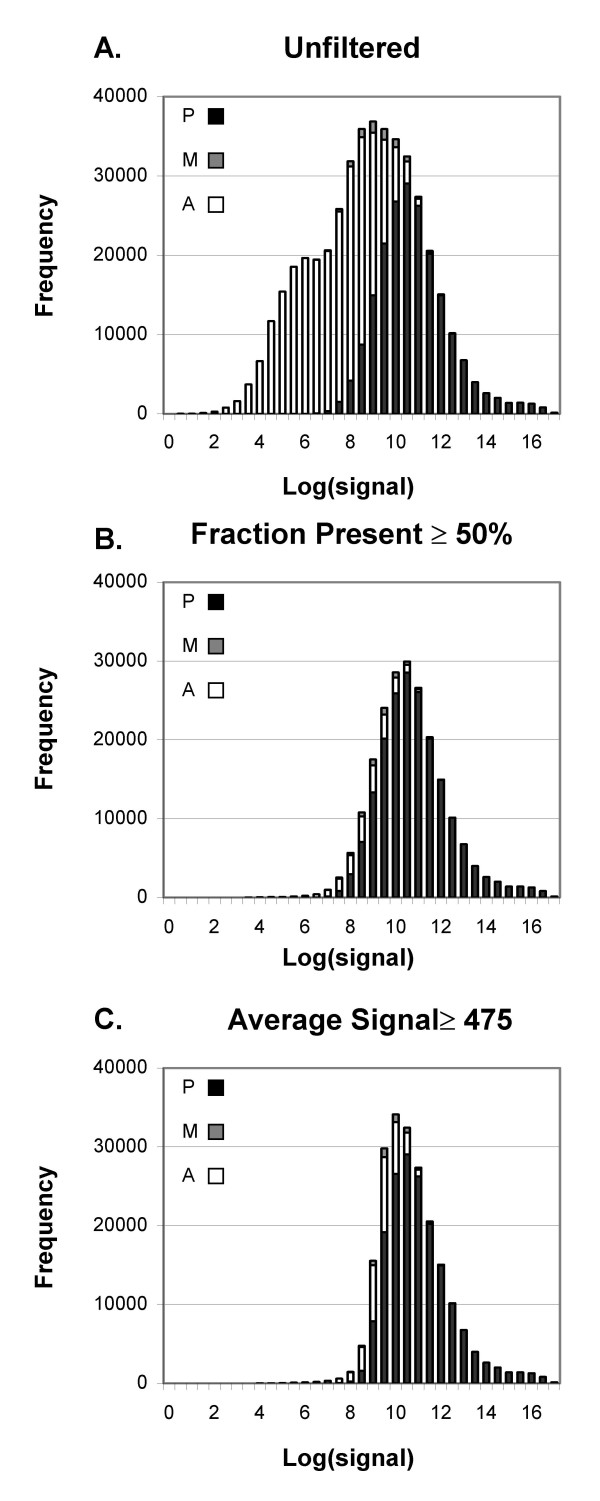
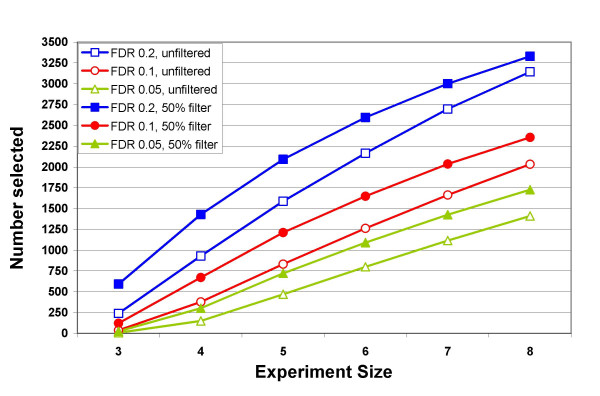
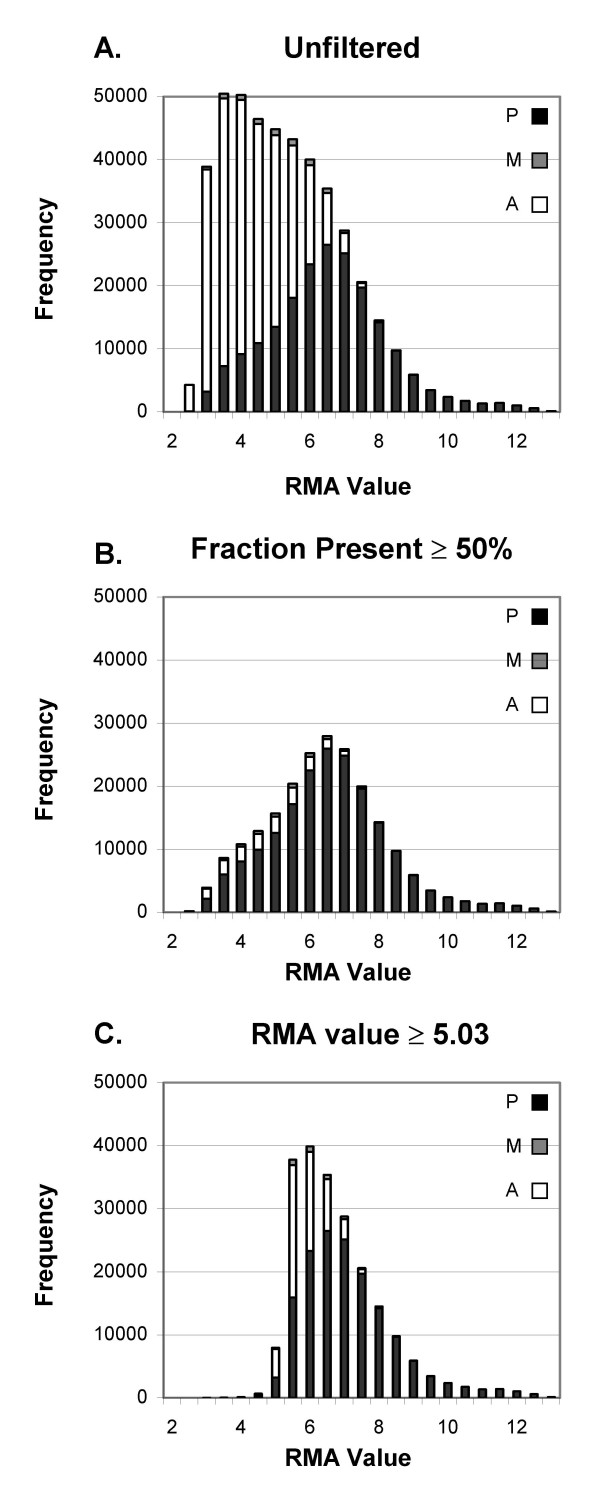
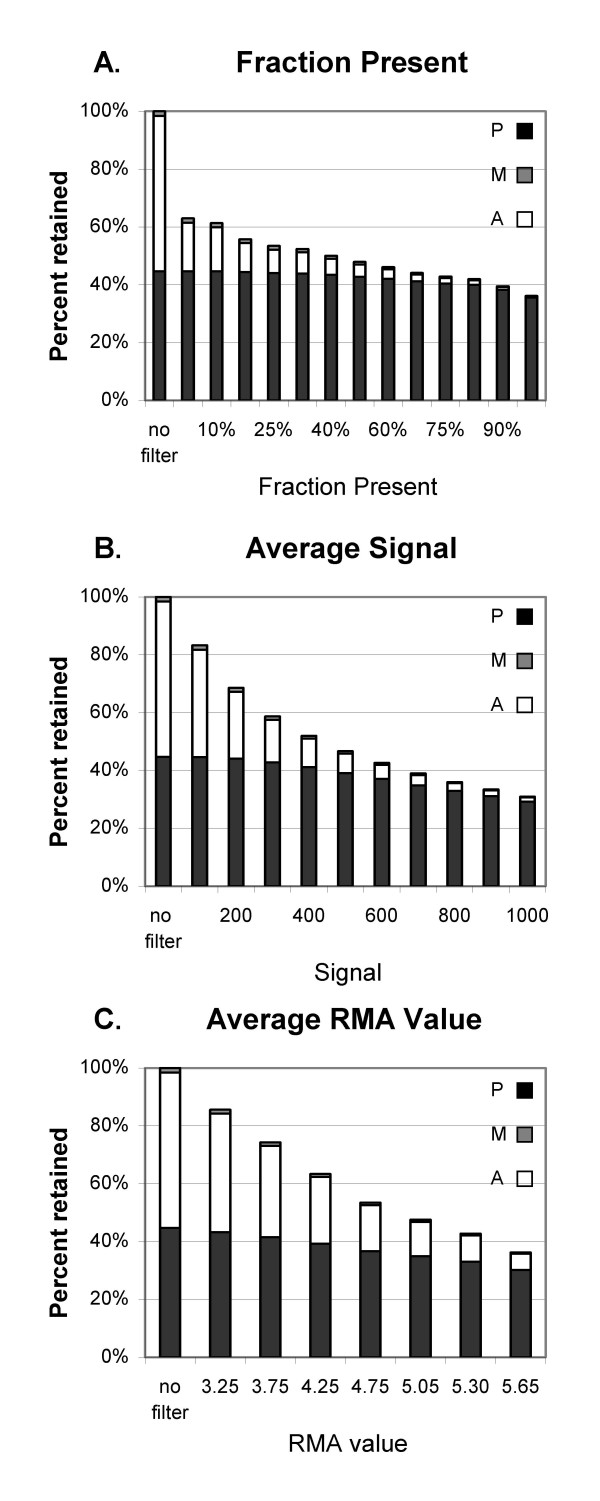
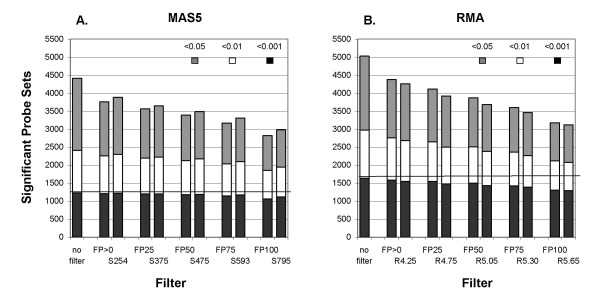
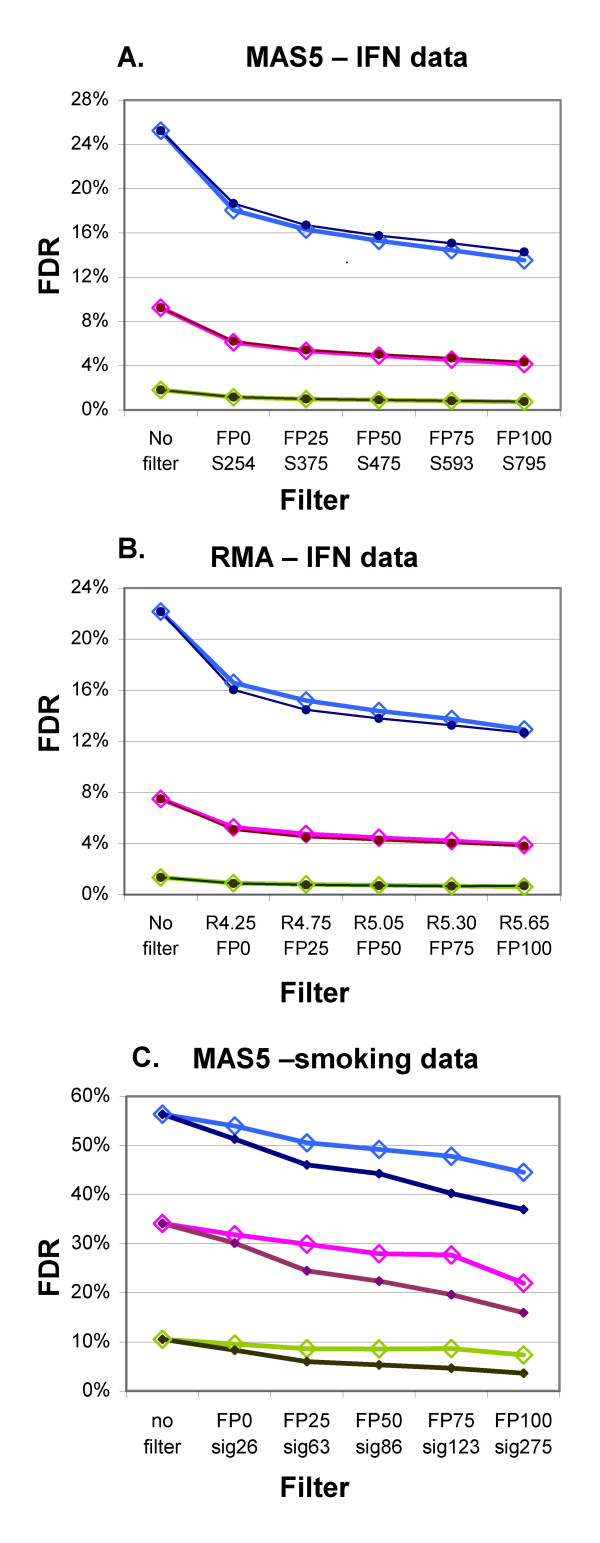
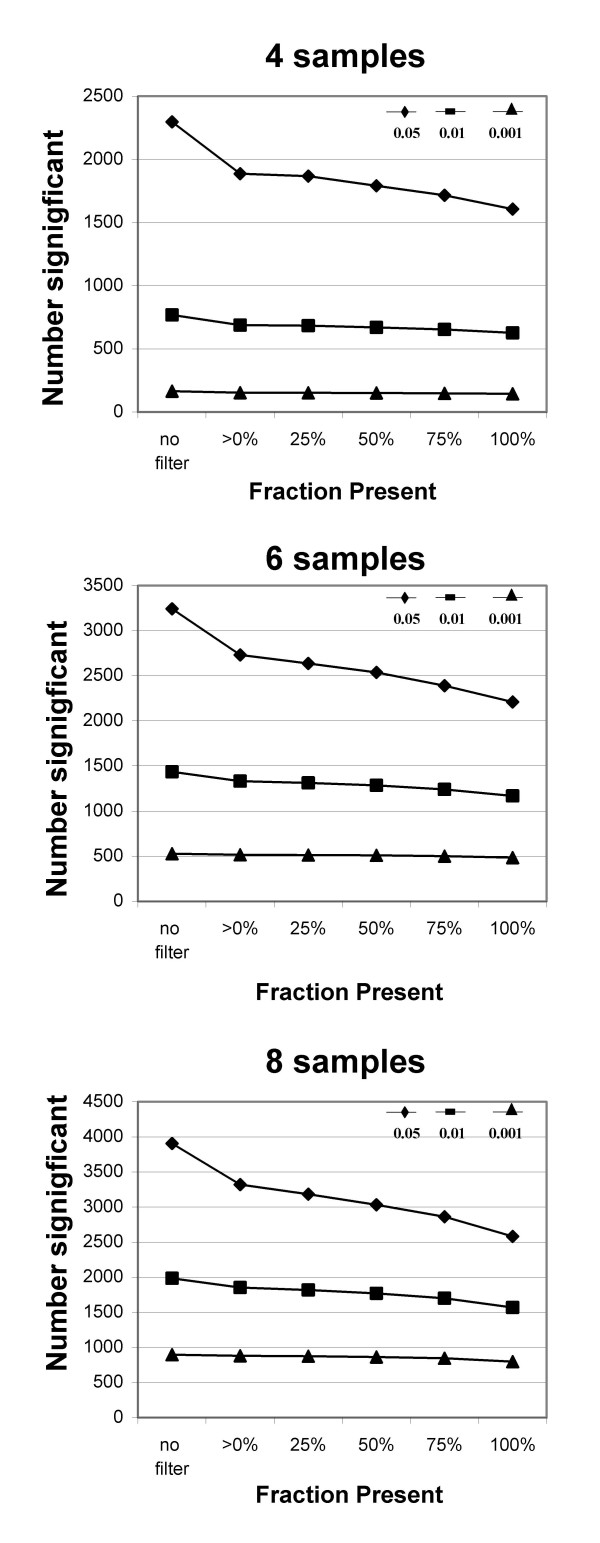
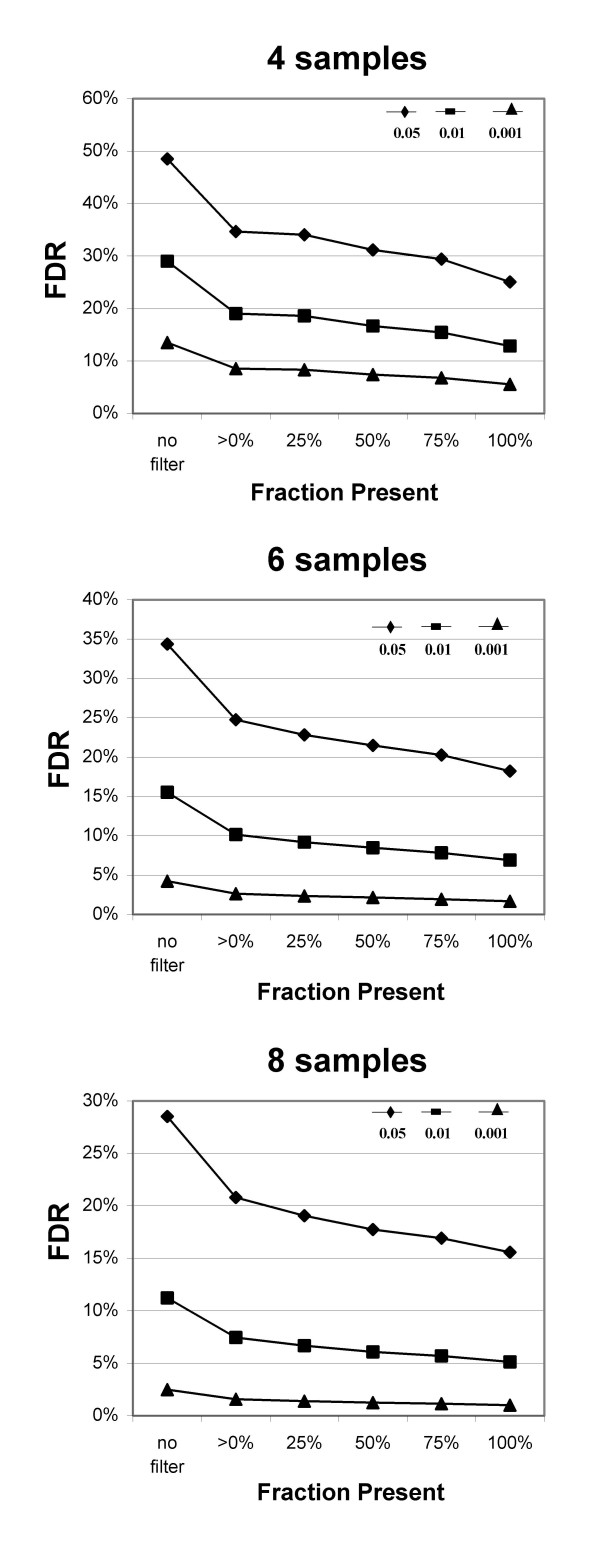
Our approach sets a threshold for the fraction of arrays called Present in at least one treatment group. This method removes a large percentage of probe sets called Absent before carrying out the comparisons, while retaining most of the probe sets called Present. It preferentially retains the more significant probe sets (p < or = 0.001) and those probe sets that are turned on or off, and improves the false discovery rate. Permutations to estimate false positives indicate that probe sets removed by the filter contribute a disproportionate number of false positives. Filtering by fraction Present is effective when applied to data generated either by the MAS5 algorithm or by other probe-level algorithms, for example RMA (robust multichip average). Experiment size greatly affects the ability to reproducibly detect significant differences, and also impacts the effect of filtering; smaller experiments (3-5 samples per treatment group) benefit from more restrictive filtering (> or =50% Present).
Use of a threshold fraction of Present detection calls (derived by MAS5) provided a simple method that effectively eliminated from analysis probe sets that are unlikely to be reliable while preserving the most significant probe sets and those turned on or off; it thereby increased the ratio of true positives to false positives.
Affymetrix基因芯片被广泛用于对数以万计基因的表达谱分析。大量的比较可能导致假阳性。已经使用了各种方法来减少假阳性,但它们很少被比较或定量评估。在这里,我们描述并评估一种简单的方法,该方法使用Affymetrix微阵列套件版本5软件(MAS5)生成的检测(存在/不存在)调用,在进一步分析之前去除未可靠检测到的数据,并将其与按表达水平进行的过滤进行比较。我们探讨了在不同规模的实验(每个处理3至10个阵列)中去除数据的各种阈值的影响,以及它们检测表达显著差异的相对能力。
我们的方法为至少一个处理组中被称为“存在”的阵列比例设置了一个阈值。该方法在进行比较之前去除了很大比例被称为“不存在”的探针集,同时保留了大多数被称为“存在”的探针集。它优先保留更显著的探针集(p≤0.001)以及那些开启或关闭的探针集,并提高了错误发现率。用于估计假阳性的排列表明,被过滤器去除的探针集贡献了不成比例数量的假阳性。按“存在”比例进行过滤在应用于由MAS5算法或其他探针水平算法(例如RMA,稳健多芯片平均)生成的数据时是有效的。实验规模极大地影响了可重复检测显著差异的能力,也影响了过滤效果;较小的实验(每个处理组3至5个样本)受益于更严格的过滤(≥50%“存在”)。
使用由MAS5得出的“存在”检测调用的阈值比例提供了一种简单的方法,该方法有效地从分析中消除了不太可能可靠的探针集,同时保留了最显著的探针集以及那些开启或关闭的探针集;从而提高了真阳性与假阳性的比例。