Nawrocki Eric P, Eddy Sean R
Howard Hughes Medical Institute, Janelia Farm Research Campus, Ashburn, Virginia, United States of America.
PLoS Comput Biol. 2007 Mar 30;3(3):e56. doi: 10.1371/journal.pcbi.0030056. Epub 2007 Feb 7.
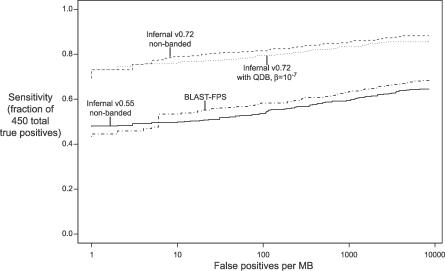
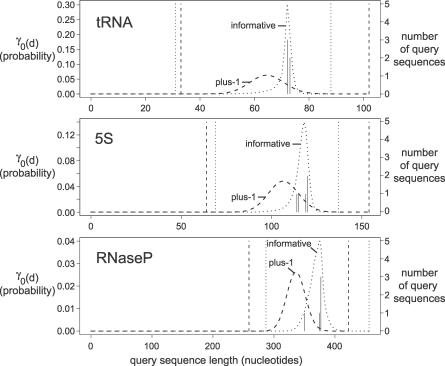
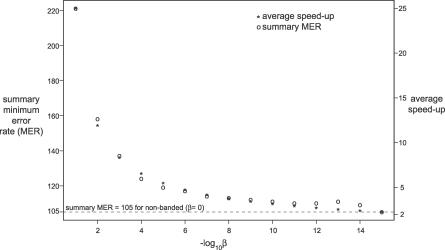
When searching sequence databases for RNAs, it is desirable to score both primary sequence and RNA secondary structure similarity. Covariance models (CMs) are probabilistic models well-suited for RNA similarity search applications. However, the computational complexity of CM dynamic programming alignment algorithms has limited their practical application. Here we describe an acceleration method called query-dependent banding (QDB), which uses the probabilistic query CM to precalculate regions of the dynamic programming lattice that have negligible probability, independently of the target database. We have implemented QDB in the freely available Infernal software package. QDB reduces the average case time complexity of CM alignment from LN(2.4) to LN(1.3) for a query RNA of N residues and a target database of L residues, resulting in a 4-fold speedup for typical RNA queries. Combined with other improvements to Infernal, including informative mixture Dirichlet priors on model parameters, benchmarks also show increased sensitivity and specificity resulting from improved parameterization.
在序列数据库中搜索RNA时,对一级序列和RNA二级结构相似性进行评分是很有必要的。协方差模型(CMs)是非常适合RNA相似性搜索应用的概率模型。然而,CM动态规划比对算法的计算复杂度限制了它们的实际应用。在这里,我们描述了一种称为查询依赖条带化(QDB)的加速方法,该方法使用概率查询CM预先计算动态规划网格中概率可忽略不计的区域,而与目标数据库无关。我们已在免费的Infernal软件包中实现了QDB。对于一个有N个残基的查询RNA和一个有L个残基的目标数据库,QDB将CM比对的平均情况时间复杂度从LN(2.4)降低到LN(1.3),这使得典型RNA查询的速度提高了4倍。结合对Infernal的其他改进,包括对模型参数使用信息性混合狄利克雷先验,基准测试还表明,改进的参数化提高了敏感性和特异性。